Comments 45
я ежедневно работаю с MongoDb и Redis(через редиску)
Было бы интересно читать материалы на эту тему.
Было бы интересно читать материалы на эту тему.
Я думаю, с ежедневной работой вы и сами можете поделиться опытом :).
ну если кто то начнет дискуссию я мог бы=))
начинаю!
кто пробовал Django + MongoDB?
кто пробовал Django + MongoDB?
я не пробовал, но думаю что особой разницы нету.
Я пробовал RoR + MongoDB, когда она еще падала. Теперь сидим на CouchDb и ничего нам пока* больше не нужно.
Пробовал с хранилищем гугловским (используется один форк Django-nonrel). Главный минус (для меня) — не работает join и many-to-many. То есть для большинства приложений тупо заменить БД не получится
я пробовал и очень успешно.
для front-end'а, скажем так, вполне достаточно pymongo
для «админки», а точнее удобной работы по добавлению/обновлению и т.д. рекомендую mongokit
для front-end'а, скажем так, вполне достаточно pymongo
для «админки», а точнее удобной работы по добавлению/обновлению и т.д. рекомендую mongokit
а как со стабильностью?
как с основными плюшками админки с монгокитом?
где почитать саксесс стори?
как с основными плюшками админки с монгокитом?
где почитать саксесс стори?
>а как со стабильностью?
со стабильностью проблем не было, да и нагрузок не было т.к. в локалке компании (CRM-система) и пользуется не много народу.
под «админкой» я имею ввиду часть сайта где требуется работа по изменению данных, в этом случае удобно работать с записями как с моделями, со своей схемой, для валидации, с интерфейсами, что и дает mongokit.
>как с основными плюшками админки с монгокитом?
непосредственно модулем админки джанги я мало пользовался, а для nosql он вроде до сих пор не портирован, хотя я видел проскакивали новости по переводу джанги на nosql.
>где почитать саксесс стори?
давно специально не искал, но на момент моей работы с этой связкой (месяца 4 назад) с документацией было очень плохо, не говоря уже про статьи, кроме оф. документации к pymongo и mongokit ничем не пользовался, там достаточно просто.
со стабильностью проблем не было, да и нагрузок не было т.к. в локалке компании (CRM-система) и пользуется не много народу.
под «админкой» я имею ввиду часть сайта где требуется работа по изменению данных, в этом случае удобно работать с записями как с моделями, со своей схемой, для валидации, с интерфейсами, что и дает mongokit.
>как с основными плюшками админки с монгокитом?
непосредственно модулем админки джанги я мало пользовался, а для nosql он вроде до сих пор не портирован, хотя я видел проскакивали новости по переводу джанги на nosql.
>где почитать саксесс стори?
давно специально не искал, но на момент моей работы с этой связкой (месяца 4 назад) с документацией было очень плохо, не говоря уже про статьи, кроме оф. документации к pymongo и mongokit ничем не пользовался, там достаточно просто.
Я б перенес, но боюсь, что Cache не подходит под этот блог :)
— Так у нас проблемы с производительностью, надо добавить кэширование, вертикальное партиционирование и NoSQL DB для логинов.
— Парни — я тут посмотрел EXPLAIN — у Вас fullscan запрос на 4,000 строк, я попробовал создать индекс — все ускорилось в 26 раз.
via
Автор забыл упомянуть в тегах RavenDB.
{kind=link}
Только сегодня с нашим админом sql 2000 обсуждали тему nosql.
Очень хотелось бы почитать статьи…
Сами занимается автоматизацией и учетом ж/д перевозок на очень большом предприятии.
Очень хотелось бы почитать статьи…
Сами занимается автоматизацией и учетом ж/д перевозок на очень большом предприятии.
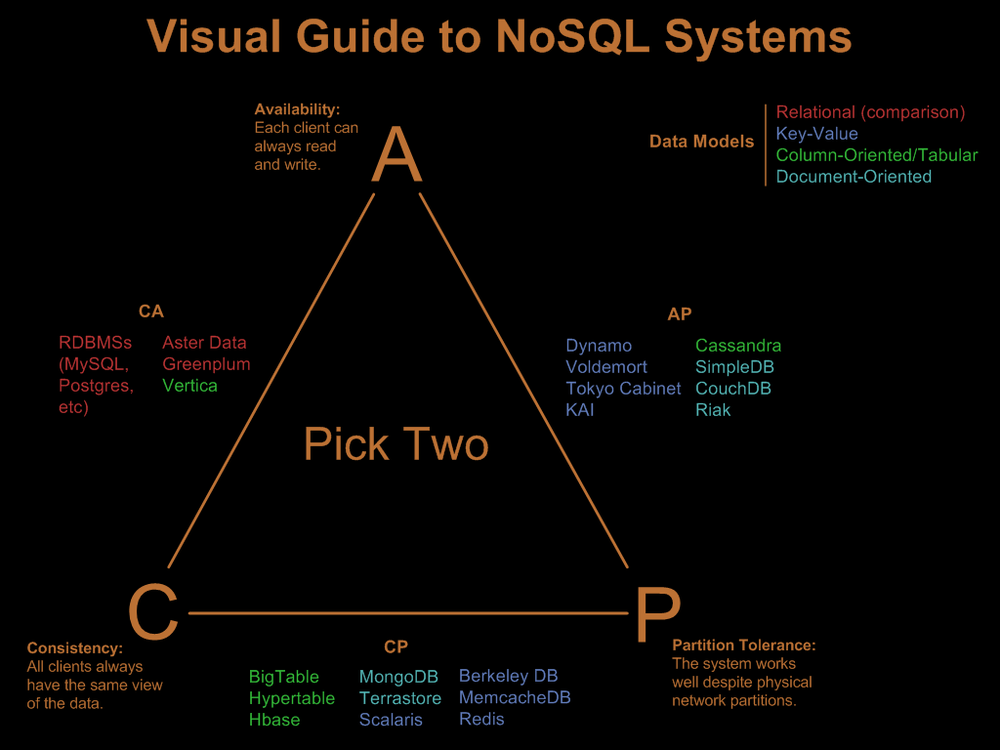
Хотелось бы увидеть сравнение (ключевые отличия друг от друга) «MongoDB, CouchDB, Cassandra, Redis, Cache — все, что угодно» между собой. Сейчас вот начал изучать MongoDB, но выбрал её среди других NoSQL, лишь потому что, как говорится, «на слуху» название.
Это все весьма разные штуки. Как-то можно сравнить между собой mongo и couch, cassandra и riak, всякие базы графов. А по сути важен вопрос — какой тип данных предполагается? Ведь вполне может оказаться, что вам mysql прям очень в тему ;-)
Для прототипирования я бы взял mongo — самое простое и функциональное в то же время. Для важных данных я бы монго не выбрал. Так что если вам что-то серьезное хранить — это не ваш выбор.
Для прототипирования я бы взял mongo — самое простое и функциональное в то же время. Для важных данных я бы монго не выбрал. Так что если вам что-то серьезное хранить — это не ваш выбор.
Ну я особо не в теме, только начал изучать нереляционные СУБД (читай — NoSQL), противопоставление mongo и couch как-то встречается, я и подумал что все они одного поля ягоды :)
MySQL точно не в тему, предполагается большое количество объектов с заранее неописанной структурой, общее у них только id, name, description, author и т. п. То есть в случае SQL сразу надо создавать таблицу атрибутов объектов, определять их тип, и, если он не элементарный (ссылка на другие объекты или их списки), производить рекурсивные запросы, да ещё и в цикле в случае списков. Реализовывать это чисто на SQL мне кажется неразумным даже пытаться (если вообще это возможно), устраивать спагетти из SQL и «главного» ЯП не хочется, не говоря о том, что быстродействие всего этого внушает серьёзные опасения.
Но данные как бы важные, юзерам не понравится, если их усилия по заполнению анкеты или написанию поста в блог пропадут :)
MySQL точно не в тему, предполагается большое количество объектов с заранее неописанной структурой, общее у них только id, name, description, author и т. п. То есть в случае SQL сразу надо создавать таблицу атрибутов объектов, определять их тип, и, если он не элементарный (ссылка на другие объекты или их списки), производить рекурсивные запросы, да ещё и в цикле в случае списков. Реализовывать это чисто на SQL мне кажется неразумным даже пытаться (если вообще это возможно), устраивать спагетти из SQL и «главного» ЯП не хочется, не говоря о том, что быстродействие всего этого внушает серьёзные опасения.
Но данные как бы важные, юзерам не понравится, если их усилия по заполнению анкеты или написанию поста в блог пропадут :)
MySQL точно не в тему, предполагается большое количество объектов с заранее неописанной структурой, общее у них только id, name, description, author и т. п.
Да, это имхо сразу исключает использование РБД: либо замучаетесь с обновлением структуры базы, либо придется создавать кучу избыточных колонок.
Судя по комменту, ссылка на который приведена ниже, стоит попробовать CouchDB.
Вот здесь был очень хороший комментарий.
Мы выбрали CouchDb за то что она работает по протоколу Json (простота интеграции с базой, не требующая обязательного использования доп. библиотек)
Мы выбрали CouchDb за то что она работает по протоколу Json (простота интеграции с базой, не требующая обязательного использования доп. библиотек)
Я сравнивал, но в основном для себя, просто попробовать.
Сам нашёл habrahabr.ru/blogs/nosql/77909/ :)
интересно было бы узнать об опыте использования и про отзывы
Sign up to leave a comment.
Точка сбора NoSQL