Здравствуйте!
В этой статье, как и, надеюсь, в последующих, я хочу рассказать об одной из современных структурированных пиринговых сетей. Данный материал включает в себя мою переработку документаций, описаний и статей, найденных по теме. В качестве введения представлена общая краткая теория p2p-сетей, DHT, а уж затем следует основная часть, которой посвящена заметка.
Распределение данных, процессорного времени и других ресурсов между пользователями заставляют искать решения организации сетей разного уровня и взаимодействия.
На смену клиент-серверному взаимодействую приходят сети p2p (point-to-point), чтобы предоставить больший уровень масштабируемости, автономности, анонимности, отказоустойчивости.
Далее будет приведена общая классификация.
По степени централизации можно выделить следующие типы p2p сетей:
Минусы сети этого типа:
Гибридные — Сети, которые содержат два типа узлов: общего назначения и супер-узлы (Super Peer). Последние назначаются динамически в зависимости от определенных условий и позволяют управлять маршрутизацией и индексацией данных в сети.
Минусы и плюсы зависят от степени «гибридности» — какие характеристики она наследует от централизованных, а какие от децентрализованных (о которых речь пойдет далее).
Децентрализованные — Данный тип сетей подразумевает полное отсутствие серверов. Таким образом, исключается узкое место из сети.
Минусы:
Децентрализованные сети можно разделить на структурированные и неструктурированные. В первом случае, топология сети строится по определенным правилам, позволяющим организовывать быстрый поиск данных, однако, увы, только по точному совпадению. Каждый узел, фактически, ответственен за свою область данных (как выделяются такие области, их вид, устройство таблиц маршрутизации — все это зависит уже от конкретной топологии сети). В неструктурированных сетях заранее неизвестно, куда можно отправить запрос, поэтому в самом простом варианте используется вариант flood-запросов: узел рассылает запрос соседям, те своим и т.п.). Важно, что для таких запросов определен TTL (Time To Live), позволяющий отсекать их после определенного количества скачков по сети. Очевидно, что при низком TTL сеть будет выдавать ложные результаты поиска (не достигая некоторых источников), а при высоком — время на запросы, да и количество трафика могут непозволительно возрасти. Однако, в отличии от структурированных сетей, возможен поиск не только по точным совпадениям, что немаловажно для файлообменных систем. Масштабируемость неструктурированных сетей если не отсутствует, то весьма проблематична (наличие TTL и растущее время поиска данных).
При проектировании топологии и протоколов структурированных сетей оптимальным считается выполнение соотношений:
— Размер таблицы маршрутизации на каждом узле: O(log(n))
— Сложность поиска: O(log(n))
DHT (Distributed Hash Table) — распределенная хэш-таблица. Данная структура зачастую используется для децентрализованных топологий. Однако, это не единственный выбор (как подсказывает литература, впрочем, здесь лучше заняться дальнейшим самостоятельным поиском).
Для каждого значения (данных) на каждом узле вычисляется по определенным правилам хэш (например, с помощью SHA-1), который становится ключом. Также, вычисляется идентификатор узла (той же длины, что и хэш, а зачастую, той же функцией). Таким образом, каждый узел сети обладает своим идентификатором. Ключи публикуются в сети. Узел несет ответственность за ключи таблицы, которые близки к нему по определенной метрике (т.е. расстоянию), здесь подразумевается «похожесть» ключа на идентификатор, если опустить язык математики. Благодаря этому, каждый узел занимает свою зону ответственности при хранении ключей и связанных с ней информации (координаты узла, на котором расположено значение). Это позволяет определенным образом организовать алгоритм поиска по точным значениям (сначала вычислить ключ значения для поиска, например, имени файла, а затем искать этот ключ, направляя запросы к узлу, ответственному за него через посредников, предоставляющих полный путь).
DHT в полной степени обеспечивает отказоустойчивость и масштабируемость. В сочетании с Peer Exchange, например, DHT позволяет перехватить функции Torrent-трекера.
Создателями данной топологии являются Petar Maymounkov и David Mazières. В основе работы протокола и построения таблиц лежит определения расстояния между узлами через XOR-метрику:
d(x, y) = x XOR y. Важно отметить, что расстоянием является результат операции XOR, интерпретируемый, как число, а не количество различающихся бит (такой критерий тоже может порождать метрику в пространстве ключей/идентификаторов). Т.е. при длине ключа 4 бита: d(2,5) = 0010 XOR 0101 = 0111 = 7.
XOR метрика удовлетворяет всем аксиомам метрики:
Данное свойство отмечают в связи с возможностью формального доказательства тезисов о размерах таблиц маршрутизации и сложности поиска. (Справедливости ради, предоставляемого в виде наброска).
На вычислении расстояний между узлами (посредством применения метрики к их идентификаторам) базируется алгоритм построения таблиц маршрутизации.
Каждый i-ый столбец таблицы ответственен за хранение информации об узлах на расстоянии от 2^(i+1) до 2^i. Таким образом, последний столбец для узла 0111 может содержать информацию о любых узлах 1xxx, предпоследний об узлах 00xx, еще на уровень ближе — об узлах 010x.
Конечно, в реальной сети, применяется обычно длина ключа в 128, либо в 160 бит. Зависит от реализации.
Далее, вводится ограничение на число хранимых узлов на каждом уровне, K. Поэтому столбцы таблицы, ограниченные таким K, называют K-buckets (к сожалению, русский эквивалент, звучит совсем неблагозвучно).
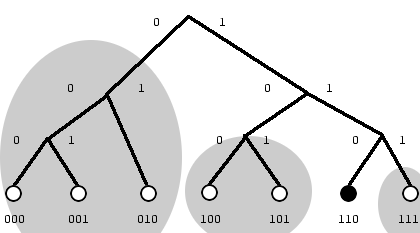
Если рассмотреть бинарное дерево поиска, в листах которого лежат идентификаторы узлов, становится понятно, что такая структура K-buckets не случайна: каждый узел (а на примере 110) получает знания хотя бы об одном участнике каждого поддерева (для 110 выделенных залитыми овалами). Таким образом, каждый K-bucket отражает связь узла с не более, чем K участниками поддерева на уровне i.
Протокол Kademlia содержит 4 типа сообщений:
PING нужен для проверки существования конкретного узла в сети. Например, он применяется при попытке добавления узла в K-bucket, когда тот уже заполнен: опрашиваются существующие узлы, если нет ответа, то узел вставляется. Стоит отметить, что более старые узлы находятся внизу K-bucket, это основывается на экспериментальных данных, говорящих о том, что чем дольше узел остается в сети, тем меньше вероятности, что он ее покинет. Поэтому они будут опрошены только после более новых.
STORE запрос, позволяющий разместить информацию на заданном узле. Перед выполнением STORE узел должен найти K ближайших к ключу значения, которое он собирается опубликовать, а лишь потом отправить каждому STORE с ключом и своими координатами. Хранение сразу на K узлах позволяет повысить доступность информации.
FIND_VALUE запрос, который, зачастую, повторяется для образования итерации, позволяющий найти значение по ключу. Реализует поиск значения в сети. Возвращает либо K ближайших узлов, либо само значение, в зависимости от достижения узла, хранящего искомые данные. Итерации прекращают как раз либо при возвращении значения (успех), либо при возврате уже опрошенных K узлов (значения нет в сети).
FIND_NODE запрос, используемый для поиска ближайших K к заданному идентификатору (поведение сходно с FIND_VALUE, только никогда не возвращает значение, всегда узлы!). Используется, например, при присоединении узла к сети по следующей схеме:
— Контакт с bootstrap узлом
— Посылка запроса FIND_NODE со своим идентификатором к bs узлу, дальнейшая итеративная рассылка
— Обновление K-buckets (при этом обновляются как K-buckets нового узла, так и всех, мимо которых проходил запрос (здесь на руку симметричность метрики XOR))
Как видно, протокол в своей спецификации практически не покрывает вопросы безопасности, что нашло отражение в исследованиях и работах по атаке Kademlia-based сетей.
Из особенностей стоит подчеркнуть наличие репликации, времени жизни значения (необходимость повторного размещения через определенный промежуток времени), параллелизм при посылке запросов FIND_*, дабы достигнуть нужных узлов за более короткое время (обозначается α, в реализациях обычно равно 3). При каждом прохождении запросов происходит попытка обновить K-bucket, что позволяет держать таблицы маршрутизации максимально оптимальными.
Прежде всего, самой известной сетью, базирующейся на Kademlia является Kad Network, доступная в aMule/eMule. Для bootstrap используются существующие узлы в eDonkey.
Khashmir — Kademlia-реализация на Python, использующаяся в BitTorrent
Из ныне развивающихся и активных библиотек я бы еще отметил
maidsafe-dht — C++ реализация инфраструктуры с поддержкой UDT и NAT Traversal.
Mojito — Java библиотека от LimeWire.
Хотел бы получить комментарии о том, во что следует углубиться подробнее, т.к. статья носит чрезвычайно поверхностный характер. Дабы пробудить интерес, а не выложить все карты разом на стол. Сам планирую в следующей заметке о Kademlia рассказать о проблемах безопасности, атаках и их предотвращении.
В этой статье, как и, надеюсь, в последующих, я хочу рассказать об одной из современных структурированных пиринговых сетей. Данный материал включает в себя мою переработку документаций, описаний и статей, найденных по теме. В качестве введения представлена общая краткая теория p2p-сетей, DHT, а уж затем следует основная часть, которой посвящена заметка.
1. Общая теория p2p
Распределение данных, процессорного времени и других ресурсов между пользователями заставляют искать решения организации сетей разного уровня и взаимодействия.
На смену клиент-серверному взаимодействую приходят сети p2p (point-to-point), чтобы предоставить больший уровень масштабируемости, автономности, анонимности, отказоустойчивости.
Далее будет приведена общая классификация.
По степени централизации можно выделить следующие типы p2p сетей:
- Централизованные
- Гибридные
- Полностью децентрализованные
Минусы сети этого типа:
- Сервер представляет узкое место сети. Отказ приводит к полной потере работоспособности системы.
- Законодательная уязвимость сервера
- При значительном росте популяции сети сервер подвергнется своего рода DDoS атаке, приводящей к его отказу.
- Весь процесс от поиска до получения файла проходит по максимально короткой схеме: поисковый запрос к серверу, выдача результатов от сервера, соединение с нужным узлом.
При этом вполне возможен поиск не только по точным совпадениям, что немаловажно, как будет показано далее.
Гибридные — Сети, которые содержат два типа узлов: общего назначения и супер-узлы (Super Peer). Последние назначаются динамически в зависимости от определенных условий и позволяют управлять маршрутизацией и индексацией данных в сети.
Минусы и плюсы зависят от степени «гибридности» — какие характеристики она наследует от централизованных, а какие от децентрализованных (о которых речь пойдет далее).
Децентрализованные — Данный тип сетей подразумевает полное отсутствие серверов. Таким образом, исключается узкое место из сети.
Минусы:
- Необходимы определенные алгоритмы маршрутизации и поиска, порою не гарантирующие достоверности результата.
- Для включения в такую сеть нужно знать координаты хотя бы одного узла, следовательно, списки с определенным количеством адресных данных участников сети необходимо публиковать в общедоступных источниках (например, на сайтах). Сам процесс подклчючения подразумевает стадию начальной загрузки/инициализации (bootstrap), поэтому такие списки еще называются bootstrap-листами.
- Исключение сервера позволяет сети быть отказоустойчивой, даже при быстро растущем/падающем количестве участников.
- Большая степень защищенности от цензуры
Децентрализованные сети можно разделить на структурированные и неструктурированные. В первом случае, топология сети строится по определенным правилам, позволяющим организовывать быстрый поиск данных, однако, увы, только по точному совпадению. Каждый узел, фактически, ответственен за свою область данных (как выделяются такие области, их вид, устройство таблиц маршрутизации — все это зависит уже от конкретной топологии сети). В неструктурированных сетях заранее неизвестно, куда можно отправить запрос, поэтому в самом простом варианте используется вариант flood-запросов: узел рассылает запрос соседям, те своим и т.п.). Важно, что для таких запросов определен TTL (Time To Live), позволяющий отсекать их после определенного количества скачков по сети. Очевидно, что при низком TTL сеть будет выдавать ложные результаты поиска (не достигая некоторых источников), а при высоком — время на запросы, да и количество трафика могут непозволительно возрасти. Однако, в отличии от структурированных сетей, возможен поиск не только по точным совпадениям, что немаловажно для файлообменных систем. Масштабируемость неструктурированных сетей если не отсутствует, то весьма проблематична (наличие TTL и растущее время поиска данных).
При проектировании топологии и протоколов структурированных сетей оптимальным считается выполнение соотношений:
— Размер таблицы маршрутизации на каждом узле: O(log(n))
— Сложность поиска: O(log(n))
2. DHT
DHT (Distributed Hash Table) — распределенная хэш-таблица. Данная структура зачастую используется для децентрализованных топологий. Однако, это не единственный выбор (как подсказывает литература, впрочем, здесь лучше заняться дальнейшим самостоятельным поиском).
Для каждого значения (данных) на каждом узле вычисляется по определенным правилам хэш (например, с помощью SHA-1), который становится ключом. Также, вычисляется идентификатор узла (той же длины, что и хэш, а зачастую, той же функцией). Таким образом, каждый узел сети обладает своим идентификатором. Ключи публикуются в сети. Узел несет ответственность за ключи таблицы, которые близки к нему по определенной метрике (т.е. расстоянию), здесь подразумевается «похожесть» ключа на идентификатор, если опустить язык математики. Благодаря этому, каждый узел занимает свою зону ответственности при хранении ключей и связанных с ней информации (координаты узла, на котором расположено значение). Это позволяет определенным образом организовать алгоритм поиска по точным значениям (сначала вычислить ключ значения для поиска, например, имени файла, а затем искать этот ключ, направляя запросы к узлу, ответственному за него через посредников, предоставляющих полный путь).
DHT в полной степени обеспечивает отказоустойчивость и масштабируемость. В сочетании с Peer Exchange, например, DHT позволяет перехватить функции Torrent-трекера.
3. Kademlia
Метрика
Создателями данной топологии являются Petar Maymounkov и David Mazières. В основе работы протокола и построения таблиц лежит определения расстояния между узлами через XOR-метрику:
d(x, y) = x XOR y. Важно отметить, что расстоянием является результат операции XOR, интерпретируемый, как число, а не количество различающихся бит (такой критерий тоже может порождать метрику в пространстве ключей/идентификаторов). Т.е. при длине ключа 4 бита: d(2,5) = 0010 XOR 0101 = 0111 = 7.
XOR метрика удовлетворяет всем аксиомам метрики:
- d(x, y) >= 0 // Неотрицательность
- d(x, y) == 0 <=> x == y
- d(x, y) = d(y, x) // Симметричность
- d(x, y) <= d(x, z) + d(z, y) // Неравенство треугольника
Данное свойство отмечают в связи с возможностью формального доказательства тезисов о размерах таблиц маршрутизации и сложности поиска. (Справедливости ради, предоставляемого в виде наброска).
Таблица маршрутизации
На вычислении расстояний между узлами (посредством применения метрики к их идентификаторам) базируется алгоритм построения таблиц маршрутизации.
Каждый i-ый столбец таблицы ответственен за хранение информации об узлах на расстоянии от 2^(i+1) до 2^i. Таким образом, последний столбец для узла 0111 может содержать информацию о любых узлах 1xxx, предпоследний об узлах 00xx, еще на уровень ближе — об узлах 010x.
Конечно, в реальной сети, применяется обычно длина ключа в 128, либо в 160 бит. Зависит от реализации.
Далее, вводится ограничение на число хранимых узлов на каждом уровне, K. Поэтому столбцы таблицы, ограниченные таким K, называют K-buckets (к сожалению, русский эквивалент, звучит совсем неблагозвучно).
Если рассмотреть бинарное дерево поиска, в листах которого лежат идентификаторы узлов, становится понятно, что такая структура K-buckets не случайна: каждый узел (а на примере 110) получает знания хотя бы об одном участнике каждого поддерева (для 110 выделенных залитыми овалами). Таким образом, каждый K-bucket отражает связь узла с не более, чем K участниками поддерева на уровне i.
Протокол
Протокол Kademlia содержит 4 типа сообщений:
- PING
- STORE
- FIND_VALUE
- FIND_NODE
PING нужен для проверки существования конкретного узла в сети. Например, он применяется при попытке добавления узла в K-bucket, когда тот уже заполнен: опрашиваются существующие узлы, если нет ответа, то узел вставляется. Стоит отметить, что более старые узлы находятся внизу K-bucket, это основывается на экспериментальных данных, говорящих о том, что чем дольше узел остается в сети, тем меньше вероятности, что он ее покинет. Поэтому они будут опрошены только после более новых.
STORE запрос, позволяющий разместить информацию на заданном узле. Перед выполнением STORE узел должен найти K ближайших к ключу значения, которое он собирается опубликовать, а лишь потом отправить каждому STORE с ключом и своими координатами. Хранение сразу на K узлах позволяет повысить доступность информации.
FIND_VALUE запрос, который, зачастую, повторяется для образования итерации, позволяющий найти значение по ключу. Реализует поиск значения в сети. Возвращает либо K ближайших узлов, либо само значение, в зависимости от достижения узла, хранящего искомые данные. Итерации прекращают как раз либо при возвращении значения (успех), либо при возврате уже опрошенных K узлов (значения нет в сети).
FIND_NODE запрос, используемый для поиска ближайших K к заданному идентификатору (поведение сходно с FIND_VALUE, только никогда не возвращает значение, всегда узлы!). Используется, например, при присоединении узла к сети по следующей схеме:
— Контакт с bootstrap узлом
— Посылка запроса FIND_NODE со своим идентификатором к bs узлу, дальнейшая итеративная рассылка
— Обновление K-buckets (при этом обновляются как K-buckets нового узла, так и всех, мимо которых проходил запрос (здесь на руку симметричность метрики XOR))
Как видно, протокол в своей спецификации практически не покрывает вопросы безопасности, что нашло отражение в исследованиях и работах по атаке Kademlia-based сетей.
Из особенностей стоит подчеркнуть наличие репликации, времени жизни значения (необходимость повторного размещения через определенный промежуток времени), параллелизм при посылке запросов FIND_*, дабы достигнуть нужных узлов за более короткое время (обозначается α, в реализациях обычно равно 3). При каждом прохождении запросов происходит попытка обновить K-bucket, что позволяет держать таблицы маршрутизации максимально оптимальными.
4. Реализации
Прежде всего, самой известной сетью, базирующейся на Kademlia является Kad Network, доступная в aMule/eMule. Для bootstrap используются существующие узлы в eDonkey.
Khashmir — Kademlia-реализация на Python, использующаяся в BitTorrent
Из ныне развивающихся и активных библиотек я бы еще отметил
maidsafe-dht — C++ реализация инфраструктуры с поддержкой UDT и NAT Traversal.
Mojito — Java библиотека от LimeWire.
5. Что дальше?
Хотел бы получить комментарии о том, во что следует углубиться подробнее, т.к. статья носит чрезвычайно поверхностный характер. Дабы пробудить интерес, а не выложить все карты разом на стол. Сам планирую в следующей заметке о Kademlia рассказать о проблемах безопасности, атаках и их предотвращении.
6. Материалы и ссылки
- P2P (ENG wikipedia)
- DHT (ENG wikipedia)
- Kademlia (ENG wikipedia)
- Kademlia: A Design Specification
- Kademlia: A Peer to peer information system Based on the XOR Metric
- Theotokis, Spinellis. A Survey of Peer-to-Peer Content Distribution Technologies
- Peer-to-Peer Computing. Principles and Applications. // Springer, 2010
