В комментариях к моему предыдущему топику об асинхронном программировании, коллбеках и использовании process.NextTick() в Node.js было задано немало вопросов о том, за счёт чего получается или может быть получена большая производительность при использовании неблокирующего кода. Постараюсь это наглядно показать :) Статья призвана в основном прояснить некоторые моменты работы Node.js (и libeio в его составе), которые на словах бывает трудно описать.
Пример обработки запросов сервером с блокирующим чтением:
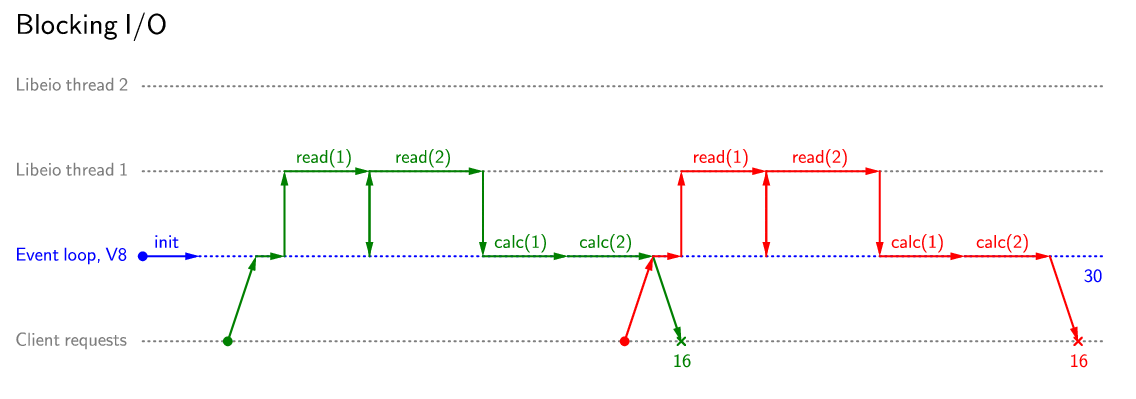
В первую очередь прокомментирую полезность использования неблокирующего ввода/вывода. Как правило, использовать блокирующие операции в Node.js стоит лишь на этапе инициализации приложения, и то не всегда. Правильная обработка ошибок в любом случае потребует использования try/catch, так что код при использовании неблокирующих операций не будет сложнее, чем при использовании блокирующих операций.
Нужно лишь помнить, что случае, когда запросов неблокирующих операций может оказаться больше, чем потоков libeio. В этом случае новые запросы будут становиться в очередь и блокировать выполнение, однако для программиста это будет происходить прозрачно.
Пример обработки запросов сервером с неблокирующим чтением:

Конечно, эти два примера показывают случай, когда производительность сервера максимально увеличивается. Однако, польза от неблокирующего чтения есть при любом времени между приходящими запросами, даже в худшем случае производительно улучшиться за счёт вовлечения в процесс обработки запросов потоков libeio.
Суммарное время обработки запросов (время между отправкой клиентом первого запроса и получения последнего результата обработки, синяя цифра справа) будет меньше в любом случае, если потоков хватает на все запросы. Но даже в самом худшем случае это время не превысит времени обработки при использовании синхронного чтения.
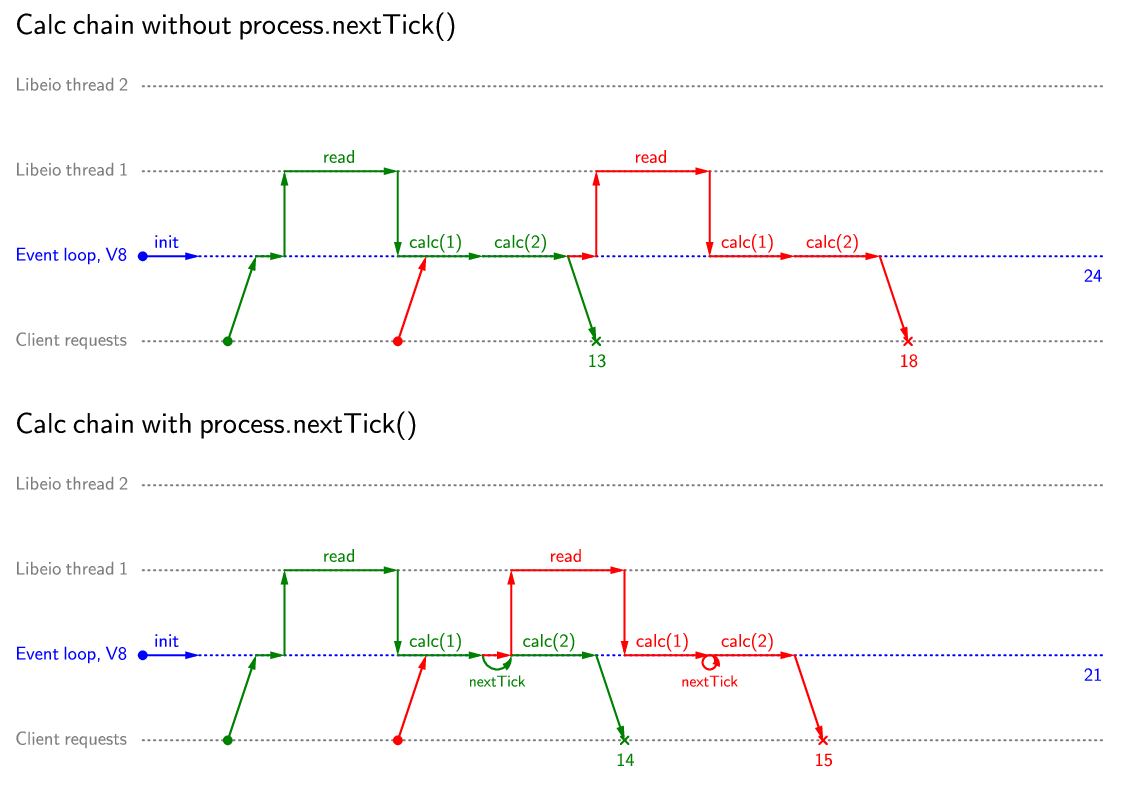
Пример уменьшения времени обработки при почти одновременном приходе двух запросов:

И тут мы подходим к самому нелогичному приёму, который используется программистами Node.js и может вызвать недоумения у большинства разработчиков. В случае, если ввод/вывод занимает большую часть времени обработки запроса, то остальной код оптимизировать не стоит. Однако, время получения данных из memcached может быть соизмеримо с временем выполнения бизнес-логики приложения и шаблонизации. А если использовать кеширование или базу данных в памяти процесса Node.js (Dirty или Alfred), то время работы с базой данных может быть и меньше, чем время работы остальных частей приложения. Поэтому, для разбиения кода на отдельные части и вызова коллбеков используют process.nextTick():
При использовании такого подхода в разделении выполнения calc(1) и calc(2) суммарное время обработки для предыдущего примера с почти одновременным приходом запросов не изменяется, однако первый запрос будет возвращён клиенту позже.
Пример «вреда» от process.nextTick() при почти одновременном приходе двух запросов:

Однако это худший случай с точки зрения применимости process.nextTick(). В случае, если запросы приходят редко, как в первом рассмотренном примере, вреда от process.nextTick() не будет совсем. В случае, если запросы приходят со «средней» частотой, применение process.nextTick() ускорит обработку запросов за счёт того, что в момент прерывания потока выполнения может вклиниться первичная обработка нового запроса и начало неблокирующего чтения. При этом уменьшается как суммарное время обработки, так и среднее время обработки одного запроса.
Пример «пользы» от process.nextTick():
Подведём небольшой итог топика. Во-первых, при использовании Node.js стоит использовать неблокирующий ввод/вывод. Желательно даже в тех случаях, когда используется не стандартное количество потоков libeio, а меньшее, либо при большом количество поступающих запросов. возникающие проблемы можно снять с помощью кеширования и in-process DB, а производительно не будет сильно отличаться от использования других технологий распараллеливания. Во-вторых, от использования process.nextTick() «в среднем» можно улучшить производительность сервера, и в целом от него больше пользы, чем вреда.
UPD (02.02): Незначительно улучшил схемы. Исходники доступны по ссылке: github.com/Sannis/papers_and_talks/tree/master/2011_node_article_async_process_nexttick.
Пример обработки запросов сервером с блокирующим чтением:
В первую очередь прокомментирую полезность использования неблокирующего ввода/вывода. Как правило, использовать блокирующие операции в Node.js стоит лишь на этапе инициализации приложения, и то не всегда. Правильная обработка ошибок в любом случае потребует использования try/catch, так что код при использовании неблокирующих операций не будет сложнее, чем при использовании блокирующих операций.
Нужно лишь помнить, что случае, когда запросов неблокирующих операций может оказаться больше, чем потоков libeio. В этом случае новые запросы будут становиться в очередь и блокировать выполнение, однако для программиста это будет происходить прозрачно.
Пример обработки запросов сервером с неблокирующим чтением:
Конечно, эти два примера показывают случай, когда производительность сервера максимально увеличивается. Однако, польза от неблокирующего чтения есть при любом времени между приходящими запросами, даже в худшем случае производительно улучшиться за счёт вовлечения в процесс обработки запросов потоков libeio.
Суммарное время обработки запросов (время между отправкой клиентом первого запроса и получения последнего результата обработки, синяя цифра справа) будет меньше в любом случае, если потоков хватает на все запросы. Но даже в самом худшем случае это время не превысит времени обработки при использовании синхронного чтения.
Пример уменьшения времени обработки при почти одновременном приходе двух запросов:
И тут мы подходим к самому нелогичному приёму, который используется программистами Node.js и может вызвать недоумения у большинства разработчиков. В случае, если ввод/вывод занимает большую часть времени обработки запроса, то остальной код оптимизировать не стоит. Однако, время получения данных из memcached может быть соизмеримо с временем выполнения бизнес-логики приложения и шаблонизации. А если использовать кеширование или базу данных в памяти процесса Node.js (Dirty или Alfred), то время работы с базой данных может быть и меньше, чем время работы остальных частей приложения. Поэтому, для разбиения кода на отдельные части и вызова коллбеков используют process.nextTick():
// blocking callbacks
function func1_cb(str, cb) {
var res = func1(str);
cb(res);
}
function func2_cb(str, cb) {
var res = func2(str);
cb(res);
}
// non-blocking callbacks
function func1_cb(str, cb) {
var res = func1(str);
process.nextTick(function () {
cb(res);
});
}
function func2_cb(str, cb) {
var res = func2(str);
process.nextTick(function () {
cb(res);
});
}
// usage example
func1_cb(content, function (str) {
func2_cb(str, function (result) {
// work with result
});
});При использовании такого подхода в разделении выполнения calc(1) и calc(2) суммарное время обработки для предыдущего примера с почти одновременным приходом запросов не изменяется, однако первый запрос будет возвращён клиенту позже.
Пример «вреда» от process.nextTick() при почти одновременном приходе двух запросов:
Однако это худший случай с точки зрения применимости process.nextTick(). В случае, если запросы приходят редко, как в первом рассмотренном примере, вреда от process.nextTick() не будет совсем. В случае, если запросы приходят со «средней» частотой, применение process.nextTick() ускорит обработку запросов за счёт того, что в момент прерывания потока выполнения может вклиниться первичная обработка нового запроса и начало неблокирующего чтения. При этом уменьшается как суммарное время обработки, так и среднее время обработки одного запроса.
Пример «пользы» от process.nextTick():
Подведём небольшой итог топика. Во-первых, при использовании Node.js стоит использовать неблокирующий ввод/вывод. Желательно даже в тех случаях, когда используется не стандартное количество потоков libeio, а меньшее, либо при большом количество поступающих запросов. возникающие проблемы можно снять с помощью кеширования и in-process DB, а производительно не будет сильно отличаться от использования других технологий распараллеливания. Во-вторых, от использования process.nextTick() «в среднем» можно улучшить производительность сервера, и в целом от него больше пользы, чем вреда.
UPD (02.02): Незначительно улучшил схемы. Исходники доступны по ссылке: github.com/Sannis/papers_and_talks/tree/master/2011_node_article_async_process_nexttick.