Одно время приходилось постоянно работать с сетевыми данными и в особенности с заголовками сетевого и транспортного уровней модели OSI. Постоянно напрягал тот факт, что многие поля были в Big-Endian, а код выполнялся на архитектуре Little-Endian. Ну невозможно было постоянно вызывать ntohl(), htonl(), ntohs(), htons()...

Автор фото: Ciroduran, источник фото: flickr.
Пришла идея реализации следующей пары шаблонов: LittleEndian<T> и BigEndian<T>.


Используются шаблоны следующим образом:
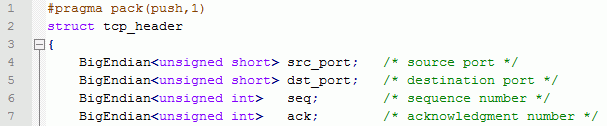
Осталось дать типам более симпатичные имена, например так:
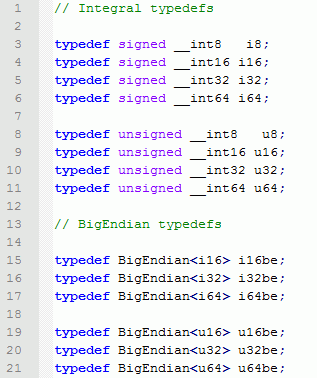
Теперь можно использовать типы через более короткие имена u16be, u32be…
Единственное, в этих шаблонах не хватает различных операторов +=, -=, *=, ++ и прочих. Операторы имеются в полной версии кода, в статье их приводить было нецелесообразно. Вот ссылки на полные исходные кодыLittleBigEndian.h (см. новую ссылку ниже в UPDATE1) и LittleBigEndianNames.h.
UPDATE1:
Как был верно замечено пользователем qehgt в комментарии к посту, код не вполне корректен для 64-битных чисел. Прошу прощения за эту оплошность. ВотLittleBigEndian.h (см. новую ссылку ниже в UPDATE3), в котором эта ошибка исправлена.
UPDATE2:
Товарищ sic провел тесты скорости работы приведённых шаблонов по сравнению с функциями htohl(), htonl(), ntohs(), htons(). Тесты показали относительное повышение быстродействия при использовании приведенных шаблонов вместо вызова библиотечных функций. Спасибо, за проделанную работу.
UPDATE3:
Товарищ rekub увидел возможность повышения быстродействия конструктора копирования объекта. Он предложил использовать union для представления данных и как массива и как переменной типа T. Предложенные модификации были реализованы в следующем исходникеLittleBigEndian.h (см. новую ссылку ниже в UPDATE4). Спасибо!
UPDATE4:
Товарищ vadelve указал на ошибку в реализации операторов постфиксного и префиксного инкремента и декремента. Исправленная версия: LittleBigEndian.h.
Автор фото: Ciroduran, источник фото: flickr.
Пришла идея реализации следующей пары шаблонов: LittleEndian<T> и BigEndian<T>.
Шаблон для порядка байтов LittleEndian:
Шаблон для порядка байтов BigEndian:
Используются шаблоны следующим образом:
Осталось дать типам более симпатичные имена, например так:
Теперь можно использовать типы через более короткие имена u16be, u32be…
Единственное, в этих шаблонах не хватает различных операторов +=, -=, *=, ++ и прочих. Операторы имеются в полной версии кода, в статье их приводить было нецелесообразно. Вот ссылки на полные исходные коды
UPDATE1:
Как был верно замечено пользователем qehgt в комментарии к посту, код не вполне корректен для 64-битных чисел. Прошу прощения за эту оплошность. Вот
UPDATE2:
Товарищ sic провел тесты скорости работы приведённых шаблонов по сравнению с функциями htohl(), htonl(), ntohs(), htons(). Тесты показали относительное повышение быстродействия при использовании приведенных шаблонов вместо вызова библиотечных функций. Спасибо, за проделанную работу.
UPDATE3:
Товарищ rekub увидел возможность повышения быстродействия конструктора копирования объекта. Он предложил использовать union для представления данных и как массива и как переменной типа T. Предложенные модификации были реализованы в следующем исходнике
UPDATE4:
Товарищ vadelve указал на ошибку в реализации операторов постфиксного и префиксного инкремента и декремента. Исправленная версия: LittleBigEndian.h.
