Итак давайте начнем с исходных данных.
Имеется ISP с 4-мя NAS-серверами на базе FreeBSD+MPD5(PPPoE) и стоит задача по нормализации нагрузки на серверы.
Для начала давайте взглянем на график загрузки серверов ДО нормализации:
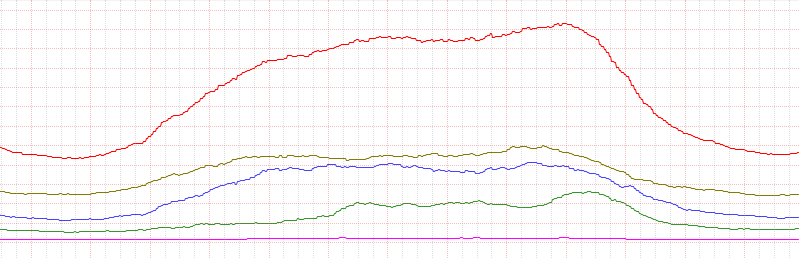
Сразу виден ужасный разброс (обратите внимание на коричневый и синий графики).
Эти сервера имеют одинаковую конфигурацию(ПОЧТИ одинаковую по сравнению другими NAS-ами см.UPD_1), одинаковый софт и одинаковые настройки (и одинаковое подключение в сеть). Но судя по графику один из них все же простаивает больше чем другой.
Дабы восстановить справедливость и было затеяно это мероприятие.
Технически мы будем использовать телнет-доступ к mpd5 и задавать параметр max-children для ограничения доступа к конкретному NAS-у или же в случае
предоставления доступа к конкретному серверу — будем устанавливать max-children = 10000.
Также мы будем читать количество пользователей конкретного NAS-а для последующего анализа алгоритмом.
Самый спорный раздел. Здесь я приведу свои умозаключения которые РАБОТАЮТ. Но всё же прошу вносить свое видение этого алгоритма. Итак для начала мы имеем на входе список NAS-ов в формате:
Название сервера, адрес, порт, имя администратора mpd, пароль, коефециент нормализации (фактически это максимальное количество паралельных сессий которое поддерживает данный сервер)
Суть алгоритма такова:
По пунктам реализации:
1. Определяем количество пользователей:
2. Считаем сумму коэффициентов всех серверов.:
3.Считаем сумму всех пользователей онлайн из списка полученного на в.1:
4.Вычисляем новый коэффициент с учетом коэффициентов тех серверов которые могли упасть (new_koeff = koeff*(nascount/naswcount)):
5. Вычисляем процент заполненности серверов (percent = 100% * klk/koeff) и сортируем:
Теперь делаем «финт ушами» (заменяем для всех серверов кроме 2-х наименее загруженных коэффициенты на -1 (лично мне не очень нравится такой подход но пока не знаю как его «культурнее» сделать):
После этого в ress2 у нас уже есть все необходимое для установки max-children в mpd. Что собственно мы и делаем (для серверов помеченных -1 устанавливаем максимальное количество в 10000, а для всех остальных равное текущему количество пользователей — 10%(просто коэффициент можно взятый из головы, главное чтоб не больше текущего количества подключенных пользователей):
В результате после установки в cron этого скрипта получилась вот такая нормализация
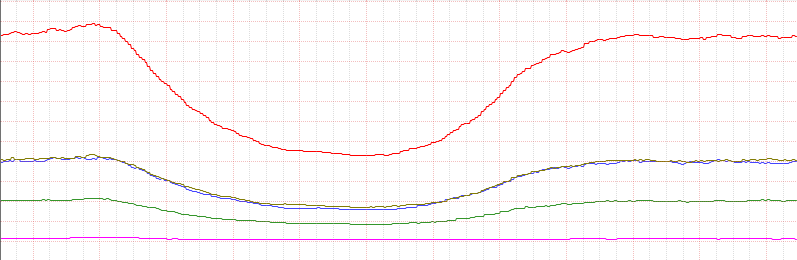
Синий-коричневый идут практически одинаково. Чего и надо было добиться
P.S.
по вопросам работы с телнетом на питоне: сюда
параметры mpd5(на русском): здесь
Р.Р.S.
При работе незабывайте обяательно «дочитывать» вывод телнет-а до конца dummy = client.read_until("[]") иначе будуть непредвиденные последствия (не сработавшие команды например)
UPD: Изменил название чтоб более (спасибо obramko). Было: "round-robin для нормализации нагрузки на VPN сервера MPD5"
UPD_1 от админа: Некоторые уточнения по поводу "спорных" NAS-ов:
Коричневый:
Синий:
В обох случаях используется LAGG на 2-х EM-ках для связей с клиентами и по одному igb — выход в мир.
Разница в Процесоре и ОЗУ.
Приношу свои извинения чесному народу за то что ввел в заблуждение относительно ОДИНАКОВОСТИ серверов. НО в принцыпе они держат нормально одинаковое количество пользователей при использовании приведенной выше техники. Поэтому считаю эту заметку — полезной и жду Ваших комментариев.
UPD_2 от админа: Причины которые заставили нас разработать этот метод.
Так уж случилось что большинство клиентов соединяется с утра но качать начинает в 6-7 вечера.
Без нормализации «синий» NAS-принимает на себя бОльшую часть коннектов. и нормально с ними работает до пика. А так как после 6-7часов большинство клиентов начинает качать на 15-20Мбит каждый то он не выдерживает и где-то раз в 2 недели паникует. Этот метод нормализации раскидывает клиентов согласно установленным нами коэффициентам еще до наступления часа Х тем самым обеспечив клиентам более надежную связь а саппорту лишние пару часов сна.
Имеется ISP с 4-мя NAS-серверами на базе FreeBSD+MPD5(PPPoE) и стоит задача по нормализации нагрузки на серверы.
Для начала давайте взглянем на график загрузки серверов ДО нормализации:
Сразу виден ужасный разброс (обратите внимание на коричневый и синий графики).
Эти сервера имеют одинаковую конфигурацию(ПОЧТИ одинаковую по сравнению другими NAS-ами см.UPD_1), одинаковый софт и одинаковые настройки (и одинаковое подключение в сеть). Но судя по графику один из них все же простаивает больше чем другой.
Дабы восстановить справедливость и было затеяно это мероприятие.
Техника нормализации
Технически мы будем использовать телнет-доступ к mpd5 и задавать параметр max-children для ограничения доступа к конкретному NAS-у или же в случае
предоставления доступа к конкретному серверу — будем устанавливать max-children = 10000.
Также мы будем читать количество пользователей конкретного NAS-а для последующего анализа алгоритмом.
Алгоритм
Самый спорный раздел. Здесь я приведу свои умозаключения которые РАБОТАЮТ. Но всё же прошу вносить свое видение этого алгоритма. Итак для начала мы имеем на входе список NAS-ов в формате:
nases = [
('VPN2',('192.168.X.Y','5001','username','password',600)),
('VPN3',('192.168.X.Y1','5001','username','password',300)),
('VPN4',('192.168.X.Y2','5001','username','password',600)),
('VPN5',('192.168.X.Y3','5001','username','password',200))
]
Название сервера, адрес, порт, имя администратора mpd, пароль, коефециент нормализации (фактически это максимальное количество паралельных сессий которое поддерживает данный сервер)
Суть алгоритма такова:
- Определяем все ли серверы работают (если один или несколько серверов упали — перераспределяем их коэффициенты пропорционально между другими)
- Вычисляем процент заполненности каждого сервера с учетом п.1
- Сортируем список в порядке убывания процента заполненности
- Отключаем N самых заполненных серверов и делаем доступными остальные
По пунктам реализации:
1. Определяем количество пользователей:
def getUserCount(anas):
(nas,params) = anas
(host,port,user,pwd,koeff) = params
try:
client = telnetlib.Telnet(host,port)
client.read_until("Username:")
client.write(user+'\n')
client.read_until("Password:")
client.write(pwd+'\n')
client.read_until("[]")
client.write("sh mem \n")
res = int(client.read_until("BUND").split('\n')[3].split()[1])
dummy = client.read_until("[]")
client.write("sh global \n")
limit=int(client.read_until("Global options").split("\n")[10].split()[2])
client.close()
return (nas,(res,limit),params)
except:
return (nas,(0,0),params)
ress = map(getUserCount,nases)
2. Считаем сумму коэффициентов всех серверов.:
naskcount = reduce(lambda total,nas: total+nas[1][4],nases,0)
3.Считаем сумму всех пользователей онлайн из списка полученного на в.1:
naswcount = reduce(lambda total,nas: total+(((nas[1][0] != 0) and nas[2][4]) or 0),ress,0)
4.Вычисляем новый коэффициент с учетом коэффициентов тех серверов которые могли упасть (new_koeff = koeff*(nascount/naswcount)):
def corKoeff(nas):
(nas,(klk,limit),params) = nas
(host,port,user,pwd,koeff) = params
koeff = koeff * ((klk != 0 ) and (float(naskcount)/float(naswcount)) or 0)
params = (host,port,user,pwd,int(round(koeff,0)))
return (nas,(klk,limit),params)
ress1 = map(corKoeff,ress)
5. Вычисляем процент заполненности серверов (percent = 100% * klk/koeff) и сортируем:
def calcMaxUser(nas):
(nas,(klk,limit),params) = nas
(host,port,user,pwd,koeff) = params
return (nas,klk,(koeff !=0 and float(100*klk)/float(koeff)) or 0,params)
ress2 = map(calcMaxUser,ress1)
ress2.sort(lambda x,y: cmp(x[2],y[2]))
Теперь делаем «финт ушами» (заменяем для всех серверов кроме 2-х наименее загруженных коэффициенты на -1 (лично мне не очень нравится такой подход но пока не знаю как его «культурнее» сделать):
for i in range(-1,-len(ress2)+1,-1):
(nas,klk,koeff,params) = ress2[i]
koeff = -1
ress2[i] = (nas,klk,koeff,params)
После этого в ress2 у нас уже есть все необходимое для установки max-children в mpd. Что собственно мы и делаем (для серверов помеченных -1 устанавливаем максимальное количество в 10000, а для всех остальных равное текущему количество пользователей — 10%(просто коэффициент можно взятый из головы, главное чтоб не больше текущего количества подключенных пользователей):
def setMax(nas):
(nas,klk,koeff,params) = nas
(host,port,user,pwd,kkx) = params
if koeff != -1:
klk = 10000
else:
klk = round(klk * float(100-down_koeff)/float(100))
try:
client = telnetlib.Telnet(host,port)
client.read_until("Username:")
client.write(user+'\n')
client.read_until("Password:")
client.write(pwd+'\n')
client.read_until("[]")
client.write("set global max-children %d\n" % klk)
client.close()
return (nas,"max set to %d" % klk)
except:
return (nas,"Error setting max-children %d" % klk)
Результат
В результате после установки в cron этого скрипта получилась вот такая нормализация
Синий-коричневый идут практически одинаково. Чего и надо было добиться
P.S.
по вопросам работы с телнетом на питоне: сюда
параметры mpd5(на русском): здесь
Р.Р.S.
При работе незабывайте обяательно «дочитывать» вывод телнет-а до конца dummy = client.read_until("[]") иначе будуть непредвиденные последствия (не сработавшие команды например)
UPD: Изменил название чтоб более (спасибо obramko). Было: "round-robin для нормализации нагрузки на VPN сервера MPD5"
UPD_1 от админа: Некоторые уточнения по поводу "спорных" NAS-ов:
Коричневый:
FreeBSD 8.2-RELEASE-p1 #1: Fri May 13 22:55:37 EEST 2011
CPU: Intel(R) Core(TM) i7 CPU 860 @ 2.80GHz (3363.89-MHz K8-class CPU)
Origin = "GenuineIntel" Id = 0x106e5 Family = 6 Model = 1e Stepping = 5 Features=0xbfebfbff <FPU,VME,DE,PSE,TSC,MSR,PAE,MCE,CX8,APIC,SEP,MTRR,PGE,MCA,CMOV,PAT,PSE36,CLFLUSH,DTS,ACPI,MMX,FXSR,SSE,SSE2,SS,HTT,TM,PBE > Features2=0x98e3fd <SSE3,DTES64,MON,DS_CPL,VMX,SMX,EST,TM2,SSSE3,CX16,xTPR,PDCM,SSE4.1,SSE4.2,POPCNT >
AMD Features=0x28100800 <SYSCALL,NX,RDTSCP,LM>
AMD Features2=0x1<LAHF>
TSC: P-state invariant
real memory = 2147483648 (2048 MB)
avail memory = 2041532416 (1946 MB)
Синий:
FreeBSD 8.2-RELEASE-p1 #1: Fri May 13 22:55:37 EEST 2011
Timecounter "i8254" frequency 1193182 Hz quality 0
CPU: Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz (2664.79-MHz K8-class CPU)
Origin = "GenuineIntel" Id = 0x106a5 Family = 6 Model = 1a Stepping = 5 Features=0xbfebfbff < FPU,VME,DE,PSE,TSC,MSR,PAE,MCE,CX8,APIC,SEP,MTRR,PGE,MCA,CMOV,PAT,PSE36,CLFLUSH,DTS,ACPI,MMX,FXSR,SSE,SSE2,SS,HTT,TM,PBE >
Features2=0x98e3bd < SSE3,DTES64,MON,DS_CPL,VMX,EST,TM2,SSSE3,CX16,xTPR,PDCM,SSE4.1,SSE4.2,POPCNT >
AMD Features=0x28100800 <SYSCALL,NX,RDTSCP,LM >
AMD Features2=0x17<LAHF>
TSC: P-state invariant
real memory = 4294967296 (4096 MB)
avail memory = 4106272768 (3916 MB)
В обох случаях используется LAGG на 2-х EM-ках для связей с клиентами и по одному igb — выход в мир.
Разница в Процесоре и ОЗУ.
Приношу свои извинения чесному народу за то что ввел в заблуждение относительно ОДИНАКОВОСТИ серверов. НО в принцыпе они держат нормально одинаковое количество пользователей при использовании приведенной выше техники. Поэтому считаю эту заметку — полезной и жду Ваших комментариев.
UPD_2 от админа: Причины которые заставили нас разработать этот метод.
Так уж случилось что большинство клиентов соединяется с утра но качать начинает в 6-7 вечера.
Без нормализации «синий» NAS-принимает на себя бОльшую часть коннектов. и нормально с ними работает до пика. А так как после 6-7часов большинство клиентов начинает качать на 15-20Мбит каждый то он не выдерживает и где-то раз в 2 недели паникует. Этот метод нормализации раскидывает клиентов согласно установленным нами коэффициентам еще до наступления часа Х тем самым обеспечив клиентам более надежную связь а саппорту лишние пару часов сна.
