 В стремлении рассказать о самом сложном, как можно быстрее, очевидно, забываешь о самом простом. И, в моем случае, не только о простом, но и о важном связывающем звене. Причинно-следственная связь слегка нарушилась. В моих предыдущих статьях (1, 2, 3, 4) описаны математический аспект и программирование, но в них практически нет биологии. Поэтому эта статья о том, какую именно часть молекулярной биологии пытаются раскрыть, предсказать, увидеть и решить описываемые мною программы и алгоритмы.
В стремлении рассказать о самом сложном, как можно быстрее, очевидно, забываешь о самом простом. И, в моем случае, не только о простом, но и о важном связывающем звене. Причинно-следственная связь слегка нарушилась. В моих предыдущих статьях (1, 2, 3, 4) описаны математический аспект и программирование, но в них практически нет биологии. Поэтому эта статья о том, какую именно часть молекулярной биологии пытаются раскрыть, предсказать, увидеть и решить описываемые мною программы и алгоритмы.Рисунок с изображением яйцеклетки и сперматозоидов на поверхности символизирует пропущенный мною этап, когда все только зарождается. Интересный факт, что объединение двух клеток дает начало примерно 10 триллионам клеткам человеческого тела.
Начнем с небольшого экскурса в молекулярную биологию. Я постараюсь описать простыми словами сложные вещи, опуская детали. ДНК находится в клетке. Мы рассматриваем именно ДНК и процессы, которые протекают на ней, нас не очень интересует, где именно в клетке она расположена. Необходимо уточнить, что примеры будут приведены для клеток eukaryotic, с которыми я работаю, но скорее всего многие вещи подойдут и для prokaryotic.
Все процессы в клетке начинаются с ДНК, именно на ДНК находятся последовательности нуклеотидов, копирование которых в дальнейшем отвечает за реакции и преобразования в клетках. Нас интересует процесс копирования, называемый транскрипцией. Процесс копирования транскриптов и количество полученных конечных продуктов называется генной экспрессией. Но мы называем генной экспрессией и измеряем именно количество копирований транскрипта (вне зависимости от количества полученных конечных продуктов).
Ниже приведена иллюстрация из учебника по биологии, называемая “четыре основных генетических процесса, происходящие в клетке” (см. Рис. 1). В данный момент я занимаюсь процессами, изображенными на этом рисунке между номерами 1 и 2. Технологии, которые помогают их изучить, называются DNA-seq и RNA-seq. Эти технологии могут использоваться как по отдельности, так и совместно. В этой статье я более подробно остановлюсь на механизмах работы DNA-seq.

Рис. 1
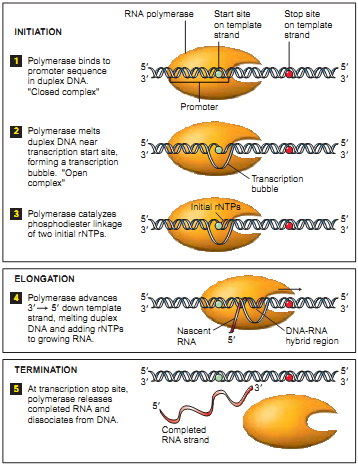 В качестве частного случая DNA-seq рассмотрим “DNA-seq Pol II” (также см. в “Готовимся работать с ZINBA”). В основе понимания полученного с ее помощью результата лежит процесс траскрипции. Важную роль в процессе траскрипции играет белок РНК-полимераза (RNA Polymerase). Полимераза закрепляется на специальном участке ДНК (см. Рис. 2.1), который называется промоутером. Пока проходят подготовительные операции процесса транскрипции (этап Initiation), полимераза остается закрепленной на промоутере. Полимераза начинает создавать копию верхней спирали от старт сайта (начало копируемой цепочки, на рисунке обозначено синей точкой). Потом, двигаясь со скоростью примерно 1000 оснований в минуту (при температуре 37C), она копирует участок ДНК до стоп сайта (конец копируемой цепочки, на рисунке обозначен красной точкой). Еще раз подчеркну, что в положении промоутера полимераза находится большую часть времени, а на каждом участке копируемой ДНК — меньшее. Для дальнейшего изучения ученых интересует промоутер и старт сайт, являющиеся необходимым условием начала транскрипции. Также в промоутере заложена информация о количестве копирований, что тоже является немаловажным объектом изучения.
В качестве частного случая DNA-seq рассмотрим “DNA-seq Pol II” (также см. в “Готовимся работать с ZINBA”). В основе понимания полученного с ее помощью результата лежит процесс траскрипции. Важную роль в процессе траскрипции играет белок РНК-полимераза (RNA Polymerase). Полимераза закрепляется на специальном участке ДНК (см. Рис. 2.1), который называется промоутером. Пока проходят подготовительные операции процесса транскрипции (этап Initiation), полимераза остается закрепленной на промоутере. Полимераза начинает создавать копию верхней спирали от старт сайта (начало копируемой цепочки, на рисунке обозначено синей точкой). Потом, двигаясь со скоростью примерно 1000 оснований в минуту (при температуре 37C), она копирует участок ДНК до стоп сайта (конец копируемой цепочки, на рисунке обозначен красной точкой). Еще раз подчеркну, что в положении промоутера полимераза находится большую часть времени, а на каждом участке копируемой ДНК — меньшее. Для дальнейшего изучения ученых интересует промоутер и старт сайт, являющиеся необходимым условием начала транскрипции. Также в промоутере заложена информация о количестве копирований, что тоже является немаловажным объектом изучения. Процесс DNA-seq Pol II с осаждением проходит в несколько этапов: 1. фиксируем текущее положение полимеразы химически или температурно (фиксирование полимеразы означает, что процессы остановились, полимераза не двигается более по ДНК); 2. произвольным способом (ультразвук, MNase и т.д.) нарезаем ДНК (в большинстве случаев разрезаются незащищённые полимеразой участки ДНК); 3. с помощью иммунопреципитации хроматина (антитела, иммунного ко всем остальным белкам, кроме Pol II) выбираем те участки, которые содержат полимеразу. В результате получаем фрагменты около 150 оснований в длину, которые в дальнейшем отправим в секвенатор. Следует подчеркнуть, что нарезка полимеразы происходит не строго по краям. Таким образом процесс получается следующим: мы подготовили миллионы одной и той же ДНК из разных клеток, зафиксировали полимеразы, большая часть которых находится на промоутере, а часть случайным образом распределена по гену. Результат оцифровки описанного процесса мы наблюдаем на следующем рисунке, приведенном в одной из статей (см. Рис.3). Зелёным обведены риды, определяющие предполагаемый промоутер (риды с высокой плотностью), а за ним располагаются риды с низкой плотностью, соответствующие полимеразе в движении.
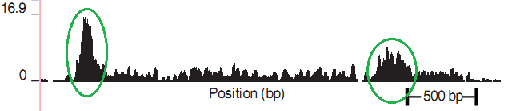
Рис. 3
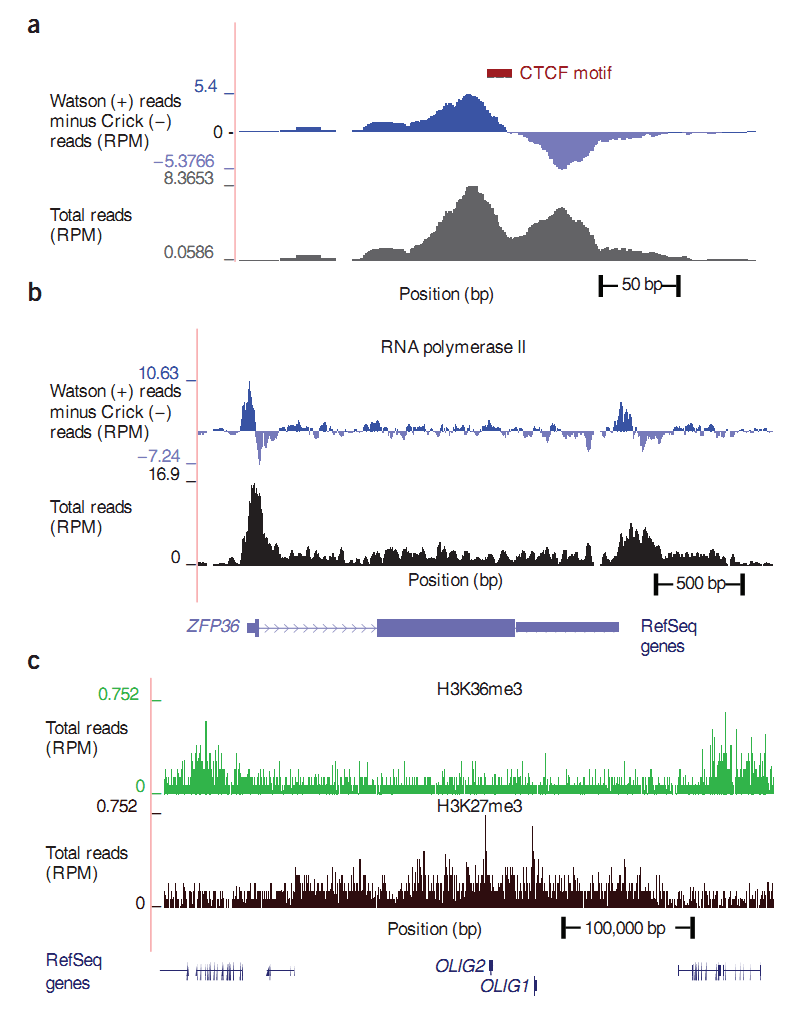
Далее я кратко расскажу о некоторых других белках. В верхней части рисунка 4 можно увидеть, каким образом упакована ДНК (см. Рис. 4.1.), а в нижней части рисунка более детально изображен процесс транскрипции, о котором говорилось выше (см. Рис. 4.2.). Как видно на рисунке 4.1., упаковка ДНК очень плотная, двойная спираль намотана на нуклеосому, длина витка ДНК составляет примерно 146 оснований. Нуклеосома состоит из белков — гистонов. Гистоны могут иметь различные модификации, модификация гистонов — тема огромной отдельной статьи. Антитела разрабатываются на конкретную модификацию гистона, и именно участки ДНК, которые обмотаны вокруг этой модификации гистона, будут осаждены (отфильтрованы). Приведем пример обозначения модификации: H3K4Me3. Он будет читаться, как триметилирование лизина на четвертой позиции гистона H3. Таких модификаций гистонов может быть много, и все они раскиданы по ДНК, поэтому в статье “Готовимся работать с ZINBA” на рисунке 2, где изображен ландшафт H3K27Me3 (триметилирование лизина 27 гистона 3), наблюдается такое частое нагромождение пиков.
Существуют технологии DNA-seq без осаждения, когда ДНК просто нарезается, например, при помощи DNase фермента, и мы получаем огромное количество фрагментов. В большинстве случаев фрагменты будут соответствовать виткам, которые обмотаны вокруг нуклеосом, поскольку DNase режет между ними. Получившиеся фрагменты отправляем в секвенатор. Считается, что при глубоком секвенировании (огромное количество фрагментов, около 100 миллионов ридов, идет в секвенатор, пока является дорогим удовольствием) по получившемуся ландшафту можно распознать, где именно находится белок. Причем ландшафт будет иметь вид, как у вулкана, небольшое углубление на вершине должно соответствовать белку. Чаще всего DNase метод используют, чтобы найти участки ДНК, чувствительные к этому ферменту, т.е. те участки, которые лучше всего режутся.

Рис. 4
На нижней части рисунка мы видим РНК-полимеразу, а также разноцветные облака и овалы, размещенные в ней и на ДНК. Эти дополнительные элементы называют транскриптационными факторами, они играют важную роль в регуляции генной экспрессии. Транскриптационные факторы могут как увеличивать, так и уменьшать или просто блокировать возможность присоединения других транскипционных факторов, тем самым неявно приводя к регуляции экспресии. Они также являются белками. Как и ко всем остальным белкам, к ним разрабатываются антитела. В качестве примера транскриптационного фактора возьмем белок CTCF, одна из его ролей состоит в блокировании работы других транскриптационных факторов. DNA-seq эксперименты с ним описаны в статье “Готовимся работать с ZINBA”, соответствующий CTCF иммунопреципитации хроматина ландшафт можно увидеть на следующем рисунке. Как видно, регионы, защищенные этим белком, небольшие, поэтому и разброс в окрестности невысокий, всего 150-200bp.
Примерная схема видов DNA-seq экспериментов (методы секвенирования):

Рис. 5
Схему я разбил на четыре условных уровня. Первый уровень — фиксация, она может проводиться с формальдегидом или без. Второй уровень — способ нарезки ДНК. Третий уровень — фильтрация по размеру, в дополнении к этому фильтрация может проводиться с помощью иммунопреципитации хроматина. Четвертый уровень — метод секвенирования.
Таким образом, каждому виду проводимого эксперимента соответствует способ секвинирования. В зависимости от способа секвенирования создаются различные виды фрагментов. Рассмотрим те эксперименты, результатами которых являются фрагменты, содержащие в себе белок. Белок может быть размещен по центру кусочка или с одной из двух сторон кусочка. Секвенатор декодирует не весь отрезок, а только его небольшую часть со стороны 5’ конца спирали каждого фрагмента. Декодированные кусочки называются ридами. На рисунке 6 красными точками отмечены 5’ концы каждой спирали. Синей и красной стрелками отмечены начала ридов. Эти начала распределены случайным образом от 5’ конца каждой спирали до границы белка.

Рис. 6
В эксперименте участвует множество исходных молекул, их ДНК нарезают в некоторой окрестности белка, когда множество ридов отображают на координатную ось (одного из белков), получается картинка, похожая на эту:

Рис. 7
Выше координатной оси (темно-синего цвета) отображены риды с верхней спирали («+» strand), а ниже оси (светло-синего цвета) отображены риды с нижней спирали («-» strand). Точно сказать, где был белок невозможно, предполагается, что центр связывания белка расположен между этими двумя пиками.
Полученная картинка напоминает сигнал, и поэтому к данным стали применять некоторые алгоритмы для анализа сигналов, один из которых описан в этой статье habrahabr.ru/blogs/algorithm/135281 — “Что такое скрытые модели Маркова”.
Надеюсь, после этой статьи предмет стал более понятен, и дальнейшее изучение не будет вызывать легкий ужас. Если кто-то заинтересуется более подробным изложением материала, есть замечательная книжка Molecular Cell Biology под редакцией Lodish, в которой очень информативно и доступно изложены основы молекулярной биологии, часть иллюстраций заимствована из неё.
Review is prepared by Andrey Kartashov, Cincinnati, OH, porter@porter.st.

{kind=link}