Прочитав в этом блоге о балансировке на стороне клиента, решил опубликовать свою статью, в которой описаны основные принципы масштабирования для web-проектов. Надеюсь, хабралюдям будет интересно почитать.
Масштабируемость — способность устройства увеличивать свои
возможности
путем наращивания числа функциональных блоков,
выполняющих одни и
те же задачи.
Глоссарий.ru
Обычно о масштабировании начинают думать тогда, когда один
сервер не справляется с возложенной на него работой. С чем именно он не
справляется? Работа любого web-сервера по большому счету сводится к основному
занятию компьютеров — обработке данных. Ответ на HTTP (или любой другой) запрос
подразумевает проведение некоторых операций над некими данными. Соответственно,
у нас есть две основные сущности — это данные (характеризуемые своим объемом) и
вычисления (характеризуемые сложностью). Сервер может не справляться со своей
работой по причине большого объема данных (они могут физически не помещаться на
сервере), либо по причине большой вычислительной нагрузки. Речь здесь идет,
конечно, о суммарной нагрузке — сложность обработки одного запроса может быть
невелика, но большое их количество может «завалить» сервер.
В основном мы будем говорить о масштабировании на примере
типичного растущего web-проекта, однако описанные здесь принципы подходят и для
других областей применения. Сначала мы рассмотрим архитектуру проекта и простое
распределение ее составных частей на несколько серверов, а затем поговорим о
масштабировании вычислений и данных.
Жизнь типичного сайта начинается с очень простой архитектуры
— это один web-сервер (обычно в его роли выступает Apache),
который занимается всей работой по обслуживанию HTTP-запросов,
поступающих от посетителей. Он отдает клиентам так называемую «статику», то
есть файлы, лежащие на диске сервера и не требующие обработки: картинки (gif,
jpg, png), листы стилей (css), клиентские скрипты (js, swf). Тот же сервер
отвечает на запросы, требующие вычислений — обычно это формирование
html-страниц, хотя иногда «на лету» создаются и изображения и другие документы.
Чаще всего ответы на такие запросы формируются скриптами, написанными на php,
perl или других языках.
Минус такой простой схемы работы в том, что разные по
характеру запросы (отдача файлов с диска и вычислительная работа скриптов)
обрабатываются одним и тем же web-сервером. Вычислительные запросы требуют
держать в памяти сервера много информации (интерпретатор скриптового языка,
сами скрипты, данные, с которыми они работают) и могут занимать много
вычислительных ресурсов. Выдача статики, наоборот, требует мало ресурсов
процессора, но может занимать продолжительное время, если у клиента низкая
скорость связи. Внутреннее устройство сервера Apache предполагает, что каждое
соединение обрабатывается отдельным процессом. Это удобно для работы скриптов,
однако неоптимально для обработки простых запросов. Получается, что тяжелые (от
скриптов и прочих данных) процессы Apache много времени проводят в ожидании (сначала при получении
запроса, затем при отправке ответа), впустую занимая память сервера.
Решение этой проблемы — распределение работы по обработке
запросов между двумя разными программами — т.е. разделение на frontend и
backend. Легкий frontend-сервер выполняет задачи по отдаче статики, а остальные
запросы перенаправляет (проксирует) на backend, где выполняется формирование
страниц. Ожидание медленных клиентов также берет на себя frontend, и если он использует
мультиплексирование (когда один процесс обслуживает нескольких клиентов — так
работают, например, nginx или lighttpd), то ожидание практически ничего не
стоит.
Из других компонент сайта следует отметить базу данных, в
которой обычно хранятся основные данные системы — тут наиболее популярны
бесплатные СУБД MySQL и PostgreSQL. Часто отдельно выделяется хранилище
бинарных файлов, где содержатся картинки (например, иллюстрации к статьям
сайта, аватары и фотографии пользователей) или другие файлы.
Таким образом, мы получили схему архитектуры, состоящую из
нескольких компонент.

Обычно в начале жизни сайта все компоненты архитектуры
располагаются на одном сервере. Если он перестает справляться с нагрузкой, то
есть простое решение — вынести наиболее легко отделяемые части на другой
сервер. Проще всего начать с базы данных — перенести ее на отдельный сервер и
изменить реквизиты доступа в скриптах. Кстати, в этот момент мы сталкиваемся с
важностью правильной архитектуры программного кода. Если работа с базой данных
вынесена в отдельный модуль, общий для всего сайта — то исправить параметры
соединения будет просто.
Пути дальнейшего разделения компонент тоже понятны — например, можно вынести frontend на отдельный сервер. Но обычно frontend
требует мало системных ресурсов и на этом этапе его вынос не даст существенного
прироста производительности. Чаще всего сайт упирается в производительность
скриптов — формирование ответа (html-страницы) занимает слишком долгое время.
Поэтому следующим шагом обычно является масштабирование backend-сервера.
Типичная ситуация для растущего сайта — база данных уже
вынесена на отдельную машину, разделение на frontend и backend выполнено,
однако посещаемость продолжает увеличиваться и backend не успевает обрабатывать
запросы. Это значит, что нам необходимо распределить вычисления на несколько
серверов. Сделать это просто — достаточно купить второй сервер и поставить на
него программы и скрипты, необходимые для работы backend.
После этого надо сделать так, чтобы запросы пользователей распределялись
(балансировались) между полученными серверами. О разных способах балансировки
будет сказано ниже, пока же отметим, что обычно этим занимается frontend,
который настраивают так, чтобы он равномерно распределял запросы между
серверами.
Важно, чтобы все backend-серверы были способны правильно
отвечать на запросы. Обычно для этого необходимо, чтобы каждый из них работал с
одним и тем же актуальным набором данных. Если мы храним всю информацию в единой
базе данных, то СУБД сама обеспечит совместный доступ и согласованность данных.
Если же некоторые данные хранятся локально на сервере (например, php-сессии
клиента), то стоит подумать о переносе их в общее хранилище, либо о более
сложном алгоритме распределения запросов.
Распределить по нескольким серверам можно не только работу
скриптов, но и вычисления, производимые базой данных. Если СУБД выполняет много
сложных запросов, занимая процессорное время сервера, можно создать несколько
копий базы данных на разных серверах. При этом возникает вопрос синхронизации
данных при изменениях, и здесь применимы несколько подходов.
Возможны разные варианты распределения системы по серверам.
Например, у нас может быть один сервер базы данных и несколько backend (весьма
типичная схема), или наоборот — один backend и несколько БД. А если мы масштабируем
и backend-сервера, и базу данных, то можно объединить backend и копию базы на
одной машине. В любом случае, как только у нас появляется несколько экземпляров
какого-либо сервера, возникает вопрос, как правильно распределить между ними
нагрузку.
Пусть мы создали несколько серверов (любого назначения — http, база данных и т.п.), каждый из которых может обрабатывать запросы. Перед
нами встает задача — как распределить между ними работу, как узнать, на какой
сервер отправлять запрос? Возможны два основных способа распределения запросов.
Разумеется, существуют и комбинации этих подходов. Например,
такой известный способ распределения нагрузки, как DNS-балансировка, основан на
том, что при определении IP-адреса сайта клиенту выдается
адрес одного из нескольких одинаковых серверов. Таким образом, DNS выступает в
роли балансирующего узла, от которого клиент получает «распределение». Однако
сама структура DNS-серверов предполагает отсутствие точки отказа за счет
дублирования — то есть сочетаются достоинства двух подходов. Конечно, у такого
способа балансировки есть и минусы — например, такую систему сложно динамически
перестраивать.
Работа с сайтом обычно не ограничивается одним запросом.
Поэтому при проектировании важно понять, могут ли последовательные запросы
клиента быть корректно обработаны разными серверами, или клиент должен быть
привязан к одному серверу на время работы с сайтом. Это особенно важно, если на
сайте сохраняется временная информация о сессии работы пользователя (в этом
случае тоже возможно свободное распределение — однако тогда необходимо хранить
сессии в общем для всех серверов хранилище). «Привязать» посетителя к
конкретному серверу можно по его IP-адресу (который, однако, может меняться),
или по cookie (в которую заранее записан идентификатор сервера), или даже
просто перенаправив его на нужный домен.
С другой стороны, вычислительные сервера могут быть и не равноправными.
В некоторых случаях выгодно поступить наоборот, выделить отдельный сервер для
обработки запросов какого-то одного типа — и получить вертикальное разделение
функций. Тогда клиент или балансирующий узел будут выбирать сервер в
зависимости от типа поступившего запроса. Такой подход позволяет отделить
важные (или наоборот, не критичные, но тяжелые) запросы от остальных.
Мы научились распределять вычисления, поэтому большая
посещаемость для нас не проблема. Однако объемы данных продолжают расти,
хранить и обрабатывать их становится все сложнее — а значит, пора строить
распределенное хранилище данных. В этом случае у нас уже не будет одного или
нескольких серверов, содержащих полную копию базы данных. Вместо этого, данные
будут распределены по разным серверам. Какие возможны схемы распределения?
Для выбора правильной схемы распределения данных необходимо
внимательно проанализировать структуру базы. Существующие таблицы (и, возможно,
отдельные поля) можно классифицировать по частоте доступа к записям, по частоте
обновления и по взаимосвязям (необходимости делать выборки из нескольких
таблиц).
Как упоминалось выше, кроме базы данных сайту часто требуется
хранилище для бинарных файлов. Распределенные системы хранения файлов
(фактически, файловые системы) можно разделить на два класса.
Надо отметить, что распределение данных решает не только
вопрос хранения, но и частично вопрос распределения нагрузки — на каждом
сервере становится меньше записей, и потому обрабатываются они быстрее.
Сочетание методов распределения вычислений и данных позволяет построить
потенциально неограниченно-масштабируемую архитектуру, способную работать с
любым количеством данных и любыми нагрузками.
Подводя итог сказанному, сформулируем выводы в виде кратких тезисов.
Продолжить изучение этой темы можно на интересных англоязычных сайтах и блогах:
P.S. Комментарии, конечно, приветствуются ;)
Основы масштабирования
Масштабируемость — способность устройства увеличивать свои
возможности
путем наращивания числа функциональных блоков,
выполняющих одни и
те же задачи.
Глоссарий.ru
Обычно о масштабировании начинают думать тогда, когда один
сервер не справляется с возложенной на него работой. С чем именно он не
справляется? Работа любого web-сервера по большому счету сводится к основному
занятию компьютеров — обработке данных. Ответ на HTTP (или любой другой) запрос
подразумевает проведение некоторых операций над некими данными. Соответственно,
у нас есть две основные сущности — это данные (характеризуемые своим объемом) и
вычисления (характеризуемые сложностью). Сервер может не справляться со своей
работой по причине большого объема данных (они могут физически не помещаться на
сервере), либо по причине большой вычислительной нагрузки. Речь здесь идет,
конечно, о суммарной нагрузке — сложность обработки одного запроса может быть
невелика, но большое их количество может «завалить» сервер.
В основном мы будем говорить о масштабировании на примере
типичного растущего web-проекта, однако описанные здесь принципы подходят и для
других областей применения. Сначала мы рассмотрим архитектуру проекта и простое
распределение ее составных частей на несколько серверов, а затем поговорим о
масштабировании вычислений и данных.
Типичная архитектура сайта
Жизнь типичного сайта начинается с очень простой архитектуры
— это один web-сервер (обычно в его роли выступает Apache),
который занимается всей работой по обслуживанию HTTP-запросов,
поступающих от посетителей. Он отдает клиентам так называемую «статику», то
есть файлы, лежащие на диске сервера и не требующие обработки: картинки (gif,
jpg, png), листы стилей (css), клиентские скрипты (js, swf). Тот же сервер
отвечает на запросы, требующие вычислений — обычно это формирование
html-страниц, хотя иногда «на лету» создаются и изображения и другие документы.
Чаще всего ответы на такие запросы формируются скриптами, написанными на php,
perl или других языках.
Минус такой простой схемы работы в том, что разные по
характеру запросы (отдача файлов с диска и вычислительная работа скриптов)
обрабатываются одним и тем же web-сервером. Вычислительные запросы требуют
держать в памяти сервера много информации (интерпретатор скриптового языка,
сами скрипты, данные, с которыми они работают) и могут занимать много
вычислительных ресурсов. Выдача статики, наоборот, требует мало ресурсов
процессора, но может занимать продолжительное время, если у клиента низкая
скорость связи. Внутреннее устройство сервера Apache предполагает, что каждое
соединение обрабатывается отдельным процессом. Это удобно для работы скриптов,
однако неоптимально для обработки простых запросов. Получается, что тяжелые (от
скриптов и прочих данных) процессы Apache много времени проводят в ожидании (сначала при получении
запроса, затем при отправке ответа), впустую занимая память сервера.
Решение этой проблемы — распределение работы по обработке
запросов между двумя разными программами — т.е. разделение на frontend и
backend. Легкий frontend-сервер выполняет задачи по отдаче статики, а остальные
запросы перенаправляет (проксирует) на backend, где выполняется формирование
страниц. Ожидание медленных клиентов также берет на себя frontend, и если он использует
мультиплексирование (когда один процесс обслуживает нескольких клиентов — так
работают, например, nginx или lighttpd), то ожидание практически ничего не
стоит.
Из других компонент сайта следует отметить базу данных, в
которой обычно хранятся основные данные системы — тут наиболее популярны
бесплатные СУБД MySQL и PostgreSQL. Часто отдельно выделяется хранилище
бинарных файлов, где содержатся картинки (например, иллюстрации к статьям
сайта, аватары и фотографии пользователей) или другие файлы.
Таким образом, мы получили схему архитектуры, состоящую из
нескольких компонент.
Обычно в начале жизни сайта все компоненты архитектуры
располагаются на одном сервере. Если он перестает справляться с нагрузкой, то
есть простое решение — вынести наиболее легко отделяемые части на другой
сервер. Проще всего начать с базы данных — перенести ее на отдельный сервер и
изменить реквизиты доступа в скриптах. Кстати, в этот момент мы сталкиваемся с
важностью правильной архитектуры программного кода. Если работа с базой данных
вынесена в отдельный модуль, общий для всего сайта — то исправить параметры
соединения будет просто.
Пути дальнейшего разделения компонент тоже понятны — например, можно вынести frontend на отдельный сервер. Но обычно frontend
требует мало системных ресурсов и на этом этапе его вынос не даст существенного
прироста производительности. Чаще всего сайт упирается в производительность
скриптов — формирование ответа (html-страницы) занимает слишком долгое время.
Поэтому следующим шагом обычно является масштабирование backend-сервера.
Распределение вычислений
Типичная ситуация для растущего сайта — база данных уже
вынесена на отдельную машину, разделение на frontend и backend выполнено,
однако посещаемость продолжает увеличиваться и backend не успевает обрабатывать
запросы. Это значит, что нам необходимо распределить вычисления на несколько
серверов. Сделать это просто — достаточно купить второй сервер и поставить на
него программы и скрипты, необходимые для работы backend.
После этого надо сделать так, чтобы запросы пользователей распределялись
(балансировались) между полученными серверами. О разных способах балансировки
будет сказано ниже, пока же отметим, что обычно этим занимается frontend,
который настраивают так, чтобы он равномерно распределял запросы между
серверами.
Важно, чтобы все backend-серверы были способны правильно
отвечать на запросы. Обычно для этого необходимо, чтобы каждый из них работал с
одним и тем же актуальным набором данных. Если мы храним всю информацию в единой
базе данных, то СУБД сама обеспечит совместный доступ и согласованность данных.
Если же некоторые данные хранятся локально на сервере (например, php-сессии
клиента), то стоит подумать о переносе их в общее хранилище, либо о более
сложном алгоритме распределения запросов.
Распределить по нескольким серверам можно не только работу
скриптов, но и вычисления, производимые базой данных. Если СУБД выполняет много
сложных запросов, занимая процессорное время сервера, можно создать несколько
копий базы данных на разных серверах. При этом возникает вопрос синхронизации
данных при изменениях, и здесь применимы несколько подходов.
- Синхронизация на уровне приложения. В этом случае наши
скрипты самостоятельно записывают изменения на все копии базы данных (и сами несут
ответственность за правильность данных). Это не лучший вариант, поскольку он
требует осторожности при реализации и весьма неустойчив к ошибкам.
- Репликация — то есть автоматическое тиражирование
изменений, сделанных на одном сервере, на все остальные сервера. Обычно при
использовании репликации изменения записываются всегда на один и тот же сервер — его называют master, а остальные копии — slave. В большинстве СУБД есть
встроенные или внешние средства для организации репликации. Различают
синхронную репликацию — в этом случае запрос на изменение данных будет ожидать,
пока данные будут скопированы на все сервера, и лишь потом завершится успешно — и асинхронную — в этом случае изменения копируются на slave-сервера с
задержкой, зато запрос на запись завершается быстрее.
- Multi-master репликация. Этот подход аналогичен
предыдущему, однако тут мы можем производить изменение данных, обращаясь не к
одному определенному серверу, а к любой копии базы. При этом изменения
синхронно или асинхронно попадут на другие копии. Иногда такую схему называют
термином «кластер базы данных».
Возможны разные варианты распределения системы по серверам.
Например, у нас может быть один сервер базы данных и несколько backend (весьма
типичная схема), или наоборот — один backend и несколько БД. А если мы масштабируем
и backend-сервера, и базу данных, то можно объединить backend и копию базы на
одной машине. В любом случае, как только у нас появляется несколько экземпляров
какого-либо сервера, возникает вопрос, как правильно распределить между ними
нагрузку.
Методы балансировки
Пусть мы создали несколько серверов (любого назначения — http, база данных и т.п.), каждый из которых может обрабатывать запросы. Перед
нами встает задача — как распределить между ними работу, как узнать, на какой
сервер отправлять запрос? Возможны два основных способа распределения запросов.
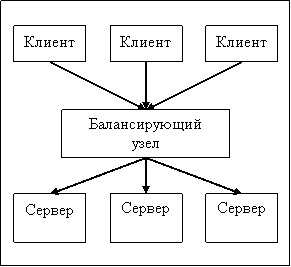
- Балансирующий узел. В этом случае клиент шлет запрос на один
фиксированный, известный ему сервер, а тот уже перенаправляет запрос на один из
рабочих серверов. Типичный пример — сайт с одним frontend и несколькими
backend-серверами, на которые проксируются запросы. Однако «клиент» может
находиться и внутри нашей системы — например, скрипт может слать запрос к
прокси-серверу базы данных, который передаст запрос одному из серверов СУБД.
Сам балансирующий узел может работать как на отдельном сервере, так и на одном
из рабочих серверов.
Преимущества этого подхода в том,
что клиенту ничего не надо знать о внутреннем устройстве системы — о количестве
серверов, об их адресах и особенностях — всю эту информацию знает только
балансировщик. Однако недостаток в том, что балансирующий узел является единой
точкой отказа системы — если он выйдет из строя, вся система окажется
неработоспособна. Кроме того, при большой нагрузке балансировщик может просто перестать
справляться со своей работой, поэтому такой подход применим не всегда.
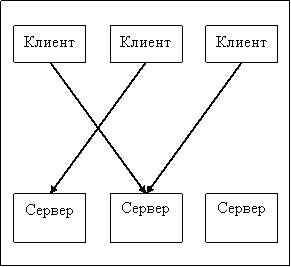
- Балансировка на стороне клиента. Если мы хотим избежать
единой точки отказа, существует альтернативный вариант — поручить выбор сервера
самому клиенту. В этом случае клиент должен знать о внутреннем устройстве нашей
системы, чтобы уметь правильно выбирать, к какому серверу обращаться.
Несомненным плюсом является отсутствие точки отказа — при отказе одного из
серверов клиент сможет обратиться к другим. Однако платой за это является
усложнение логики клиента и меньшая гибкость балансировки.
Разумеется, существуют и комбинации этих подходов. Например,
такой известный способ распределения нагрузки, как DNS-балансировка, основан на
том, что при определении IP-адреса сайта клиенту выдается
адрес одного из нескольких одинаковых серверов. Таким образом, DNS выступает в
роли балансирующего узла, от которого клиент получает «распределение». Однако
сама структура DNS-серверов предполагает отсутствие точки отказа за счет
дублирования — то есть сочетаются достоинства двух подходов. Конечно, у такого
способа балансировки есть и минусы — например, такую систему сложно динамически
перестраивать.
Работа с сайтом обычно не ограничивается одним запросом.
Поэтому при проектировании важно понять, могут ли последовательные запросы
клиента быть корректно обработаны разными серверами, или клиент должен быть
привязан к одному серверу на время работы с сайтом. Это особенно важно, если на
сайте сохраняется временная информация о сессии работы пользователя (в этом
случае тоже возможно свободное распределение — однако тогда необходимо хранить
сессии в общем для всех серверов хранилище). «Привязать» посетителя к
конкретному серверу можно по его IP-адресу (который, однако, может меняться),
или по cookie (в которую заранее записан идентификатор сервера), или даже
просто перенаправив его на нужный домен.
С другой стороны, вычислительные сервера могут быть и не равноправными.
В некоторых случаях выгодно поступить наоборот, выделить отдельный сервер для
обработки запросов какого-то одного типа — и получить вертикальное разделение
функций. Тогда клиент или балансирующий узел будут выбирать сервер в
зависимости от типа поступившего запроса. Такой подход позволяет отделить
важные (или наоборот, не критичные, но тяжелые) запросы от остальных.
Распределение данных
Мы научились распределять вычисления, поэтому большая
посещаемость для нас не проблема. Однако объемы данных продолжают расти,
хранить и обрабатывать их становится все сложнее — а значит, пора строить
распределенное хранилище данных. В этом случае у нас уже не будет одного или
нескольких серверов, содержащих полную копию базы данных. Вместо этого, данные
будут распределены по разным серверам. Какие возможны схемы распределения?
- Вертикальное распределение (vertical partitioning) — в простейшем случае
представляет собой вынесение отдельных таблиц базы данных на другой сервер. При
этом нам потребуется изменить скрипты, чтобы обращаться к разным серверам за
разными данными. В пределе мы можем хранить каждую таблицу на отдельном сервере
(хотя на практике это вряд ли будет выгодно). Очевидно, что при таком
распределении мы теряем возможность делать SQL-запросы, объединяющие данные из
двух таблиц, находящихся на разных серверах. При необходимости можно реализовать
логику объединения в приложении, но это будет не столь эффективно, как в СУБД.
Поэтому при разбиении базы данных нужно проанализировать связи между таблицами,
чтобы разносить максимально независимые таблицы.
Более сложный случай
вертикального распределения базы — это декомпозиция одной таблицы, когда часть
ее столбцов оказывается на одном сервере, а часть — на другом. Такой прием
встречается реже, но он может использоваться, например, для отделения маленьких
и часто обновляемых данных от большого объема редко используемых.
- Горизонтальное распределение (horizontal partitioning) — заключается в
распределении данных одной таблицы по нескольким серверам. Фактически, на
каждом сервере создается таблица такой же структуры, и в ней хранится
определенная порция данных. Распределять данные по серверам можно по разным
критериям: по диапазону (записи с id < 100000 идут на сервер А, остальные — на сервер Б), по списку значений (записи типа «ЗАО» и «ОАО» сохраняем на сервер
А, остальные — на сервер Б) или по значению хэш-функции от некоторого поля
записи. Горизонтальное разбиение данных позволяет хранить неограниченное
количество записей, однако усложняет выборку. Наиболее эффективно можно выбирать
записи только когда известно, на каком сервере они хранятся.
Для выбора правильной схемы распределения данных необходимо
внимательно проанализировать структуру базы. Существующие таблицы (и, возможно,
отдельные поля) можно классифицировать по частоте доступа к записям, по частоте
обновления и по взаимосвязям (необходимости делать выборки из нескольких
таблиц).
Как упоминалось выше, кроме базы данных сайту часто требуется
хранилище для бинарных файлов. Распределенные системы хранения файлов
(фактически, файловые системы) можно разделить на два класса.
- Работающие на уровне операционной системы. При этом для
приложения работа с файлами в такой системе не отличается от обычной работы с
файлами. Обмен информацией между серверами берет на себя операционная система.
В качестве примеров таких файловых систем можно привести давно известное
семейство NFS или менее известную, но более современную систему Lustre.
- Реализованные на уровне приложения распределенные
хранилища подразумевают, что работу по обмену информацией производит само
приложение. Обычно функции работы с хранилищем для удобства вынесены в
отдельную библиотеку. Один из ярких примеров такого хранилища — MogileFS, разработанная
создателями LiveJournal. Другой распространенный пример — использование
протокола WebDAV и поддерживающего его хранилища.
Надо отметить, что распределение данных решает не только
вопрос хранения, но и частично вопрос распределения нагрузки — на каждом
сервере становится меньше записей, и потому обрабатываются они быстрее.
Сочетание методов распределения вычислений и данных позволяет построить
потенциально неограниченно-масштабируемую архитектуру, способную работать с
любым количеством данных и любыми нагрузками.
Выводы
Подводя итог сказанному, сформулируем выводы в виде кратких тезисов.
- Две основные (и связанные между собой) задачи масштабирования — это распределение вычислений и распределение данных
- Типичная архитектура сайта подразумевает разделение ролей и
включает frontend, backend, базу данных и иногда хранилище файлов
- При небольших объемах данных и больших нагрузках применяют
зеркалирование базы данных — синхронную или асинхронную репликацию
- При больших объемах данных необходимо распределить базу данных — разделить
ее вертикально или горизонтально
- Бинарные файлы хранятся в распределенных файловых системах
(реализованных на уровне ОС или в приложении)
- Балансировка (распределение запросов) может быть равномерная или
с разделением по функционалу; с балансирующим узлом, либо на стороне клиента
- Правильное сочетание методов позволит держать любые нагрузки ;)
Ссылки
Продолжить изучение этой темы можно на интересных англоязычных сайтах и блогах:
- http://www.highscalability.com/
- http://www.royans.net/arch/
- http://poorbuthappy.com/ease/… -bloglines-vox-and-more
- http://www.possibility.com/epowiki/Wiki.jsp?page=Scalability
P.S. Комментарии, конечно, приветствуются ;)
