Вступление
Как справедливо заметил Fred Brooks, серебряной пули, способной поразить зверя разработки программного обеспечения, не существует. Пока возникают новые требования, идеи и находятся новые баги, программы живут и изменяются. Путь, который проходит код от версии к версии, может быть крайне сложен и извилист. К его созданию причастно много людей: разработчики, тестировщики, бизнес-аналитики, заказчики и т.п. Несмотря на то, что существует много разных видов разработки – аутсорсинг, продуктовая разработка, open-source и т.п., проблемы, стоящие перед командой, остаются примерно одинаковыми. Программное обеспечение – вещь сложная, потребитель хочет получить его как можно быстрее (и дешевле). Качество при этом должно быть приемлемым. Перед командой разработки стоит серьезная задача – наладить эффективное взаимодействие. Одним из самых главных средств коллаборации внутри команды разработчиков является сам код, который они пишут.
В данный момент на рынке получают широкое распространение распределенные системы управления версиями – DVCS. Однако, львиную долю рынка удерживают традиционные и более простые в использовании централизованные системы, такие, как, например, SVN. Система управления версиями, а вернее, ее грамотное использование, играет ключевую роль в обеспечении эффективного взаимодействия. Вспомните, как давно вы читали книгу про свою VCS? Команде, в которой нет людей, способных выстроить грамотное взаимодействие через VCS, исходя из потребностей проекта, не позавидуешь.
Управление релизами
Давайте представим себе идеальное управление релизами. Релиз-менеджер может оценить состояние кода и выбрать реализованный функционал для включения в релиз. Этот функционал должен быть готов и протестирован. Также релиз-менеджер может включить исправления дефектов с прошлого релиза. Неготовый, нестабильный и непротестированный функционал в релиз попасть не должен. Если от QA-специалистов поступает информация о нестабильности того или иного функционала, релиз-менеджер должен иметь возможность убрать его из релиза. Часто возникает потребность в переносе исправлений дефектов на уже работающую у конечного пользователя версию, потому что он по каким-то причинам не может перейти на новую.
Если немного сменить точку зрения и посмотреть на процесс работы над кодом со стороны разработчика, то он должен сидеть в своей песочнице и не подвергаться влиянию дестабилизирующих коммитов со стороны коллег. В идеале, разработчики должны обмениваться только законченными и стабильными наборами изменений. Так ведь проще понять что было сделано, правда? Тем не менее, коммиты не должны диктовать разработчику стиль его работы, и он всегда должен иметь возможность вкомитить только частично выполненный функционал.
Описанные выше проблемы имеют несколько решений. Одно из них – правильный выбор и грамотное использование проектной системы управления версиями. Еще одно – понимание возможных стратегий бранчинга (ветвления) и цены, которую придется заплатить за всю эту роскошь.
Использование бранчинга позволяет нам убить двух зайцев одним махом: выполнять стабилизацию релизной версии (процесс более известный как багфиксинг) и одновременно осуществлять расширение приложения новым функционалом для следующего релиза. Это два основных, хотя и не единственных, способа использования бранчинга на проекте.
Отступление про версионность кода
Как правило, системы управления версиями хранят историю изменений в виде линии (централизованные) или графа (распределенные). Ветка (бранч) – это просто линия разработки кода, которая имеет общую историю с другими ветками и существует параллельно с ними. Jeff Atwood в своем блоге сравнивает ветки с параллельными вселенными. В такой вселенной в какой-то момент история пошла по-другому относительно других. Это дает нам безграничные возможности, которые уравновешиваются безграничной сложностью наших вселенных.
Как правило, одна из наших историй является основной и носит гордое имя trunk или mainline. По аналогии с деревом, от нее отходят другие ветки. В эту ветку рано или поздно попадает готовый (или не совсем) функционал и исправления ошибок.
Branch per release
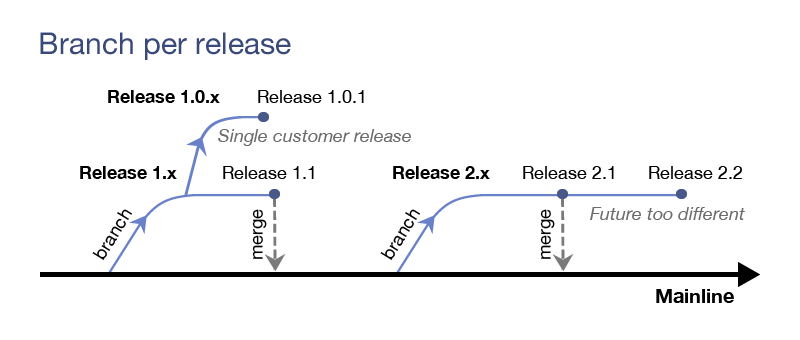
Рассмотрим первый из этих случаев, когда отдельная ветка создается под каждый релиз. Это делается для того, чтобы исправлять дефекты, найденные после выпуска релиза или во время его тестирования. Этот процесс обычно называется стабилизацией. При этом сами исправления (багфиксы) не остаются только в релизных ветках, а переносятся в mainline (если история релиза и mainline не слишком разошлись), делая ее стабильнее. Код в релизной ветке изолирован от дестабилизирующего влияния разработки нового функционала и при этом не блокирует ее. Сама по себе релизная ветка предоставляет легкую возможность осуществлять поддержку релизной версии. Когда прекращается поддержка релиза, его ветка замораживается. А пока идет проект, mainline продолжает свое развитие, являясь точкой, в которой накапливается новый функционал для следующих релизов.
Таким же образом можно осуществлять поддержку релизов для разных заказчиков, выделяя по ветке для каждого, если по каким-то причинам им нельзя поставить одну и ту же версию. Хочу отметить, что поддержка разных вариаций одной и той же версии — задача трудоемкая и ее следует избегать по мере возможности.
Branch per feature
Следующий случай — это выделение отдельной ветки для разработки нового функционала. Как правило, это одна логически законченная функциональная область, или просто feature. Новый функционал объединяется с основной веткой только после полного завершения, что позволяет избежать негативного влияния незавершенной работы на другие линии разработки. После того как новый функционал готов и объединен с основной веткой, другие ветки разработки должны быть интегрированы с mainline, чтобы не накапливался эффект отложенной интеграции. Использование веток для релизов и разработки позволяет нам не ждать, пока окончится тестирование и стабилизация релиза, а сразу приступить к разработке функционала для следующего.
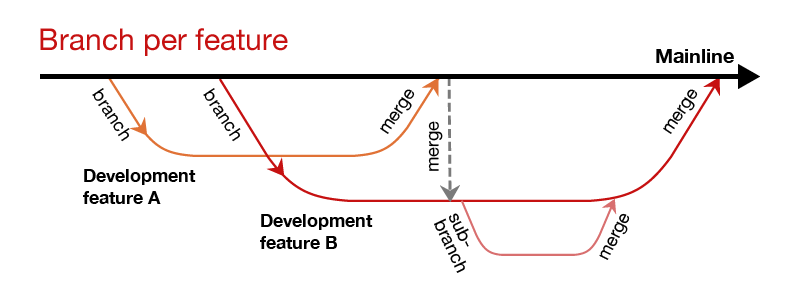
Также можно создавать sub-branches для релизных и девелоперских веток, если нужны еще уровни изоляции. Во всех случаях создания новой ветки следует понимать цену ее поддержки, о чем будет упомянуто немного позже.
Интеграция между ветками
Основная ветка (mainline, trunk) является главным местом интеграции при помощи кода. Так или иначе, все изменения, сделанные разработчиками, попадают сюда. Тем не менее, она не должна превращаться в свалку нестабильного и незаконченного кода. Именно поэтому разработку новых фич рекомендуется проводить в отдельной ветке, интегрировать с основной, тестировать и только потом объединять изменения. Иными словами, mainline должна содержать достаточно законченный код, который может послужить основой для стабилизационной релизной ветки. Также, багфиксы из релизных веток, пройдя через mainline, попадают в ветки для разработки, таким образом, работа ведется над более стабильным кодом. Хорошим правилом является то, что мы не должны отдавать нестабильные изменения в другие ветки и что мы должны принимать стабильные изменения из других веток.
Рассмотрим ситуацию, отображенную на картинке:
При оценке плюсов и минусов такого подхода, следует принимать во внимание:
Интеграция через Mainline не является единственным способом интегрироваться – возможна интеграция напрямую между ветками. Martin Fowler называет такой способ Promiscuous Integration. Для такого метода интеграции очень важна коммуникация внутри проектной команды.
Стабильность веток
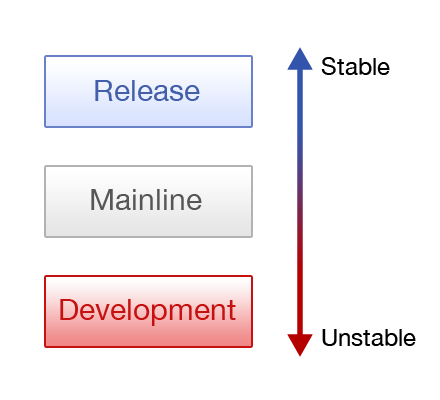
У такой модели есть градация стабильности, где самыми стабильными являются релизные ветки, менее стабильной является mainline, и самыми нестабильными являются ветки для разработки. Как правило, на диаграммах самые стабильные ветки отображаются выше всех, а нестабильные – ниже всех.
Накладные расходы, связанные с использованием бранчинга
С бранчингом связаны следующие издержки:
Типы зависимостей между ветками и способы их решения
Между ветками могут возникать следующие зависимости:
Существует несколько типовых решений для работы с таким зависимостями:
Заключение
Важно понимать, что грамотный модульный дизайн приложения может сильно уменьшить или свести на нет необходимость использования бранчинга и является мощным инструментом для решения проблем, связанных с параллельной разработкой.
Бранчинг позволяет нам одновременно вести два вида разработки: стабилизацию и реализацию нового функционала. Однако, это не единственный способ его применения. Например, отдельные ветки могут выделяться для разделения итераций или для изоляции разных команд.
Правильный выбор стратегии бранчинга зависит от потребностей проекта и возможностей/ограничений используемой системы управления версиями (которую, впрочем, никто не запрещает сменить). Ограничения реального мира, которые накладываются на процесс, часто невозможно решить без возможности осуществления паралелльной разработки. Тем не менее, неграмотное понимание и использование бранчинга часто приводит к анти-паттернам, которые и завершают этот материал.
Анти-паттерны бранчинга:
Как справедливо заметил Fred Brooks, серебряной пули, способной поразить зверя разработки программного обеспечения, не существует. Пока возникают новые требования, идеи и находятся новые баги, программы живут и изменяются. Путь, который проходит код от версии к версии, может быть крайне сложен и извилист. К его созданию причастно много людей: разработчики, тестировщики, бизнес-аналитики, заказчики и т.п. Несмотря на то, что существует много разных видов разработки – аутсорсинг, продуктовая разработка, open-source и т.п., проблемы, стоящие перед командой, остаются примерно одинаковыми. Программное обеспечение – вещь сложная, потребитель хочет получить его как можно быстрее (и дешевле). Качество при этом должно быть приемлемым. Перед командой разработки стоит серьезная задача – наладить эффективное взаимодействие. Одним из самых главных средств коллаборации внутри команды разработчиков является сам код, который они пишут.
В данный момент на рынке получают широкое распространение распределенные системы управления версиями – DVCS. Однако, львиную долю рынка удерживают традиционные и более простые в использовании централизованные системы, такие, как, например, SVN. Система управления версиями, а вернее, ее грамотное использование, играет ключевую роль в обеспечении эффективного взаимодействия. Вспомните, как давно вы читали книгу про свою VCS? Команде, в которой нет людей, способных выстроить грамотное взаимодействие через VCS, исходя из потребностей проекта, не позавидуешь.
Управление релизами
Давайте представим себе идеальное управление релизами. Релиз-менеджер может оценить состояние кода и выбрать реализованный функционал для включения в релиз. Этот функционал должен быть готов и протестирован. Также релиз-менеджер может включить исправления дефектов с прошлого релиза. Неготовый, нестабильный и непротестированный функционал в релиз попасть не должен. Если от QA-специалистов поступает информация о нестабильности того или иного функционала, релиз-менеджер должен иметь возможность убрать его из релиза. Часто возникает потребность в переносе исправлений дефектов на уже работающую у конечного пользователя версию, потому что он по каким-то причинам не может перейти на новую.
Если немного сменить точку зрения и посмотреть на процесс работы над кодом со стороны разработчика, то он должен сидеть в своей песочнице и не подвергаться влиянию дестабилизирующих коммитов со стороны коллег. В идеале, разработчики должны обмениваться только законченными и стабильными наборами изменений. Так ведь проще понять что было сделано, правда? Тем не менее, коммиты не должны диктовать разработчику стиль его работы, и он всегда должен иметь возможность вкомитить только частично выполненный функционал.
Описанные выше проблемы имеют несколько решений. Одно из них – правильный выбор и грамотное использование проектной системы управления версиями. Еще одно – понимание возможных стратегий бранчинга (ветвления) и цены, которую придется заплатить за всю эту роскошь.
Использование бранчинга позволяет нам убить двух зайцев одним махом: выполнять стабилизацию релизной версии (процесс более известный как багфиксинг) и одновременно осуществлять расширение приложения новым функционалом для следующего релиза. Это два основных, хотя и не единственных, способа использования бранчинга на проекте.
Отступление про версионность кода
Как правило, системы управления версиями хранят историю изменений в виде линии (централизованные) или графа (распределенные). Ветка (бранч) – это просто линия разработки кода, которая имеет общую историю с другими ветками и существует параллельно с ними. Jeff Atwood в своем блоге сравнивает ветки с параллельными вселенными. В такой вселенной в какой-то момент история пошла по-другому относительно других. Это дает нам безграничные возможности, которые уравновешиваются безграничной сложностью наших вселенных.
Как правило, одна из наших историй является основной и носит гордое имя trunk или mainline. По аналогии с деревом, от нее отходят другие ветки. В эту ветку рано или поздно попадает готовый (или не совсем) функционал и исправления ошибок.
Branch per release
Рассмотрим первый из этих случаев, когда отдельная ветка создается под каждый релиз. Это делается для того, чтобы исправлять дефекты, найденные после выпуска релиза или во время его тестирования. Этот процесс обычно называется стабилизацией. При этом сами исправления (багфиксы) не остаются только в релизных ветках, а переносятся в mainline (если история релиза и mainline не слишком разошлись), делая ее стабильнее. Код в релизной ветке изолирован от дестабилизирующего влияния разработки нового функционала и при этом не блокирует ее. Сама по себе релизная ветка предоставляет легкую возможность осуществлять поддержку релизной версии. Когда прекращается поддержка релиза, его ветка замораживается. А пока идет проект, mainline продолжает свое развитие, являясь точкой, в которой накапливается новый функционал для следующих релизов.
Таким же образом можно осуществлять поддержку релизов для разных заказчиков, выделяя по ветке для каждого, если по каким-то причинам им нельзя поставить одну и ту же версию. Хочу отметить, что поддержка разных вариаций одной и той же версии — задача трудоемкая и ее следует избегать по мере возможности.
Branch per feature
Следующий случай — это выделение отдельной ветки для разработки нового функционала. Как правило, это одна логически законченная функциональная область, или просто feature. Новый функционал объединяется с основной веткой только после полного завершения, что позволяет избежать негативного влияния незавершенной работы на другие линии разработки. После того как новый функционал готов и объединен с основной веткой, другие ветки разработки должны быть интегрированы с mainline, чтобы не накапливался эффект отложенной интеграции. Использование веток для релизов и разработки позволяет нам не ждать, пока окончится тестирование и стабилизация релиза, а сразу приступить к разработке функционала для следующего.
Также можно создавать sub-branches для релизных и девелоперских веток, если нужны еще уровни изоляции. Во всех случаях создания новой ветки следует понимать цену ее поддержки, о чем будет упомянуто немного позже.
Интеграция между ветками
Основная ветка (mainline, trunk) является главным местом интеграции при помощи кода. Так или иначе, все изменения, сделанные разработчиками, попадают сюда. Тем не менее, она не должна превращаться в свалку нестабильного и незаконченного кода. Именно поэтому разработку новых фич рекомендуется проводить в отдельной ветке, интегрировать с основной, тестировать и только потом объединять изменения. Иными словами, mainline должна содержать достаточно законченный код, который может послужить основой для стабилизационной релизной ветки. Также, багфиксы из релизных веток, пройдя через mainline, попадают в ветки для разработки, таким образом, работа ведется над более стабильным кодом. Хорошим правилом является то, что мы не должны отдавать нестабильные изменения в другие ветки и что мы должны принимать стабильные изменения из других веток.
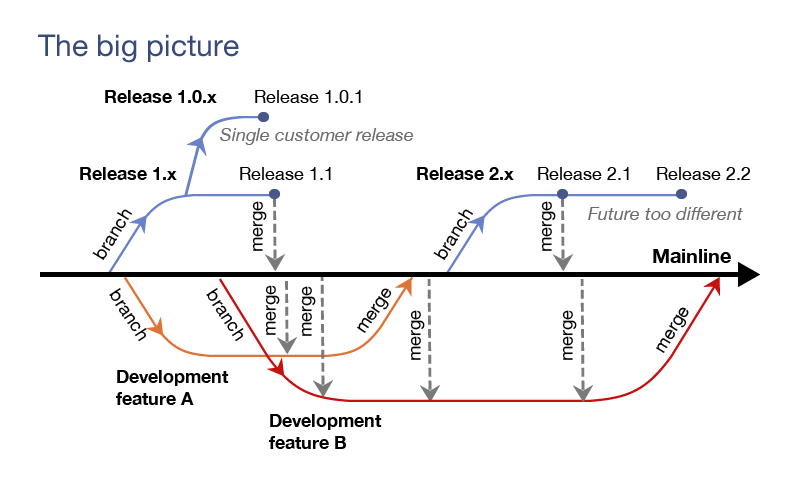
Рассмотрим ситуацию, отображенную на картинке:
- В какой то момент в Mainline накопилось достаточное количество законченного функционала для выпуска Release 1.x. Для него была создана ветка, и после тестирования и стабилизации релиз ушел заказчикам.
- Параллельно с этим стартовала разработка нового функционала:feature A и feature B, – каждая на своей ветке.
- Баги, найденные закзачиками в Release 1.0, были исправлены на релизной ветке, и был выпущен Release 1.1. Багфиксы из него были объединены с Mainline, откуда попали в ветки для feature A и feature B. Таким образом, работа велась над более стабильным кодом.
- Один из заказчиков по своим причинам не смог перейти на версию 1.1 и столкнулся с рядом специфичных для себя дефектов. Это было исправлено на специально сделанной для него ветке – Release 1.0.x.
- Была закончена разработка feature A, и, после интеграции и тестирования, эти законченные изменения попали в Mainline. Ветка для feature B получает эти изменения сразу после их попадания в Mainline, чтобы работа велась над максимально актуальной версией кода.
- Принимается решение о выпуске нового Release 2.x, включающего feature A, и для него создается ветка, на которой осуществляется сервис этого релиза, – 2.1, 2.2. Причем, багфиксы для релизной версии 2.2 не объединяются с Mainline, так как истории этих линий разработки кода уже слишком разошлись.
При оценке плюсов и минусов такого подхода, следует принимать во внимание:
- Feature branches не стоят на пути Continuous Integration
- Семантические конфликты не являются специфичными исключительно для бранчинга
- Feature toggling и Branch-by-abstraction имеют ряд своих недостатков по сравнению с Feature branches.
Интеграция через Mainline не является единственным способом интегрироваться – возможна интеграция напрямую между ветками. Martin Fowler называет такой способ Promiscuous Integration. Для такого метода интеграции очень важна коммуникация внутри проектной команды.
Стабильность веток
У такой модели есть градация стабильности, где самыми стабильными являются релизные ветки, менее стабильной является mainline, и самыми нестабильными являются ветки для разработки. Как правило, на диаграммах самые стабильные ветки отображаются выше всех, а нестабильные – ниже всех.
Накладные расходы, связанные с использованием бранчинга
С бранчингом связаны следующие издержки:
- Механические – это те действия, которые нужно совершить, чтобы создать ветку, переключиться с ветки на ветку, объединить (merge) изменения и т.п. Как правило, такие действия трудоемки для централизованных систем и относительно просты для децентрализованных.
- Интеллектуальные – это те усилия, которые приходится приложить, чтобы держать в голове все существующие ветки и их предназначение. Как правило, существуют инструменты, которые облегчают эту задачу. Сюда можно отнести кривую обучения для сотрудников, связанную с освоением системы управления версиями.
- Цена за тестирование – использование параллельной разработки способно серьезно увеличить цену ручного тестирования. Отложенное тестирование позволяет сократить расходы, но при этом имеет ряд своих недостатков. Любое автоматическое тестирование значительно уменьшает цену тестирования при использовании бранчинга. В целом, этот пункт зависит от стратегии тестирования, принятой на проекте.
Типы зависимостей между ветками и способы их решения
Между ветками могут возникать следующие зависимости:
- Архитектурные – если мы меняем архитектуру на одной ветке, другие ветки могут зависеть от этих изменений.
- Функциональные – некоторая новая функциональность не может быть закончена или не имеет особой ценности, пока не будет закончен другой функционал, от которого она зависит.
- Зависимости от исправления дефектов – в случае исправления дефекта на одной ветке, может существовать несколько веток, которые должны получить это изменение.
Существует несколько типовых решений для работы с таким зависимостями:
- Саб-бранчинг – зависимая функциональность реализуется в отдельном саб-бранче и потом объединяется со всеми заинтересованными ветками.
- Остановка – разработка на ветке замораживается, пока не будет готова нужная функциональность.
- Архитектурная абстракция – путем абстракции в системе создаются границы, которые изолируют разные части функциональности. В этом случае проблема решается не только на уровне системы управления версиями, но и на уровне дизайна приложения.
- Использование заглушек – в системе используются fakes/stubs, которые заменяются на реальный функционал по мере его готовности.
- Релиз, патч, ре-релиз – система выпускается в не полностью готовом виде и патчами доводится до совершенства (эту практику в некоторых отраслях принято называть платным бета-тестированием).
Заключение
Важно понимать, что грамотный модульный дизайн приложения может сильно уменьшить или свести на нет необходимость использования бранчинга и является мощным инструментом для решения проблем, связанных с параллельной разработкой.
Бранчинг позволяет нам одновременно вести два вида разработки: стабилизацию и реализацию нового функционала. Однако, это не единственный способ его применения. Например, отдельные ветки могут выделяться для разделения итераций или для изоляции разных команд.
Правильный выбор стратегии бранчинга зависит от потребностей проекта и возможностей/ограничений используемой системы управления версиями (которую, впрочем, никто не запрещает сменить). Ограничения реального мира, которые накладываются на процесс, часто невозможно решить без возможности осуществления паралелльной разработки. Тем не менее, неграмотное понимание и использование бранчинга часто приводит к анти-паттернам, которые и завершают этот материал.
Анти-паттерны бранчинга:
- Merge Paranoia – разработчики боятся объединять код, поэтому накапливается негативный эффект отложенной интеграции.
- Merge Mania – разработчики больше времени тратят на объединение изменений, чем на разработку.
- Big Bang Merge – ветки не обмениваются законченными изменениями, поэтому происходит одно гигантское объединение в конце.
- Never-Ending Merge – объединение никогда не останавливается, так как всегда есть что объединять.
- Wrong Way Merge – объединение более поздней ветки разработки с более ранней версией.
- Branch Mania – создание большого количества веток без нужной на то причины.
- Cascading Branches – создание веток без объединения их с mainline в конце разработки.
- Mysterious Branches – создание ветки без причины.
- Теmporary Branches – создание ветки с изменяющейся причиной ее существования: ветка становится временным рабочим пространством.
- Volatile Branches – старт ветки в нестабильном состоянии или перенос нестабильных изменений в другие ветки.
- Development Freeze – остановка всей разработки для создания веток, объединения или создания релизов.
- Berlin Wall – использование веток для разделения людей в команде, вместо разделения областей, над которыми они работают.
