Comments 23
Если хэш 32-х битный, то нужно 0.5 Гб памяти? И это без счётчика. Вы хэши какой длины использовали?
Для 10^7 элементов и вероятности ложного срабатывания 1% оптимально иметь 7 хэшей при массиве в 95 Mbit. Займёт такой массив 12 МБ (без счетчиков) и заполнен он будет примерно на 50%. Если брать 27-битные хэши (массив в 16MiB), то их оптимально взять 9 штук и вероятность ложного срабатывания будет около 0.16%.
Поправьте, если я чего-то не понял.
Количество хеш-функций определяется из 2-х условий: количества объектов в выборке и вероятности «ложноположительного» срабатывания. Mrrl прав. Число хеш-функций крайне мало по сравнению с количеством объектов. И основную память занимает как раз битовая строка.
Хеш функция приведена в тексте:
Количество хеш-функций определяется из 2-х условий: количества объектов в выборке и вероятности «ложноположительного» срабатывания. Mrrl прав. Число хеш-функций крайне мало по сравнению с количеством объектов. И основную память занимает как раз битовая строка.
Хеш функция приведена в тексте:
abs( crc32( md5($this->seed[0] . $string) ) ) % $size;
На самом деле, даже количество объектов ни при чём. Важно лишь отношение длины битовой строки к этому количеству. Лучше всего это отношение брать около 1.5*h, где h — число хеш-функций, а последнее определять, исходя из желаемой вероятности ошибки (она будет около 0.5^h).
Ну это логично.
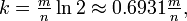

Тем более примеры потребления памяти в тексте приведены. Я просто не совсем понял, что конкретно имел в виду Igorbek
Тем более примеры потребления памяти в тексте приведены. Я просто не совсем понял, что конкретно имел в виду Igorbek
Думаю, для тех, кто не очень в теме про блум-фильтры, или хочет почитать про выбор параметров, будет полезно почитать википедию вот в этом разделе: en.wikipedia.org/wiki/Bloom_filter#Probability_of_false_positives
Кажется, ваши формулы оттуда :)
Кажется, ваши формулы оттуда :)
Не знаю, знали ли вы об этом или нет, но в пхп для сетов лучше использовать ключи массивов. В принципе хеш-таблиц для этого достаточно обычно. Попробуйте сравнить свой фильтр и isset($array[«value»])
Что насчет скорости, я сомневаюсь что у вас будет настолько много данных, чтобы блум дал вам хороший выигрыш в производительности, хотя все может быть конечно, я подумываю имплементировать некоторые подобные структуры в расширении, пхп их не хватает да.
Что насчет скорости, я сомневаюсь что у вас будет настолько много данных, чтобы блум дал вам хороший выигрыш в производительности, хотя все может быть конечно, я подумываю имплементировать некоторые подобные структуры в расширении, пхп их не хватает да.

> Гугл применяет его в своем поисковом движке.
А! Так ведь это он не рекламу мне показывает, это просто ложно-положительные срабатывания! :)
А! Так ведь это он не рекламу мне показывает, это просто ложно-положительные срабатывания! :)
А можете провести ваш тест уникальности для MurMurHash2?
Да, можно. Под рукой был только Windows, поэтому было невозможно его проверить. Скоро выложу информацию.
Скорость не проверял, хотя уверен, что работает гораздо быстрее. Уникальность на уровне 62-64%. Есть подозрение, что это из-за использования crc32 в качестве преобразования строка -> число.
Вот код теста.
Вообще не вижу смысла использовать, даже если работает быстрее, т.к. тогда уже лучше использовать расширение фильтра Блума написанное на C. Но как дополнительный вариант можно добавить.
Вот код теста.
<?
$num = 2000;
$string = "some long string to test murmur unique";
$ar = array();
for($i=0; $i<$num; $i++) {
$ar[ abs( crc32( murmurhash3($string, rand(0, $num*60)) ) ) % $num ] = 1;
}
echo array_sum($ar)/$num, PHP_EOL;
?>
Вообще не вижу смысла использовать, даже если работает быстрее, т.к. тогда уже лучше использовать расширение фильтра Блума написанное на C. Но как дополнительный вариант можно добавить.
Попробуйте убрать abs( crc32 ()) — murmurhash3 и так int должен возвращать. murmurhash3 должен быть сильно быстрее md5.
Вы что, я бы не стал оставлять, если бы он возвращал число. Для меня была целая проблема найти хоть что-то хеширующее и возвращающее число.
Из Википедии
Из Википедии
The current version is MurmurHash3 which yields a 32-bit or 128-bit hash value.
Ну вот 32 бита — это как раз uint32_t. Я hashmurmur2 в плюсовом коде использую, и интерпретирую ответ именно как чиселку, сразу делю ей на количество хэш-бакетов. Не знаю, как именно сделано в php, поэтому не могу посоветовать, как с результатом работать.
Удивлен, не увидев в сравнении bloomy
А не могли бы вы пояснить, как работает этот «счетчик» с использованием алфавита?
Есть алфавит, к примеру '01234567890abcdef'
И вместо 1 производится инкремент по алфавиту. Т.е. если стоял символ 'b' после инкремента будет символ 'c', декремент (во время удаления) все делает наоборот.
Это не самое лучшее решение. У меня было другое, где значения отделялись знаком, к примеру запятой. Но оно было очень медленным.
И вместо 1 производится инкремент по алфавиту. Т.е. если стоял символ 'b' после инкремента будет символ 'c', декремент (во время удаления) все делает наоборот.
Это не самое лучшее решение. У меня было другое, где значения отделялись знаком, к примеру запятой. Но оно было очень медленным.
Sign up to leave a comment.
Фильтр Блума на PHP