
В 2009 году, на ежегодной научной конференции SIGMETRICS, группа исследователей, работавших в Университете Торонто с данными, собранными и предоставленными для изучения компанией Google, опубликовала крайне интересный документ "DRAM Errors in the Wild: A Large-Scale Field Study" посвященный статистике отказов в серверной оперативной памяти (DRAM). Хотя подобные исследования и проводились ранее (например исследование 2007 года, наблюдавшее парк в 300 компьютеров), это было первое исследование, охватившее такой значительный парк серверов, исчисляемый тысячами единиц, на протяжении свыше двух лет, и давшее столь всеобъемлющие статистические сведения.
Отмечу также, что та же группа исследователей, во главе с аспирантом, а ныне профессором Университета Торонто, Бианкой Шрёдер (Bianca Shroeder) ранее, в 2007 году публиковала не менее интересное исследование, посвященное статистике отказов жестких дисков в датацентрах Google (краткую популярную выжимку из работы Failure Trends in a Large Disk Drive Population (pdf 242 KB), если вам скучно читать весь отчет, можно найти здесь: http://blog.aboutnetapp.ru/archives/tag/google). Кроме того, их перу принадлежит еще несколько работ, в частности об влиянии температуры и охлаждении, и о статистике отказов в оперативной памяти, вызываемой, предположительно, космическими лучами высоких энергий. Ссылки на публикации можно найти на домашней странице Шрёдер, на сервере университета.
Кратко о том, как именно происходила сборка статистических данных. Дело в том, что на протяжении довольно продолжительного времени (в опубликованной работе проанализирован период около 2,5 лет), в датацентрах Google собираются разнообразные данные мониторинга и иных событий в жизни оборудования в большой базе, данные которой в дальнейшем можно анализировать за любой желаемый промежуток времени.

(на фото, кстати, подлинный вид серверной платформы Google, именно из таких «кирпичиков» собираются гугловские кластеры, размером в многие тысячи узлов, впрочем, про них тут уже писалось)
Результаты такого анализа и представлены в опубликованной работе. И результаты во многом удивительные, заставляющие по-иному смотреть на вопросы надежности и привычные допущения в области надежности серверного оборудования.
Исследование со всей убедительностью продемонстрировало, что влияние отказов в оперативной памяти существенно недооценивается, что отказы оперативной памяти случаются куда чаще, чем до этого это было принято считать, наконец, многие допущения, например что оперативная память практически не «стареет», как «стареют», повышая вероятность отказов, компоненты с движущимися частями, такие как, например, жесткие диски, или что перегрев губительно сказывается на работе ОЗУ, являются неверными, и требуют пересмотра.
Несомненно тот факт, что в последние несколько лет, в связи со сравнительным удешевлением DRAM, и широким распространением систем серверной виртуализации, крайне охочих до объемов памяти, концентрация в одной серверной системе все больших и больших объемов ОЗУ, повышает и требования к ее надежности.
Исследование показало, что примерно каждый третий сервер (или 8% модулей памяти) в наблюдаемых датацентрах на протяжении 2,5 лет исследования встречался со сбоем в оперативной памяти. Число сбоев, зарегистрированных системой мониторинга составило свыше 4000 в год! Большая часть из них конечно была устранена использованием ECC (Error Correction Code), используемого в оперативной памяти, и более сложными его вариантами, такими как Chipkill (позволяет устранить многобитовые ошибки, например сразу в группе ячеек). Тем не менее, Uncorrectable Errors, то есть ошибки, которые не удалось исправить, и которые, почти наверняка привели к фатальным последствмяи типа BSOD или kernel panic встречаются куда чаще, чем это принято считать. А в случае использования памяти без ECC каждая из таких ошибок — это почти наверняка BSOD или kernel panic, или серьезный сбой в работе приложения. Ведь, например, очень многие хранят данные баз в памяти для ускорения ее работы.
В сравнении с ранее опубликованным исследованием, работа группы Шрёдер резко повысила «ожидания» сбоев. Так, они оценили события отказов в 25-70 тысяч сбоев на миллиард часов работы сервера, что почти в пятнадцать раз превышает более раннюю оценку, сделанную на меньшей популяции.
С отказами в результате неисправимых (uncorrectable, неисправленных ECC или Chipkill) встретились 1,3% серверов в год, или около 0,22% DIMM.
Системы, использующие «многобитные» механизмы, такие как Chipkill, имели число отказов в 4-10 раз меньше, по сравнению с обычным ECC.
Другие интересные выводы, сделанные в опубликованной работе это:
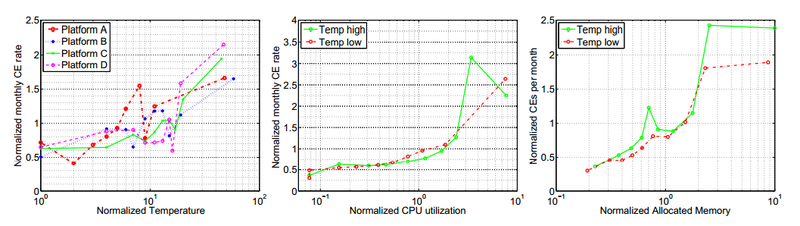
Рабочая температура, и ее повышение крайне мало коррелирует с вероятностью сбоя в DRAM. Это еще один факт, который указывает, что бытующее до сих пор в индустрии мнение о губительности повышенной температуры на полупроводники и компьютерное оборудование (мнение, основанное на исследовании 80-х годов) на сегодняшний день следует радикально пересмотреть. Это еще одно подтверждение этому факту, который уже был установлен, например в работе о жестких дисках. Парадоксальным образом там было установлено, что наименьшее количество отказов HDD наблюдалось при температурах в районе 40-45 градусов, а ее понижение количество отказов увеличивало (!).
В случае DRAM кореляция между температурой (в наблюдавшемся диапазоне около 20 градусов между самой низкой и самой высокой) и отказами была крайне незначительной.
(здесь и далее на слайдах: CE — correctable errors, ошибки, зарегистрированные, но исправленные ECC, UE — uncorrectable errors)
Однако существенно коррелировали отказы с загрузкой памяти и интенсивностью обмена с ней (отчасти высокая загрузка памяти влияет и на ее температуру, конечно, но не всегда). Вполне вероятно, что интенсивный обмен и большой относительный объем заполненных данными памяти значительно повышает вероятность быстрого обнаружения сбоя.

Было установлено, что вероятность получить повторный сбой в уже ранее сбоившем модуле памяти в сотни раз выше, по сравнению с не сбоившем ранее. Это может быть вызвано как наличием плохо выявляемого технологического брака, так и тем, что отказ, например пробой заряженной частицей космических лучей, не проходит для памяти бесследно, даже если ошибка была скорректирована ECC.
70-80% случаях, когда регистрировалась неисправимая ошибка в модуле памяти, это модуль уже имел исправимый ECC или Chipkill отказ в этом или предыдущем месяце.

Было установлено, что сравнительно новые модули, выполненные с более высокой плотностью и более тонкими техпроцессами, не показывают более высокого уровня отказов. По-видимому пока в технологии DRAM технологический предел, близ которого начинаются проблемы с надежностью, пока не достигнут. В наблюдаемом парке модулей было примерно шесть разных типов и поколений памяти (DDR1, DDR2 и FBDIMM разных типов), и корреляции между высокой плотностью и числом отказов и сбоев выявлено не было.
Наконец, с пугающей ясностью был продемонстрирован эффект «старения» в модулях DRAM. Более того, в памяти он проявился куда более явно, чем, напрмер, в HDD, где порог, после которого отказы растут в разы, составил примерно 3-4 года.
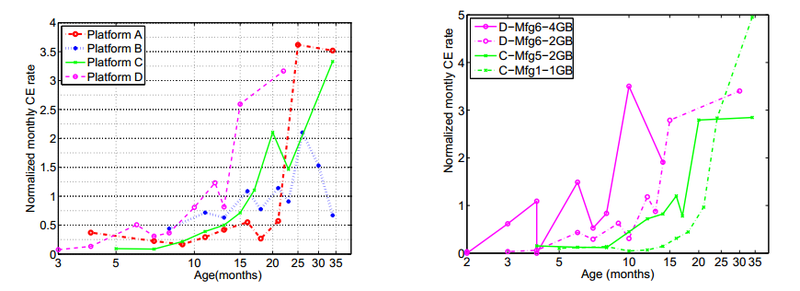
Парадоксальным образом статистика демонстрирует увеличивающиеся темпы роста correctable errors с увеличением возраста модулей, но снижающийся темп для Uncorrectable errors, однако скорее всего это просто результат плановой замены памяти в серверах, которые были замечены за сбоями.
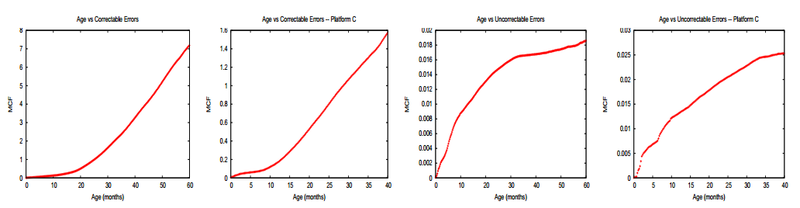
Удивительным образом, DRAM, лишенная каких-либо движущихся частей, показывает существенный и продолжающийся рост correctable отказов уже после года-полутора эксплуатации.
Подводя итоги, хотелось бы отметить, что приведенные статистические данные заставляют пересмотреть привычные для многих, основанные на «житейском опыте» принципы построения серверных платформ и эксплуатации датацентров, и позиция «чем холоднее — тем лучше», «память не изнашивается», «если север правильно собран, то он не ломается» и «ECC DRAM — ненужная трата денег, ведь у меня десктоп работает без ECC, и ничего». И чем скорее будут изжиты подобные шапкозакидательские настроения в столь серьезной области, как построение датацентров, тем, в итоге, будет лучше.
А занимающимся темой хочу порекомендовать неизбывный источник сладости, интеллектуального упражнения и пищи для мозгов, как публикации ежегодных конференций группы USENIX, это вам, господа, не маркетинговый булшит, столь привычный нам уже всем, а настоящая серьезная наука, от которой не отмахнешься.
