Внутри одно дата-центра организовать отказоустойчивость легко — есть масса инструментов и техник.
А как быть если надо организовать отказоустойчивость на базе нескольких дата-центров?
Ниже я приведу, на мой взгляд элегантное и очень дешевое решение, не лишенное конечно же недостатков.
Смысл заключается в том чтоб в каждом дата-центре был свой NS сервер который отдает IP своего дата-центра.
Теперь в картинках, imho так нагляднее и понятнее...
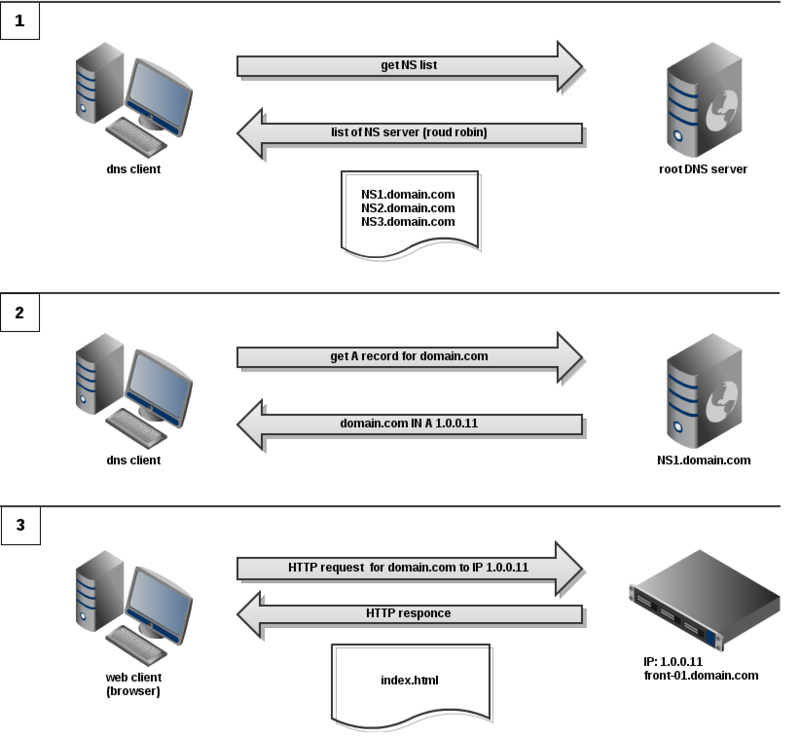
И так, что происходит при попытке браузером открыть web страничку (упрощенный вариант):
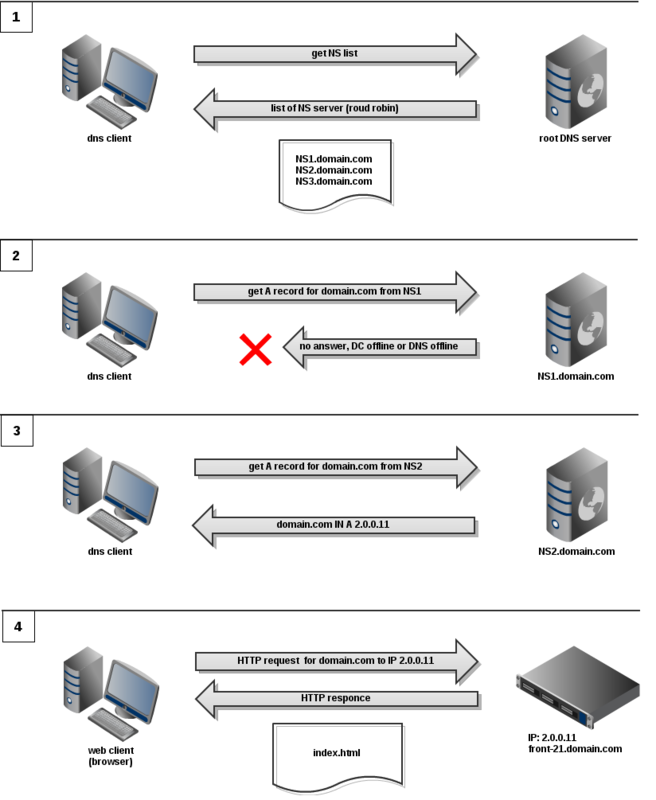
Если же DNS не отвечает, то dns клиент обращается к следующему ns серверу:
Настройки зон для каждого дата-центра.

Тут видно что в некоторых дата-центрах фронтов может быть больше чем 1.
В общем я рассказал про идею. А из нее можно накрутить много чего интересного.
Достоинства:
Недостатки:
P.S. Обязательно в файле зон выставить:
$TTL 60; 1 minutes
А как быть если надо организовать отказоустойчивость на базе нескольких дата-центров?
Ниже я приведу, на мой взгляд элегантное и очень дешевое решение, не лишенное конечно же недостатков.
Смысл заключается в том чтоб в каждом дата-центре был свой NS сервер который отдает IP своего дата-центра.
Теперь в картинках, imho так нагляднее и понятнее...
И так, что происходит при попытке браузером открыть web страничку (упрощенный вариант):
Если же DNS не отвечает, то dns клиент обращается к следующему ns серверу:
Настройки зон для каждого дата-центра.
Тут видно что в некоторых дата-центрах фронтов может быть больше чем 1.
В общем я рассказал про идею. А из нее можно накрутить много чего интересного.
Достоинства:
- Если падает дата-центр в течении минуты все клиенты уйдут на работающие площадки.
- Если надо провести профилактические работы — выключаем named, ждем минуту, можно работать.
Недостатки:
- Очень маленькая часть клиентов все равно будет ломиться в «выключенный» дата-центр.
- Надо поддерживать отдельный файл зон для каждого дата-центра, но эта задача легко решается с помощью например puppet.
- Не совсем равномерно распределяется нагрузка, но терпимо
P.S. Обязательно в файле зон выставить:
$TTL 60; 1 minutes
