 Вопрос о выборе цикла for/foreach стар, как мир. Все мы слышали, что foreach работает медленнее for-а. Но не все знаем почему… А вообще так ли оно?
Вопрос о выборе цикла for/foreach стар, как мир. Все мы слышали, что foreach работает медленнее for-а. Но не все знаем почему… А вообще так ли оно? Когда я начинал изучать .NET, один человек сказал мне, что foreach работает в 2 раза медленнее for-а, без каких-либо на то обоснований, и я принял это как должное. Теперь, когда чьих-то слов мне мало, я решил написать эту статью.
В этой статье я исследую производительность циклов, а так же уточню некоторые нюансы.
Итак, поехали!
Рассмотрим следующий код:
foreach (var item in Enumerable.Range(0, 128))
{
Console.WriteLine(item);
}
Цикл foreach является синтаксическим сахаром и в данном случае компилятор разворачивает его примерно в следующий код:
IEnumerator<int> enumerator = Enumerable.Range(0, 128).GetEnumerator();
try
{
while (enumerator.MoveNext())
{
int item = enumerator.Current;
Console.WriteLine(item);
}
}
finally
{
if (enumerator != null)
{
enumerator.Dispose();
}
}
Зная это можно легко предположить, почему foreach должен быть медленнее for-a. При использовании foreach-а:
- создается новый объект — итератор;
- на каждой итерации идет вызов метода MoveNext;
- на каждой итерации идет обращение к свойству Current, что равносильно вызову метода;
Вот и все! Хотя нет, не все так просто…
Есть еще один нюанс! К счастью или, к сожалению C#/CLR имеют кучу оптимизаций. К счастью, потому что код работает быстрее, к сожалению, потому что разработчикам об этом приходится знать (все же я считаю к счастью, причем к большому).
Например, поскольку массивы являются типом, сильно интегрированным в CLR, то для них имеется большое количество оптимизаций. Одна из них касается цикла foreach.
Таким образом, важным аспектом производительности цикла foreach является итерируемая сущность, поскольку в зависимости от нее он может разворачиваться по-разному.
В статье мы будем рассматривать итерирование массивов и списков. Помимо for-a и foreach-a будем так же рассматривать итерирование с помощью статического метода Array.ForEach, а так же экземплярного List.ForEach.
Методы тестирования
static double ArrayForWithoutOptimization(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < array.Length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForWithOptimization(int[] array)
{
int length = array.Length;
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForeach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
foreach (var item in array)
sum += item;
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForEach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
Array.ForEach(array, i => { sum += i; });
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
Тесты выполнялись при включенном флаге оптимизировать код в Release. Количество элементов в массиве и списке равно 100 000 000. Машина, на которой проводились тесты, имеет на своём борту процессор Intel Core i-5 и 8 GB оперативной памяти.
Массивы
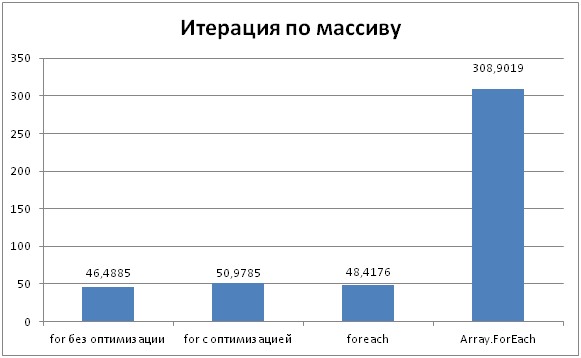
Из диаграммы видно, что for/foreach на массивах работают одинаковое время. Это дело рук той самой оптимизации, которая разворачивает цикл foreach в for, с использованием длины массива в качестве максимальной границы итерирования. Кстати, не важно кэшируем мы длину или нет при итерировании с помощью for-а, результат практически один и тот же.
Как бы странно это не было, но при использовании массивов, кэширование длины может сказаться негативно. Дело в том, что когда JIT видит array.Length в качестве границы итерирования в цикле, то он выносит проверку индекса на попадание в нужные границы за цикл, тем самым проверка делается только один раз. Эту оптимизацию очень легко разрушить, и случай когда мы кэшируем переменную уже не оптимизируется.
Метод же Array.ForEach показал самый худший результат. Его реализация выглядит достаточно просто:
public static void ForEach<T>(T[] array, Action<T> action)
{
for (int index = 0; index < array.Length; ++index)
action(array[index]);
}
Тогда почему же он работает так медленно? Ведь за кулисами он просто использует обычный for. Все дело в вызове делегата action. Фактически на каждой итерации вызывается метод, а мы знаем, что это лишние накладные расходы. Тем более, как известно, делегаты вызываются не так быстро, как хотелось бы, отсюда и результат.
С массивами все разъяснили. Переходим к спискам.
Для списков будем использовать аналогичные методы сравнения.
Списки
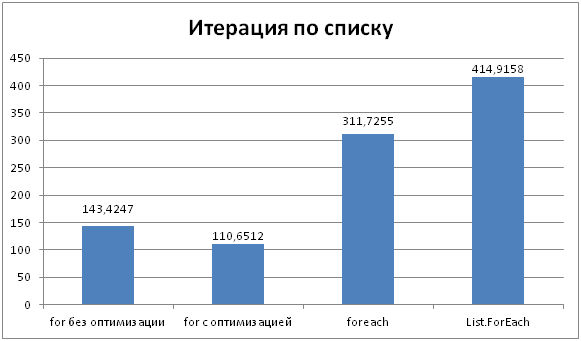
Здесь совсем другой результат!!!
При итерации списков циклы for/foreach дают различные результаты. Дело в том, что здесь нет никакой оптимизации, и foreach разворачивается в создание итератора и дальнейшую работу с ним.
Лучший результат показал как и ожидалось for с кэшированием длины списка. Индексация списков не влияет на производительность так как JIT inline-ит её (индексация — это обычное свойство с параметром).
foreach показал результат примерно в 2,5 раза медленнее for-а. Это связано с его сложной структурой которая отрабатывает за кулисами (вызов MoveNext, Current).
List.ForEach так же как и Array.ForEach показал худший результат. Дело в том, что JIT не inline-ит виртуальные методы, а делегаты как известно всегда вызываются виртуально.
Реализация этого метода выглядит так:
public void ForEach(Action<T> action)
{
int num = this._version;
for (int index = 0; index < this._size && num == this._version; ++index)
action(this._items[index]);
if (num == this._version)
return;
ThrowHelper.ThrowInvalidOperationException(ExceptionResource.InvalidOperation_EnumFailedVersion);
}
Здесь на каждой итерации происходит вызов делегата action. Так же каждый раз проверяется, не изменился ли список во время итерации, и если изменился, то выбрасывается исключение.
Интересен факт, что у массивов метод ForEach является статическим, в то время как у списков он экземплярный. Я полагаю, это сделано во благо увеличения производительности. Как известно, список основан на обычном массиве, а потому в методе ForEach идет обращение по индексу к массиву, что в разы быстрее обращения по индексу через индексатор.
Массивы VS списки

Конкретные цифры
- Цикл for (без кэширования длины) и foreach для массивов работают чуть быстрее чем for c кэшированием длины;
- Цикл Array.ForEach примерно в шесть раз медленнее циклов for/foreach;
- for (без кэшировании длины) на списках работает примерно в 3 раза медленнее, чем на массивах;
- for (с кэшировании длины) на списках работает примерно в 2 раза медленнее, чем на массивах;
- foreach на списках медленнее foreach на массивах примерно в 6 раз;
Призеры
Среди массивов:

Среди списков:
В заключении
Не знаю как для Вас, но для меня эта статья оказалась очень интересной. Особенно процесс её написания. Оказывается foreach на массивах быстрее for-а с кэшированием длины. Спасибо JIT-у за оптимизации. foreach же на списках медленнее for-а это факт.
С сегодняшними компьютерами не использовать цикл foreach только потому что он медленнее for-а, наверное, не совсем правильно. Ведь код с его использованием выглядит более декларативным. Конечно, если нужно ну очччень сильно оптимизировать код, то, наверное, лучше отдать предпочтение for-у.
Спасибо за прочтение.
