Полгода назад написал бандл ClosureTable для фреймворка Laravel 3. Поводом для написания стала вот эта замечательная презентация Билла Карвина о способах хранения и обработки иерархических данных в MySQL с использованием PHP.
Итак. Существует несколько шаблонов проектирования баз данных для хранения и обработки иерархических структур:
Суть данного шаблона проектирования заключается в том, что связи между сущностями хранятся в отдельной таблице, тогда как основная таблица содержит только данные самих сущностей.
Таблица связей должна содержать как минимум два поля:
Пусть мы работаем над созданием очередной SuperPuper CMS и приступили к разработке модуля редактирования текстовых страниц. Нам понадобятся две таблицы:
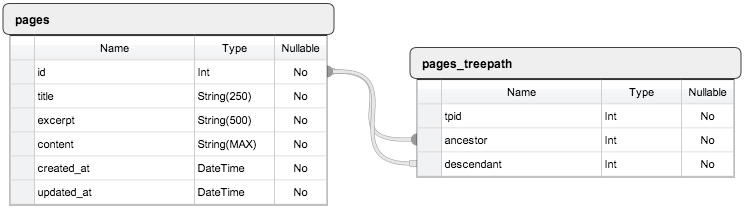
Схема таблиц БД
В качестве примера используем следующую иерархию страниц:

Вот такой SQL-запрос у нас получится, если мы захотим выбрать все страницы раздела «О компании».
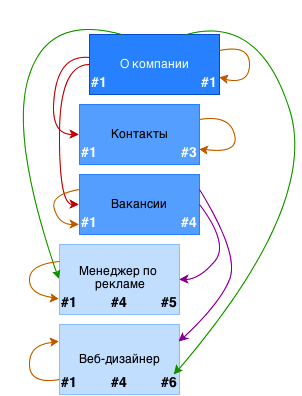
Ветка полученного результата. Стрелки указывают на связи между страницами
«Descendant» означает «потомок», а «ancestor» — предок. Соответственно, чтобы получить все дочерние страницы, мы присоединяем таблицу связей
А теперь снизу вверх: посмотрим всех «родителей» у страницы «Корпоративный».
В этом случае наоборот. Мы ищем страницы выше по иерархии, поэтому присоединяем таблицу связей с условием, что идентификатор страницы
Можно добавить новую вакансию. Данные ценности в нашем случае не представляют, так что посмотрим на сам запрос.
С первым запросом все ясно — это простая вставка новых данных. А вот второй запрос стоит разобрать по порядку, так что давайте посмотрим, что тут происходит.
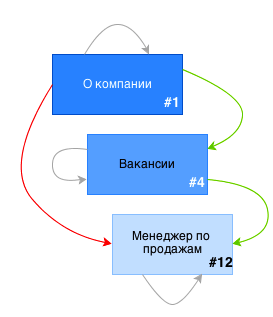
Связи между элементами после вставки новой вакансии
Выполнив этот запрос, мы получим следующий список связей:
Добавим к предыдущему запросу еще один путем объединения:
В список связей добавится связь-ссылка страницы на саму себя:
Как видите, данный SELECT-запрос позволяет установить связи между новой страницей и всеми её предками.
А теперь закроем вакансию веб-дизайнера.
Здесь всё просто. Сначала мы удаляем все связи, где ссылка на потомка равняется 6 (страница «Веб-дизайнер»), а затем удаляем и саму страницу.
Вдруг так случилось, что с некоторых пор компания ABC перестала разрабатывать сайты. Нам понадобится выполнить вот такой запрос, чтобы удалить соответствующий подраздел:
В отличие от предыдущего запроса, этот несколько сложнее и сначала удаляются сами страницы и уже после этого связи между ними (поскольку последние активно используются при удалении первых).
Сложность запросов отчасти объясняется тем, что MySQL не позволяет выполнять запрос на удаление записей с условием
Если вы внимательно посмотрите на вложенный SELECT-запрос в DELETE-запросе из таблицы
После того, как страницы удалены, остаётся удалить связи между ними. Для этого находим все ссылки на потомков
Еще в таблицу связей можно добавить поле, контролирующее уровень вложенности элементов. Это поле позволит составлять более простые запросы на выборку непосредственных предков или непосредственных потомков. Например:
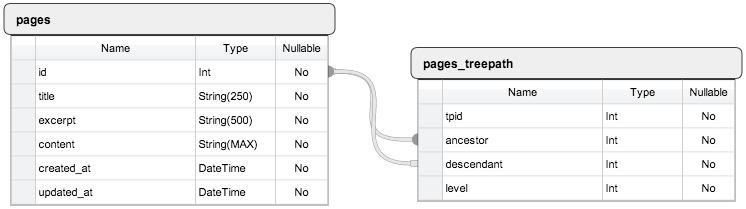
Схема таблиц БД
Продолжение следует.
Итак. Существует несколько шаблонов проектирования баз данных для хранения и обработки иерархических структур:
- Adjacency List («список смежности»)
- Materialized Path («материализованный путь»)
- Nested Sets («вложенные множества»)
- Closure Table («таблица связей»)
Что такое Closure Table
Суть данного шаблона проектирования заключается в том, что связи между сущностями хранятся в отдельной таблице, тогда как основная таблица содержит только данные самих сущностей.
Таблица связей должна содержать как минимум два поля:
- ссылку на предка (ancestor)
- ссылку на потомка (descendant)
Пусть мы работаем над созданием очередной SuperPuper CMS и приступили к разработке модуля редактирования текстовых страниц. Нам понадобятся две таблицы:
pagesбудет содержать данные о страницеpages_treepathбудет содержать данные об иерархии страниц
Схема таблиц БД
В качестве примера используем следующую иерархию страниц:
Выборка потомков
Вот такой SQL-запрос у нас получится, если мы захотим выбрать все страницы раздела «О компании».
SELECT * FROM pages p
JOIN pages_treepath t ON (p.id = t.descendant)
WHERE t.ancestor = 1
Ветка полученного результата. Стрелки указывают на связи между страницами
«Descendant» означает «потомок», а «ancestor» — предок. Соответственно, чтобы получить все дочерние страницы, мы присоединяем таблицу связей
pages_treepath при условии, что идентификатор страницы id имеет то же значение, что и ссылка на потомка descendant. При этом ссылка ancestor на родительскую страницу равняется 1, идентификатору страницы «О компании».Выборка предков
А теперь снизу вверх: посмотрим всех «родителей» у страницы «Корпоративный».
SELECT * FROM pages p
JOIN pages_treepath t ON (p.id = t.ancestor)
WHERE t.descendant = 11
В этом случае наоборот. Мы ищем страницы выше по иерархии, поэтому присоединяем таблицу связей с условием, что идентификатор страницы
id должен равняться ссылке на предка ancestor, а выборку осуществляем по ссылке на потомка descendant, в нашем случае равной 11.Вставка нового элемента
Можно добавить новую вакансию. Данные ценности в нашем случае не представляют, так что посмотрим на сам запрос.
INSERT INTO pages
VALUES (12, 'Менеджер по продажам',
'',
'Требуется офигенный менеджер по продажам',
'0000-00-00 00:00:00',
'0000-00-00 00:00:00')
INSERT INTO pages_treepath (ancestor, descendant)
SELECT ancestor, 12 FROM pages_treepath
WHERE descendant = 4
UNION ALL
SELECT 12, 12
С первым запросом все ясно — это простая вставка новых данных. А вот второй запрос стоит разобрать по порядку, так что давайте посмотрим, что тут происходит.
Связи между элементами после вставки новой вакансии
SELECT ancestor, 12 FROM pages_treepath WHERE descendant = 4
Выполнив этот запрос, мы получим следующий список связей:
------------------------- | ancestor | descendant | ------------------------- | 4 | 12 | | 1 | 12 | -------------------------
Добавим к предыдущему запросу еще один путем объединения:
SELECT ancestor, 12 FROM pages_treepath WHERE descendant = 4
UNION ALL
SELECT 12, 12
В список связей добавится связь-ссылка страницы на саму себя:
------------------------- | ancestor | descendant | ------------------------- | 4 | 12 | | 1 | 12 | | 12 | 12 | -------------------------
Как видите, данный SELECT-запрос позволяет установить связи между новой страницей и всеми её предками.
ancestor — всегда ссылка на предка, descendant — ссылка на потомка. INSERT-запрос, написанный вначале, вставляет полученный результат в таблицу pages_treepath.Удаление элемента
А теперь закроем вакансию веб-дизайнера.
DELETE FROM pages_treepath
WHERE descendant = 6
DELETE FROM pages
WHERE id = 6
Здесь всё просто. Сначала мы удаляем все связи, где ссылка на потомка равняется 6 (страница «Веб-дизайнер»), а затем удаляем и саму страницу.
Удаление вложенного дерева
Вдруг так случилось, что с некоторых пор компания ABC перестала разрабатывать сайты. Нам понадобится выполнить вот такой запрос, чтобы удалить соответствующий подраздел:
DELETE FROM pages
WHERE id IN (
SELECT descendant FROM (
SELECT descendant FROM pages p
JOIN pages_treepath t ON p.id = t.descendant
WHERE t.ancestor = 7
) AS tmptable
)
DELETE FROM pages_treepath
WHERE descendant IN (
SELECT descendant FROM (
SELECT descendant FROM pages_treepath
WHERE ancestor = 7
) AS tmptable
)
В отличие от предыдущего запроса, этот несколько сложнее и сначала удаляются сами страницы и уже после этого связи между ними (поскольку последние активно используются при удалении первых).
Сложность запросов отчасти объясняется тем, что MySQL не позволяет выполнять запрос на удаление записей с условием
WHERE, в котором содержится выборка SELECT из той же таблицы. В случае с MySQL мы вынуждены поместить SELECT-запросы во временную таблицу. А в общем случае наши запросы выглядели бы так:DELETE FROM pages
WHERE id IN (
SELECT descendant FROM pages p
JOIN pages_treepath t ON p.id = t.descendant
WHERE t.ancestor = 7
)
DELETE FROM pages_treepath
WHERE descendant IN (
SELECT descendant FROM pages_treepath
WHERE ancestor = 7
)
Если вы внимательно посмотрите на вложенный SELECT-запрос в DELETE-запросе из таблицы
pages, то обнаружите, что мы уже рассматривали подобный запрос. Этот от предыдущего отличается только идентификатором страницы. В результате выборки мы получаем все дочерние страницы раздела «Сайты» (включая сам раздел), а затем удаляем все страницы с полученными идентификаторами.После того, как страницы удалены, остаётся удалить связи между ними. Для этого находим все ссылки на потомков
descendant, где ссылка на предка равняется идентификатору страницы «Сайты».Уровень вложенности
Еще в таблицу связей можно добавить поле, контролирующее уровень вложенности элементов. Это поле позволит составлять более простые запросы на выборку непосредственных предков или непосредственных потомков. Например:
SELECT * FROM pages p
JOIN pages_treepath t ON (p.id = t.descendant)
WHERE t.ancestor = 4
AND t.level = 2
Схема таблиц БД
Продолжение следует.
