Синтаксис конструкции INSERT может показаться весьма тривиальным, поскольку стандарт T-SQL рассматривал ключевое слово VALUES лишь в контексте вставки данных – INSERT INTO … VALUES ….
С выходом SQL Server 2008 существенно расширился синтаксис T-SQL, благодаря чему стало возможным использовать многострочную конструкцию VALUES, при этом не только в контексте вставки.
В данном топике будет рассмотрена сравнительная эффективность использования конструкции VALUES в различных типовых ситуациях. Чтобы дать объективную оценку полученных результатов, для каждого примера, будет рассмотрен его план выполнения.
Для наглядности, создадим и заполним тестовыми данными таблицу, которая будет содержать информацию о среднем бале среди учащихся в разрезе четвертей.
Предположим, что требуется узнать минимальный и максимальный бал по каждому из учащихся.
Чтобы сделать сравнение более интересным, каждый из предложенных подходов будет выполнен в разных ситуациях: 1) когда у таблицы есть первичный ключ и 2) когда таблица является неупорядоченной кучей.
Сначала приведем самый неудачный пример реализации:
Вместо того, чтобы прочитать данные один раз, обращение к исходной таблице происходит 4 раза – это, мягко говоря, не рационально:
Попробуем избавится от повторные чтений, применяя конструкцию UNPIVOT:
Повторные чтения ушли, но план усложнился:

При этом, в случае, когда у таблице нет кластерного индекса, серверу приходится применять сортировку для упорядочивания данных.
Посмотрим как ведет себя конструкция VALUES:
При изменении условий, план остается очень простым и неизменным:
Значение Query Cost, полученный из SSMS, также наглядно подтверждает преимущества конструкции VALUES:
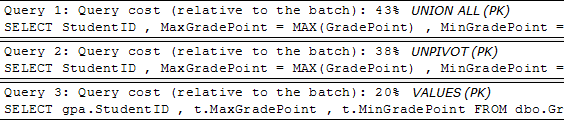
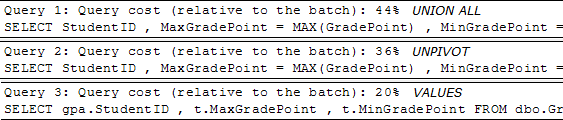
Применение конструкции VALUES не ограничивается задачами по преобразованию строк в столбцы. Еще одним из эффективных применений данной конструкции является форматированный вывод запроса.
Сразу уточню, что не считаю это хорошей практикой, поскольку данная задача должна выполнятся на клиенте. Тем не менее, подобные задачи часто были полезны, например, при разработке отчетов.
Предположим, для каждой исходной строки необходимо вывести данные в следующем виде:

Можно решить эту задачу вычитывая данные несколько раз применяя UNION ALL c сортировкой:
Опять мы получаем повторные чтения. При этом обратите внимание на сортировку, в случае, когда таблица не имеет кластерного индекса:
Как вариант, можно вернутся к конструкции UNPIVOT, проверяя при этом номер строки:
Повторные чтения ушли, но сортировка при использовании кучи никуда не исчезла:
Применим конструкцию VALUES, написав более элегантный запрос:
Мы получили простой и эффективный план выполнения:
Согласно Query Cost, конструкция VALUES в очередной раз демонстрирует свою эффективность, по сравнению с соперниками:

Краткие выводы:
Конструкция VALUES не является полной заменой UNPIVOT, тем не менее, в некоторых ситуациях, она бывает очень полезной – позволяя существенно упрощять запросы.
Надеюсь, что у меня получилось, наглядно, это продемонстрировать.
С выходом SQL Server 2008 существенно расширился синтаксис T-SQL, благодаря чему стало возможным использовать многострочную конструкцию VALUES, при этом не только в контексте вставки.
В данном топике будет рассмотрена сравнительная эффективность использования конструкции VALUES в различных типовых ситуациях. Чтобы дать объективную оценку полученных результатов, для каждого примера, будет рассмотрен его план выполнения.
Для наглядности, создадим и заполним тестовыми данными таблицу, которая будет содержать информацию о среднем бале среди учащихся в разрезе четвертей.
IF OBJECT_ID('dbo.GradePointAverage', 'U') IS NOT NULL
DROP TABLE dbo.GradePointAverage
GO
CREATE TABLE dbo.GradePointAverage (
StudentID INT
, I SMALLINT NOT NULL
, II SMALLINT NOT NULL
, III SMALLINT NOT NULL
, IV SMALLINT NOT NULL
, CONSTRAINT PK_GradePointAverage PRIMARY KEY (StudentID)
)
INSERT INTO dbo.GradePointAverage (StudentID, I, II, III, IV)
SELECT sv.number, sv.number % 94, sv.number % 83, sv.number % 72, sv.number % 61
FROM [master].dbo.spt_values sv
WHERE sv.type = 'P'
AND sv.number BETWEEN 1 AND 2000
Предположим, что требуется узнать минимальный и максимальный бал по каждому из учащихся.
Чтобы сделать сравнение более интересным, каждый из предложенных подходов будет выполнен в разных ситуациях: 1) когда у таблицы есть первичный ключ и 2) когда таблица является неупорядоченной кучей.
Сначала приведем самый неудачный пример реализации:
SELECT
StudentID
, MaxGradePoint = MAX(GradePoint)
, MinGradePoint = MIN(GradePoint)
FROM (
SELECT StudentID, GradePoint = I
FROM dbo.GradePointAverage
UNION ALL
SELECT StudentID, II
FROM dbo.GradePointAverage
UNION ALL
SELECT StudentID, III
FROM dbo.GradePointAverage
UNION ALL
SELECT StudentID, IV
FROM dbo.GradePointAverage
) t
GROUP BY StudentID
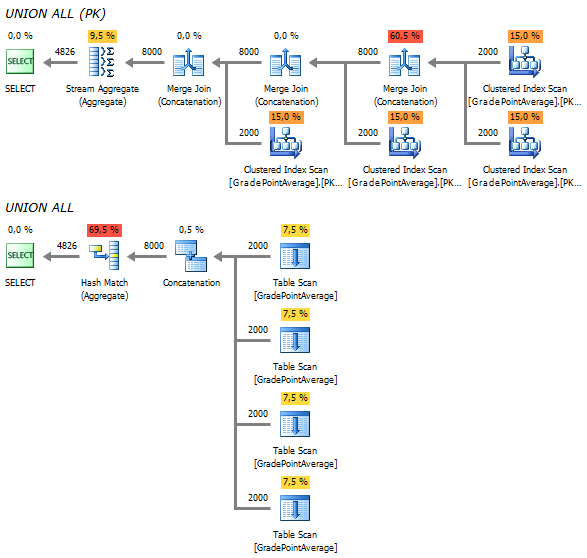
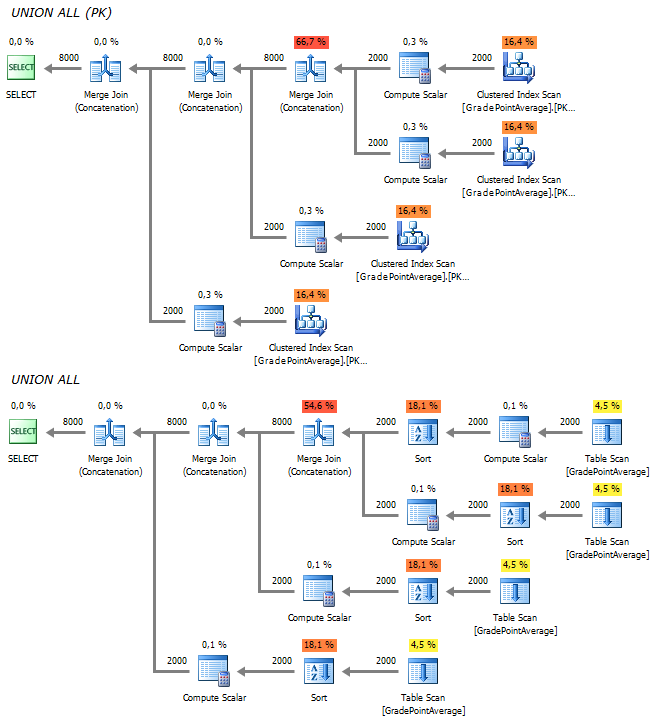
Вместо того, чтобы прочитать данные один раз, обращение к исходной таблице происходит 4 раза – это, мягко говоря, не рационально:
Попробуем избавится от повторные чтений, применяя конструкцию UNPIVOT:
SELECT
StudentID
, MaxGradePoint = MAX(GradePoint)
, MinGradePoint = MIN(GradePoint)
FROM (
SELECT *
FROM dbo.GradePointAverage
UNPIVOT (
GradePoint FOR Grade IN (I, II, III, IV)
) unpvt
) t
GROUP BY StudentID
Повторные чтения ушли, но план усложнился:
При этом, в случае, когда у таблице нет кластерного индекса, серверу приходится применять сортировку для упорядочивания данных.
Посмотрим как ведет себя конструкция VALUES:
SELECT
gpa.StudentID
, t.MaxGradePoint
, t.MinGradePoint
FROM dbo.GradePointAverage gpa
CROSS APPLY (
SELECT
MaxGradePoint = MAX(GradePoint)
, MinGradePoint = MIN(GradePoint)
FROM (
VALUES (I), (II), (III), (IV)
) t (GradePoint)
) t
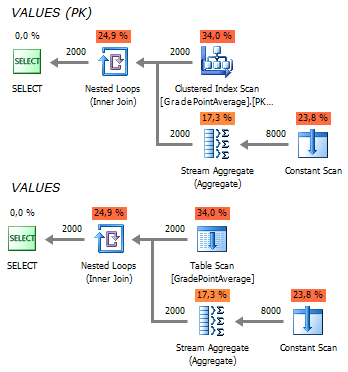
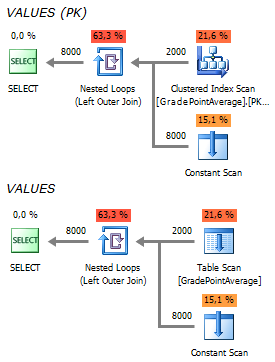
При изменении условий, план остается очень простым и неизменным:
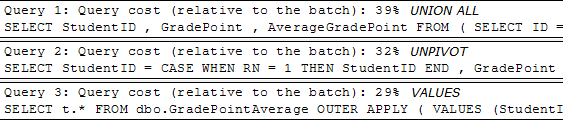
Значение Query Cost, полученный из SSMS, также наглядно подтверждает преимущества конструкции VALUES:
Применение конструкции VALUES не ограничивается задачами по преобразованию строк в столбцы. Еще одним из эффективных применений данной конструкции является форматированный вывод запроса.
Сразу уточню, что не считаю это хорошей практикой, поскольку данная задача должна выполнятся на клиенте. Тем не менее, подобные задачи часто были полезны, например, при разработке отчетов.
Предположим, для каждой исходной строки необходимо вывести данные в следующем виде:
Можно решить эту задачу вычитывая данные несколько раз применяя UNION ALL c сортировкой:
SELECT
StudentID
, GradePoint
, AverageGradePoint
FROM (
SELECT ID = StudentID, StudentID, GradePoint = I, AverageGradePoint = (I + II + III + IV) / 4., RN = 1
FROM dbo.GradePointAverage
UNION ALL
SELECT StudentID, NULL, II, NULL, 2
FROM dbo.GradePointAverage
UNION ALL
SELECT StudentID, NULL, III, NULL, 3
FROM dbo.GradePointAverage
UNION ALL
SELECT StudentID, NULL, IV, NULL, 4
FROM dbo.GradePointAverage
) t
ORDER BY ID, RN
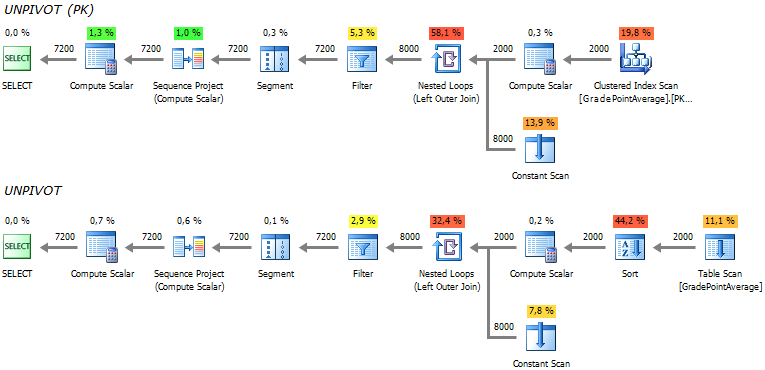
Опять мы получаем повторные чтения. При этом обратите внимание на сортировку, в случае, когда таблица не имеет кластерного индекса:
Как вариант, можно вернутся к конструкции UNPIVOT, проверяя при этом номер строки:
SELECT
StudentID = CASE WHEN RN = 1 THEN StudentID END
, GradePoint
, AverageGradePoint = CASE WHEN RN = 1 THEN AverageGradePoint END
FROM (
SELECT
StudentID
, GradePoint
, AverageGradePoint
, RN = ROW_NUMBER() OVER (PARTITION BY StudentID ORDER BY 1/0)
FROM (
SELECT *, AverageGradePoint = (I + II + III + IV) / 4.
FROM dbo.GradePointAverage
) gpa
UNPIVOT (
GradePoint FOR Grade IN (I, II, III, IV)
) unpvt
) t
Повторные чтения ушли, но сортировка при использовании кучи никуда не исчезла:
Применим конструкцию VALUES, написав более элегантный запрос:
SELECT t.*
FROM dbo.GradePointAverage
OUTER APPLY (
VALUES
(StudentID, I, (I + II + III + IV) / 4.)
, (NULL, II, NULL)
, (NULL, III, NULL)
, (NULL, IV, NULL)
) t (StudentID, GradePoint, AverageGradePoint)
Мы получили простой и эффективный план выполнения:
Согласно Query Cost, конструкция VALUES в очередной раз демонстрирует свою эффективность, по сравнению с соперниками:
Краткие выводы:
Конструкция VALUES не является полной заменой UNPIVOT, тем не менее, в некоторых ситуациях, она бывает очень полезной – позволяя существенно упрощять запросы.
Надеюсь, что у меня получилось, наглядно, это продемонстрировать.
