
Здравствуй, Хабр!
Это мой первый пост, в котором я хочу поделиться своей наработкой в решении такой задачки, как выделение контента на странице. Собственно, задачка давно висела в голове в фоновом режиме. Но так сложилось, что именно сейчас мне самому понадобился инструмент, кроме того наткнулся на статейку на хабре: habrahabr.ru/company/mailru/blog/200394 и решил — пора. Ладно, поехали.
Ход мыслей
Собственно, к чему такая картинка в начале статьи? Дело в том, что задачу решать можно совершенно по-разному. Не буду ударяться в долгие рассуждения о возможных способах решения, их плюсах и минусах. Главное то, что в этом посте к задаче я подхожу как к проблеме классификации. Итак, вот ход мысли:
- Придумываем набор факторов, чтобы любой элемент в DOM можно было векторизовать.
- Каким то образом собираем пачку документов.
- В каждом документе векторизуем все элементы в DOM ниже BODY в дереве. Опять же как-то.
- Для каждого из векторизованных элементов назначаем класс 1 или 0. 0 — не целевой, 1 — целевой.
- Бьём выборку на две части в пропорции 50/50 или около того.
- На одном куске обучаем наш классификатор, на другом его тестируем, получаем результат в виде полноты, точности. Ну или любой метрики типа F-score
тысячи их.
Проницательный читатель наверняка скажет, что вместо последних двух пунктов лучше сделать, например, кросс-валидацию и будет прав. В целом это не важно в данном случае, т.к. статья в первую очередь посвящена инструменту, а не сопряжённым математико/алгоритмическим деталям.
Про идейную сторону дела вроде бы всё ясно. Посмотрим на технологическую сторону.
- В качестве языка выбрал python. В основном потому что он мне нравится (:
- В качестве математической библиотеки для обучения сразу же был выбран sklearn.
- Поскольку я
почему-торешил что javascript-страницы должны также успешно обрабатываться, в качестве движка для парсинга был выбран PyQt4. Как окажется далее — это очень правильный выбор.
Решение
Как обычно, оказалось что идея не учитывает всякие неприятные «мелочи». А дело в том, что звучит всё здорово в предыдущем пункте, но совершенно не ясно как размечать выборку? Т.е. как выбирать целевые элементы в DOM для дальнейшего обучения? И вот тогда в голову пришла правильная мысль: а давайте пусть это будет интерактивный браузер. Выбирать целевые блоки будем при помощи мыши и клавиатуры. Эдакий визуализированный процесс разметки не выходя из браузера.
Задумывалось следущее: есть браузер, в котором можно водить мышкой, и элемент под мышкой «подсвечивается». Когда выбран нужный элемент, пользователь нажимает определённый хоткей. В результате страница парсится, DOM векторизуется, а выделенный элемент получает класс 1, в то время как остальные — класс 0.
Результаты
Я не хочу копипасить сюда портянки из кода — всё в открытом виде и доступно в репозитории. Кому надо — почитаете там. Да, кому лень, можно ставить с помощью pip, но учтите, писал и тестировал только на Ubuntu >=12.04.
В итоге получилась библиотечка с треми основными возможностями:
- Интерактивное обучение распознаванию контента в браузере. Полученная модель классификатора сериализуется в файлик.
- Интерактивное тестирование распознавания контента в браузере. Элементы, которые на странице были проклассифицированы как целевые — «подсвечиваются».
- Консольная тулза, умеющая выдрать html целевого элемента DOM по заданному URL и файлику с моделькой.
Кстати, после установки пакетика constractor — станут доступны для запуска два скриптика:
- constractor_train.py — это интерактивная обучалка/тестилка. Тулза умеет подсвечивать элемент под указателем мыши, векторизовать страницу по нажатию хоткея, обучиться на основе данных полученных с разных страниц, сохранить факторы и модельку в файлики, загрузить их из файликов, подсветить элемент на основании текущей модельки.
- constractor_predict.py — это консольная выдиралка html целевых элементов. В целом это всё что тулза умеет (:
Картинки
Для совсем уж ленивых привожу примеры с картинками. Например, хотим научить тулзу определять шапку Хабра.
1) Наводим мышку на шапку. Когда нужная область выделена (чёрным бэкграундом), нажимаем Ctrl+S. Тем самым добавили векторизованные элементы в выборку.
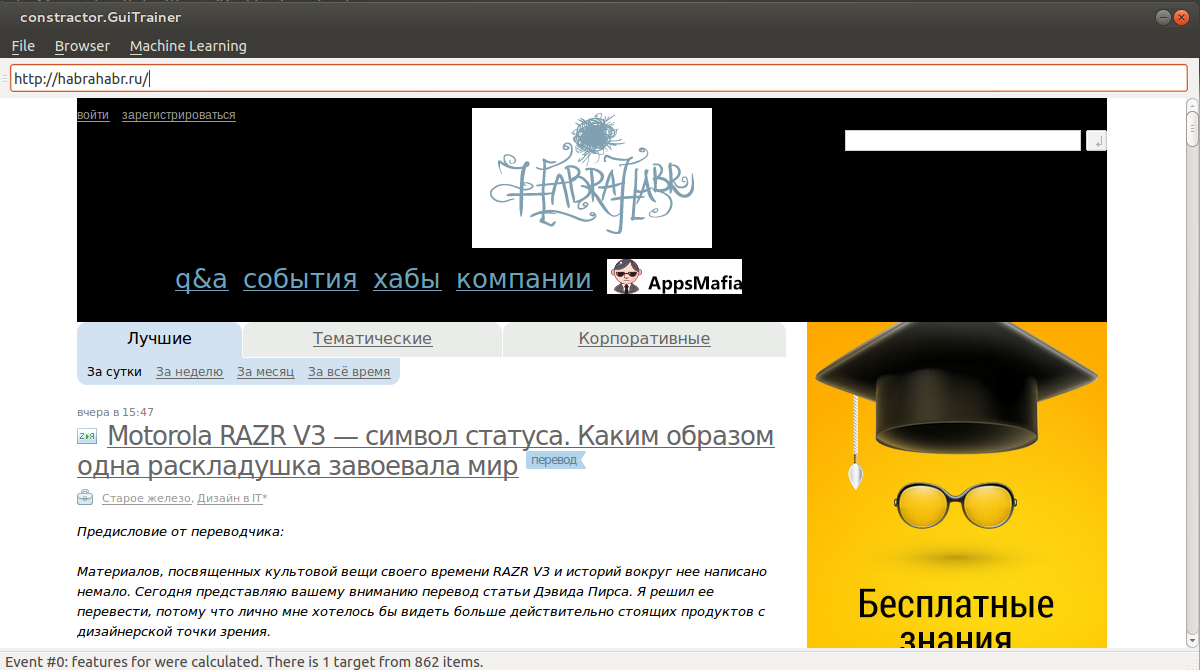
Повторяем процедуру несколько раз.
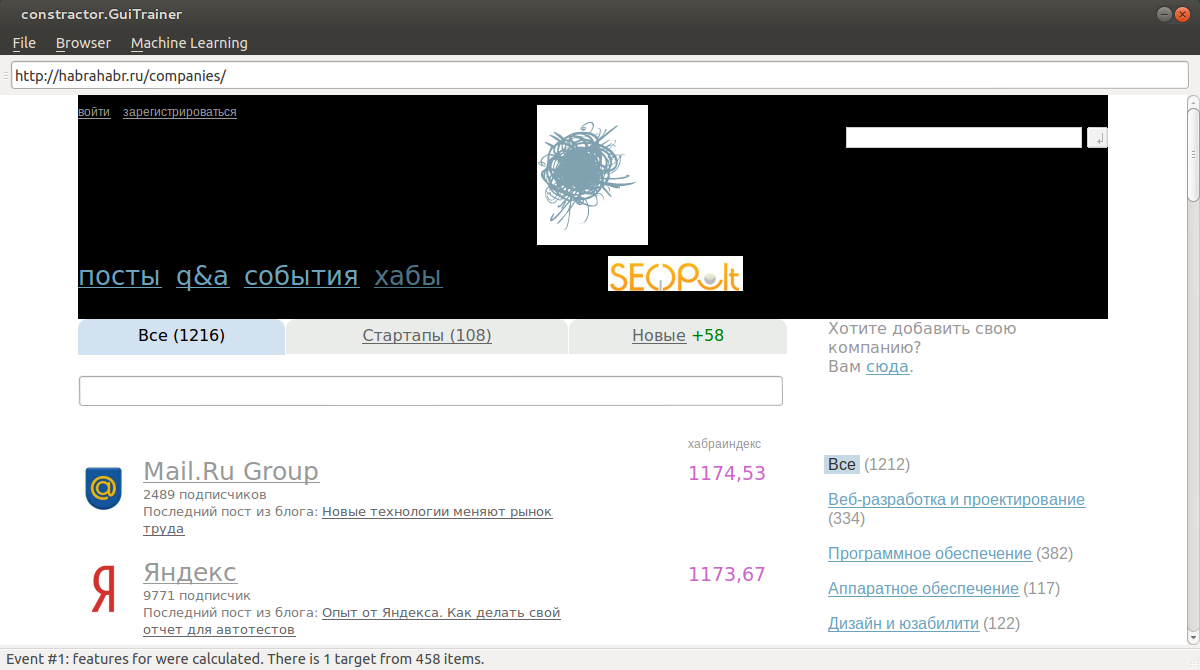
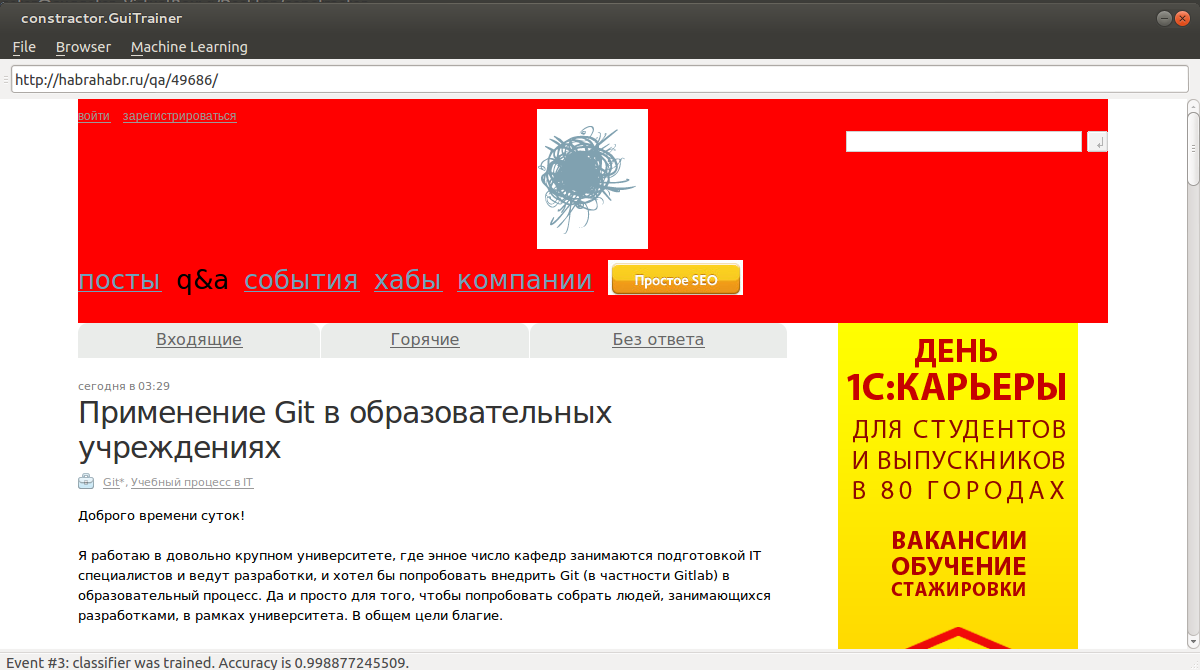
2) Далее нажимаем Ctrl+T для обучения. Заходим на произвольную страницу с нашей шапкой. Нажимаем Ctrl+P для прогноза.
Заключение
Библиотечка пока очень сырая и требует много доработок, прошу не
Из планов по доработкам: расширение множества дефолтных факторов, добавление встроенных моделек для распознавания разных типов блоков и многое другое. Конечно же я всё это буду постепенно пилить в свободное время. Однако буду очень признателен, если найдутся хабровольцы, готовые также в свободное время поконтрибьютить в библиотечку.
Спасибо за внимание!
