
У каждого из нас в сети есть набор сайтов на которые мы постоянно заходим черпать новую, интересную информацию. Я много раз пытался начать пользоваться RSS агрегатором и все время отказывался от этой идеи. Терпеливо разложив все ленты по своим папочкам, я вскоре понимал, что получил не то что ожидал. Если хотел почить про .NET, то статьи были перемешаны с другими, не относящимися к теме. Иногда хочется почитать просто про информационные технологии, но увы, в моем рубрикаторе такого раздела не было. Через какое-то время я забывал о ридере.
С появлением социальных сетей возникла надежда на то, что вся мощь социального графа поможет в решении проблемы поиска интересных материалов. Но если нет особой нужды заводить «виртуальных друзей», то ты находишься на краю этого графа, и информация не доходит, а если доходит, то с большим опозданием. Стоя в стороне от того места где «кипит жизнь», слышны только отголоски громких фраз. Ты пытаешься подойти, но тогда начинает заваливать грудой ненужной информации и теряется надежда на получение желаемого. Людям нужно поделиться фотками, пообщаться с друзьями. Они выкладывают фото собак не для того чтобы порадовать своих родных и близких, а чтобы получить лайк в копилку своего социального капитала. Складывается обманчивое впечатление, что к обретению нового опыта и новых знаний в наше время стремится мизерный процент людей.
Если рассматривать обычный социальный граф, то ситуация складывается следующим образом. Если узел A публикует некий контент, интересный узлу Б, то узел Б получит его в том случае, если только существует цепочка из узлов сети соединяющая А и Б, каждый узел которой «одобрил» данную публикацию.
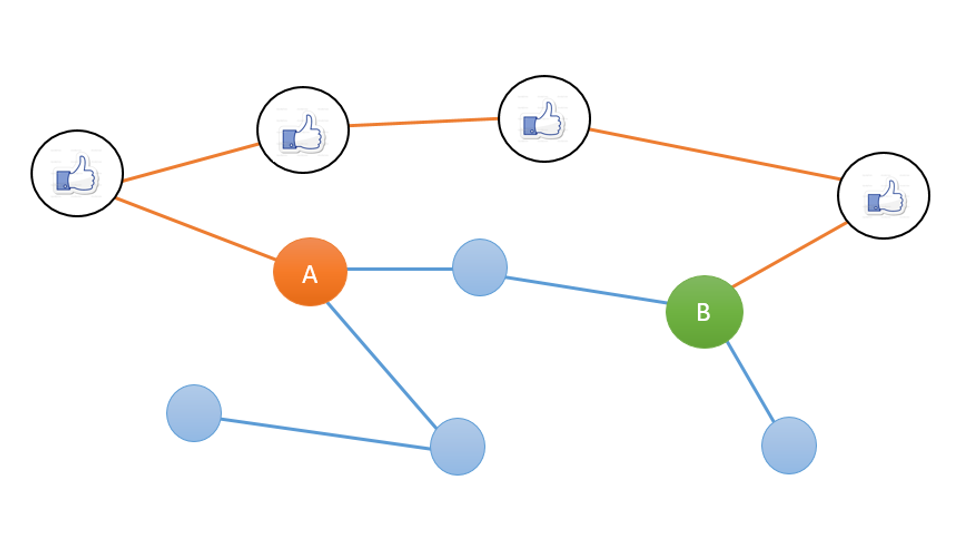
Для того, чтобы ты получал больше информации, нужно иметь больше социальных связей. Но если их слишком много, это становится накладно. Поэтому некоторые обратили свои взоры в сторону графов интересов.
Надежда на рай
На просторах сети рассматривалась «модель произвольных типизованных объектов, связанных произвольными типизованными связями». В том числе была попытка понять, что можно на этом построить. На Хабре обсуждалась идея графа интересов, являющейся частным случаем данной модели. Суть была в том, что все интересы (теги) всегда уникальны, поэтому вся релевантная аудитория фокусируется вокруг них. Дальше проблема была упорядочить всё связанное с конкретным тегом. Авторы этих публикаций, обозначили принципы, по которым будет выстраиваться это взаимодействие с использованием предложенной идеологии. За последнее время многие сделали шаги в направлении данной концепции, в том числе и основные социальные сети. C неподдельным интересом наблюдая за развитием сервисов, реализующих данную идею, как и у многих, у меня возник свой взгляд на проблематику, чем я и хотел поделится.
Общие пожелания к развитию таких сетей можно выразить следующими тезисами:
- В таких сетях никогда не будет пьяных фоток, или, точнее, они будут, но их будут видеть только те, кто сам этого захочет;
- В таких сетях будут обсуждать полезные вещи и решать насущные проблемы;
- Будет важно то, что ты пишешь, а не сколько у тебя подписчиков;
- Мы будем сами решать, что будет у нас в ленте, а не наши социальные связи;
- Любая точка зрения имеет право на существование. Любой человек может принимать её, либо не принимать, а технология должна создавать человеку выбор, каким путем идти;
- Спама нет – «самомодерируемое» сообщество очень быстро выносит спамеров за границу релевантности запроса.
Образ «идеальной социальной сети» представляет из себя «окно» в многомерное информационное пространство. Это «окно» позиционируется таким образом, чтобы предоставить человеку срез той информации, которая отвечает его текущим потребностям. Потребности в данном контексте можно условно разделить на два информационных потока — обновления от сфер, с кем поддерживается постоянный контакт и обновления в сферах, которые пользователю интересны. Новые социальные связи образуются посредствам локальных кругов общения. Собеседники видят активность друг друга в контексте пересекающихся интересов. Приватные данные играют меньшую роль. Важно кем ты являешься, а не сколько лет твоей собаке, и где ты в данный момент находишься.
Рай уже здесь?
Если рассматривать шаги основных социальных сетей в данном направлении то это:
- Хештеги;
- Страницы интересов;
- Группы.
Справедливости ради, надо сказать, что хэштэги реализуют похожий функционал, но цитируя комментарий к одной из статей — «если я хочу читать, что пишут про изоморфически-паллиативный диссонанс, то по какому хэштэгу мне в твиттере поиск делать?» У многих людей складывается ощущение, что теги — вещ полезная и мощная, но чего-то не хватает. Главной проблемой тегов является множественность написания тега с одним значением (в том числе на других языках), и наоборот — одинаковое написание тегов с множественным значением.
О группах надо сказать отдельно. Возможно спроецировать группы на интересы, по сути это тот же интерес, к которому привязывается активность — это и есть прототип группы «единомышленников». Причем если тебе не комфортно в глобальном интересе-группе, можно «спустится глубже». Но у каждой группы есть критическая масса участников. Если людей больше, это становится причиной «разрушения» большой группы и/или образования более мелких групп идентичной тематики. Многие вспоминают конференции usenet, а также fido: «Когда там было мало народу, было интересно, когда же количество людей выросло, самые лучшие ушли».
Проблема групп еще и в том, что они имеют чёткие границы. Ты либо участник группы, либо нет. Публикация принадлежит группе и не покидает ее границ. В идеале, публикация должна относится с различными весовыми коэффициентами к той или иной теме/интересу/группе. Различные вещи интересуют человека в различной степени, к тому же, интересов может быть много, и просматривать группы по каждому интересу тяжело. На основе интересов можно генерировать единую ленту для пользователя.
Также необходимо отметить наличие связей между группами и их взаимоотношения друг с другом. Это толкает некоторых на изучение данного явления и использование его в своих проектах. Как раз такие связи хорошо укладываются в модель графа интересов и единомышленников, когда существуют группы единомышленников внутри одного интереса, а связи между ними осуществляются через «пограничных» (общих) пользователей. Группы «аппроксимируют» такие связи, в то время как интересы с группами единомышленников представляют их более гармонично. Еще одна проблема групп — участники этих сообществ ничего не знают о других сообществах и не хотят о них ничего слышать. Они воспринимают новое сообщество как посягательство на их территорию, что тормозит обмен ценной информацией.
Анализируя вышесказанное, можно сделать вывод, что группы в данном случае не оправдывают ожиданий. Если нужно что-то серьезное, то это, как правило, заканчивается жесткой модерацией и тоталитарными мерами со стороны администраторов групп, запрету вступлений, публикаций. В то время как интересы создают сквозные связи. Интерес (маркер, тег) гармонично реализует возможность уточняющего поиска среди несвязанных иерархий.
Мы построим новый рай
Не будем углубляться в дебри описания теории, если кратко то представим себе граф, в котором вершины – люди и интересы, а ребра – факт проявления внимания пользователя к какой-либо теме (интересу).

Такой подход реализован во многих сервисах, вдохновленных данной моделью. Пост в системе привязывается к некоторому набору тем и распространяясь по связям между всеми «поклонниками» интересов. Тем самым обеспечивая «доставку» контента в сети.
В такой системе возникает несколько важных вопросов:
- Как вести базу интересов?
- Как ранжировать контент под одним интересом?
- Неверно указанные интересы публикации.
- Неполно указанные интересы публикации.
База интересов
Можно отдать базу тем на откуп пользователям. Как показывает практика, это приводит к хаосу, база переполняется дублями и ничего не значащими темами.
Можно фиксировать каталог и наполнять его силами администраторов сервиса по мере надобности. Это влечет за собой проблему начального наполнения, трудности добавления новых тем, а следовательно и развития ресурса.
Наилучшим выходом видится взять за основу уже существующий рубрикатор. На ум сразу приходит Википедия. Это отлично структурированная база знаний, которая идеально подходит на роль каталога рубрик. Каждая ее статья – это рубрика, к которой может привязаться пост.
Ранжирование контента под одним интересом
Ранжирование контента — довольно сложная тема, на которую написано достаточное количество статей. Если вспомнить группы в соцсетях, то появление групп схожей/одинаковой тематики можно рассматривать как некую попытку ранжирования контента внутри сети под одним интересом.
Некоторые темы могут по-разному восприниматься людьми. Вопрос релевантности довольно сложен. Разные люди хотят видеть различный контент в одном и том же интересе. Допустим я выбираю тему «.NET Framework». Лично меня не интересуют статьи начального уровня на тему как написать Hello World. Хотелось бы отсечь данные материалы и получить в выдаче были более-менее интересные мне. Так как источников много, все они содержат контент различной ценности, хотелось бы получить инструмент, помогающий с поисками действительно интересных публикаций.
Решать большинством (средним по больнице) – плохой вариант, так как у каждого из нас разные требования к качеству контента и взгляды на жизнь. Поэтому в данном случае лучше подойдут различные алгоритмы рекомендаций и персонализации выдачи, на тему которых написано не мало материала. Скажу сразу, я сторонник применения данного подхода, я верю в математику и большие данные. Но с другой стороны, присутствует скептическое отношение к данным технологиям. В частности, существует понятие «пузыря фильтров», получившее достаточную поддержку.
Вот как описывает Википедия Пузырь фильтров. Понятие разработанное Илаем Парайзером, это явление, при котором веб-сайты используют алгоритмы выборочного угадывания, какую информацию пользователь хотел бы увидеть, основываясь на информации о его месторасположении, прошлых нажатиях и перемещениях мыши и его истории поиска. В результате веб-сайты показывают только информацию, которая согласуется с прошлыми точками зрения данного пользователя. Это похоже на явление, в котором люди и организации ищут информацию, которая изначально кажется им правильной, но она оказывается совершенно бесполезной или почти бесполезной, и избегают информацию, кажущуюся и воспринимаемую ими как неправильную и несущественную, но оказывающуюся полезной.
Парайзер в своей книге «The Filter Bubble» предупреждает, что потенциальным недостатком фильтрации поисковых запросов является то, что она «закрывает нас от новых идей, предметов и важной информации» и «создаёт впечатление того, что наши узкие собственные интересы и есть всё, что существует и окружает нас». Это приносит потенциальный вред как для личности, так и для общества в целом. Свобода выбора очень важна — человек сам находит информацию и сам определяет ее полезность.
Мне очень понравился комментарий к одной из статей на тему персонализации: «Так бы мы своих суженных никогда бы не встретили. Жили бы с похожими на нас хакершами». Тем не менее, американские комиссии по временному освобождению используют специальный компьютерный алгоритм, который на основе 50–100 факторов рекомендует, что делать с конкретным заключённым. На мой взгляд проблема не в самой персонализации, а в отсутствии средств управления данным инструментом (кроме как включить/выключить).
Возможно предположить, что в такой сети интересующая пользователя информация будет достигать его быстрее. Пользователь будет получать качественный контент (по его личному мнению) с большей долей вероятности.
Неверно указанные интересы публикации
Некоторые пользователи, стремясь достичь максимального распространения своих публикаций, формируют избыточный набор нерелевантных для них тем. Этим они рушат саму суть проекта. Нужен действенный инструмент ограждения сервиса от превращения в помойку.
Как показывает практика Хабра, должны быть люди, которые будут «собирать» и упорядочивать информацию. Но в идеале хотелось бы отдать задачу на откуп алгоритмам.
Неполно указанные интересы публикации
Основная задача при воплощении концепции «графа интересов» — сделать так, чтобы любая информация привязывалась ко всем интересам, к которым она имеет отношение, но при этом чтобы эти интересы имели разный вес относительно друг друга. И чтобы этот вес интересов формировал бы более точную доставку информации для тех, кто в ней действительно заинтересован. В данном случае может помочь автоматическое рубрицирование контента.
Эпилог
Каждая из вышеописанных задач заслуживает отдельного обсуждения. Надо сказать, что они с разной степенью успеха решаются различными проектами, в том числе упоминаемыми на Хабре.
В дальнейшем хотелось бы рассказать о своем решении. Поделиться мыслями на тему трудностей реализации каждой из них, причем как технических, так и алгоритмических.
Спасибо за то, что уделили время данной публикации.
