В данной статье я бы хотел ответить на один из вопросов, сформулированных в Проблемы читателя. Рай где-то рядом?. Суть в следующем. У нас есть система в которую поступают текстовые сообщения, нам необходимо для каждого сообщения сформировать набор викистраниц, релевантных тексту. Допустим есть текст – «Барак Обама встретился с Путиным». На выходе должны быть ссылки на страницы Википедии «Барак Обама» и «Путин В.В». Опишем один из возможных алгоритмов.
И так, пусть
freq(A) – частота встречаемости словосочетания A в тексте страниц Википедии в виде ссылки или простого текста. То есть допустим A = “дед мороз”. Тогда freq(“дед мороз”) – это сколько раз данный текст встречается на страницах Википедии. Естественно надо учитывать различные формы, для это используем один из алгоритмов лематизации или стеминга.
link(A) – частота встречаемости словосочетания А как ссылки на страницах Википедии. link(дед мороз) – сколько раз это словосочетание является ссылкой на всех страницах вики. link(A) <= freq(A) – это думаю очевидно.
lp(A) = link(A)/freq(A) – вероятность того, что A – ссылка. То есть, что A вообще надо рассматривать как кандидата на викификацию в тексте.
Pg(A) – все страницы Википедии на которые ссылаются ссылки с текстом A.
link(p,A) – сколько раз ссылки с текстом А ссылаются на страницу p.
P(p|A) – вероятность того, что A ссылается на страницу p. Вычисляется как link(p,A)/Pg(A). Аннотирование текста А напрямую зависит от вероятности P(p|А)
Cтроим табличку с вычислениями link(А) и lp(А). Потом выбрасываем все, где link(А) < 2 или lp(А) < 0.1, оставленные элементы формируют словарь linkP. На основе данного словаря будем выбирать словосочетания из текста. Пороги можно брать свои. Чем выше порог, тем меньше будет кандидатов на викификацию. Соответственно перед построением, все A приводим к начальной форме.
Но если мы будем оперировать только P(p|A), то результаты получаться сомнительными, так как смысл во много зависит от контекста, поэтому мы идем дальше. Для этого нам понадобится данные о зависимости страниц Википедии.
Для всех страниц вычисляем зависимость на основе Google distance.

Где in(p) – множество страниц ссылающихся на p, |W| — количество страниц в Википедии. Сохраняем эти данные для пар страниц у которых их коэффициент больше некоторого порогового значения.
Как говорилось выше, какую страницу сопоставить словосочетанию во многом зависит от контекста, поэтому рассчитываем влияние контекста.
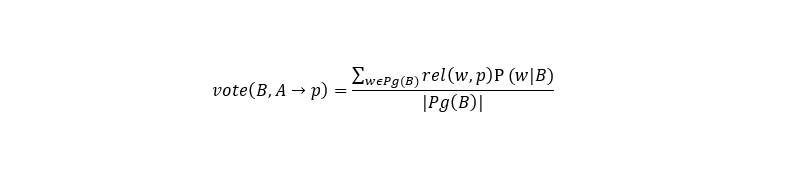
Где B, A – выделенные из текста словосочетания, которым надо сопоставить викистраницы, p – викистраница, вариант сопоставления для А. Общая формула для выбора будет иметь следующий вид.
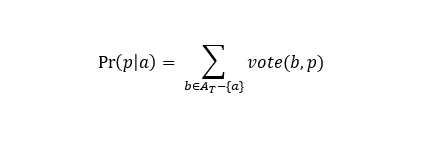
Вероятность того, что а надо сопоставить страницу p, Aт – выделенные словосочетания из текста А (кандидаты на сопоставление страницам).
В общем случае шаги алгоритма следующие.
Для реализации данного алгоритма нам понадобятся следующие таблицы.
linkP – служит для выделения из текста кандидатов на викификацию.
Common – для нахождения вариантов сопоставления страницы словосочетанию, а также вычисления основной формулы.
Related – для вычисления основной формулы.
Сам алгоритм довольно прост, но возникают трудности при реализации. В частности, размеры хранимых данных довольно большие, а поиск должен отнимать минимум времени. В одной из реализаций встречалось построение в памяти индексов с использованием lucene, после чего по данным индексам производился поиск. Основная проблема состоит в работе с таблицей Related. Если хранить данные в базе, то процесс обработки текста занимает довольно продолжительное время, в случае хранения в памяти понадобятся значительные объемы последней.
Все алгоритмы викификации с которыми я сталкивался были построены на вышеописанном принципе, с небольшими отличиями. Интересно было бы посмотреть на реализацию с использованием нейронных сетей, но таких работ я не встречал.
И так, пусть
freq(A) – частота встречаемости словосочетания A в тексте страниц Википедии в виде ссылки или простого текста. То есть допустим A = “дед мороз”. Тогда freq(“дед мороз”) – это сколько раз данный текст встречается на страницах Википедии. Естественно надо учитывать различные формы, для это используем один из алгоритмов лематизации или стеминга.
link(A) – частота встречаемости словосочетания А как ссылки на страницах Википедии. link(дед мороз) – сколько раз это словосочетание является ссылкой на всех страницах вики. link(A) <= freq(A) – это думаю очевидно.
lp(A) = link(A)/freq(A) – вероятность того, что A – ссылка. То есть, что A вообще надо рассматривать как кандидата на викификацию в тексте.
Pg(A) – все страницы Википедии на которые ссылаются ссылки с текстом A.
link(p,A) – сколько раз ссылки с текстом А ссылаются на страницу p.
P(p|A) – вероятность того, что A ссылается на страницу p. Вычисляется как link(p,A)/Pg(A). Аннотирование текста А напрямую зависит от вероятности P(p|А)
Cтроим табличку с вычислениями link(А) и lp(А). Потом выбрасываем все, где link(А) < 2 или lp(А) < 0.1, оставленные элементы формируют словарь linkP. На основе данного словаря будем выбирать словосочетания из текста. Пороги можно брать свои. Чем выше порог, тем меньше будет кандидатов на викификацию. Соответственно перед построением, все A приводим к начальной форме.
Но если мы будем оперировать только P(p|A), то результаты получаться сомнительными, так как смысл во много зависит от контекста, поэтому мы идем дальше. Для этого нам понадобится данные о зависимости страниц Википедии.
Для всех страниц вычисляем зависимость на основе Google distance.
Где in(p) – множество страниц ссылающихся на p, |W| — количество страниц в Википедии. Сохраняем эти данные для пар страниц у которых их коэффициент больше некоторого порогового значения.
Как говорилось выше, какую страницу сопоставить словосочетанию во многом зависит от контекста, поэтому рассчитываем влияние контекста.
Где B, A – выделенные из текста словосочетания, которым надо сопоставить викистраницы, p – викистраница, вариант сопоставления для А. Общая формула для выбора будет иметь следующий вид.
Вероятность того, что а надо сопоставить страницу p, Aт – выделенные словосочетания из текста А (кандидаты на сопоставление страницам).
В общем случае шаги алгоритма следующие.
- Полученный текст токенизируем и стемим.
- Выделяем в нем все словосочетания длинной до N (выбираем сами из расчета доступности ресурсов).
- Смотрим наличие выделенных словосочетаний в словаре linkP (все встречающиеся в Википедии тексты ссылок у которых вероятности того, что они ссылки больше нашего порога). Формируем Aт – выделенные словосочетания из текста и встречающиеся в словаре linkP.
- Если встречаем случай, что a, b – выделенные словосочетания, оба в словаре linkP и a подстрока b, то сравниваем lp(a) и lp(b) если lp(a) < lp(b) выбрасываем ее из Aт. Таким образом избавляемся от случаев, когда у нас a = «apple» b = «apple computers». Если lp(a) >= lp (b), то смотрим freq(a) и freq(b). Если freq(a) > freq(b) то, скорее всего, а — ничего не значащий элемент и тоже избавляемся от него.
- Для каждого словосочетания строим набор кандидатов на сопоставление на основании P(p|a) > 0 (общей вероятности, a принадлежит Aт). То есть находим все доступные варианты сопоставления.
- Рассчитываем Pr(p|a) на основании составленных наборов.
- Выбираем p c наибольшим Pr(p|a) для каждого a.
Для реализации данного алгоритма нам понадобятся следующие таблицы.
linkP – служит для выделения из текста кандидатов на викификацию.
- A — словосочетание, встречающееся в Википедии в виде ссылки;
- lp(A);
- freq(A).
Common – для нахождения вариантов сопоставления страницы словосочетанию, а также вычисления основной формулы.
- A — словосочетание, встречающееся в Википедии в виде ссылки;
- p — id страницы Википедии;
- P(p|A) – вероятность того, что A ссылается на страницу p.
Related – для вычисления основной формулы.
- Страница вики p1;
- Страница вики p2;
- rel(p1,p2).
Заключение
Сам алгоритм довольно прост, но возникают трудности при реализации. В частности, размеры хранимых данных довольно большие, а поиск должен отнимать минимум времени. В одной из реализаций встречалось построение в памяти индексов с использованием lucene, после чего по данным индексам производился поиск. Основная проблема состоит в работе с таблицей Related. Если хранить данные в базе, то процесс обработки текста занимает довольно продолжительное время, в случае хранения в памяти понадобятся значительные объемы последней.
Все алгоритмы викификации с которыми я сталкивался были построены на вышеописанном принципе, с небольшими отличиями. Интересно было бы посмотреть на реализацию с использованием нейронных сетей, но таких работ я не встречал.
