В последнем выпуске Радио-Т мы упоминали TokuMX — High-Performance MongoDB Distribution. Продукт этот звучит интересно — 9ти кратное сжатие данных в комплекте с 20ти кратным приростом скорости и поддержкой транзакций. При этом переход с mongo на tokumx весьма прост и с точки зрения внешнего наблюдателя — полностью прозрачен. Такое волшебство показалось мне более чем привлекательным и я решил проверить насколько все хорошо на практике.
Сейчас я использую несколько mongodb систем разного размера, как в AWS так и в частных дата центрах. Мой паттерн использования в основном ориентирован на редкую, но массивную запись данных (раз в день), несколько более частые массивные операции чтения (набор разнообразных анализов) и постоянное чтения в режиме обеспечения данными фронтэнды. Никаких особых проблем с монгой у меня нет, за исключением подступающей (по расчетом через 6 месяцев) проблемы диска. Данные из нашей системы никогда не удаляются и в конце концов перестанут влезать на диски. В AWS монга бежит на относительно дорогих EBS томах с гарантированным IOPS. Я уже планировал конвенциональное решение проблемы отсутствия места на диске (перенос старых данных на отдельную монгу в дешевой конфигурации), но тут попалась на глаза TokuMX с обещанием сжатия в 9 раз, что отложило бы мою проблему на следующие 4 года. Кроме того, откат записи в монге делается только со стороны клиента, и было бы неплохо обойтись без этого, но перенести на уровень сервера.
Если вам интересно, как именно работает магия TokuMX, то добро пожаловать на их сайт. Здесь я не буду рассказывать что это такое и как его настроить, но поделюсь результатами поверхностного тестирования. Мои тесты не претендуют на научную аккуратность и основной целью имеют показать, что будет в моих реальных системах если перейти с монги на току.
Прозрачность перехода:
С этим все прекрасно. Ни в одном из моих тестов, покрывающих работу с монгой (около 200), никаких проблем не возникло. Все, что работало с монгой работает и с току. Интеграционные тесты тоже не выявили никаких проблем, т.е. в моем случае можно перенаправить клиентские системы на адреса TokuMX и они продолжат работу не заметив подмены. Режим гибридной работы монги с току в одном replica set я не тестировал, но подозреваю что и это будет работать.
Тестирование записи :
Тесты производились на 2х идентичных виртуальных машинках с 2мя процессорами на каждую, 20G диска и 1G RAM. Хостовый компьютер — MBPR i7, SSD, 16G RAM. Встявляись записи (trade candles) за один день, всего 1.4М свечек. Средний размер записи 270 байт. 3 дополнительных индекса (один простой, 2 композитных).

Как видим, разница есть и TokuMX реально быстрее. Конечно не в обещанные 20 раз, но тоже неплохо. Хотя при этом и наблюдается значительно большая нагрузка на процессор, но подобное можно ожидать в связи с компрессией.
Размер данных + индексы в TokuMX тоже оказался меньше, чем у монги, но всего в 1.6 раза.
Тестирование чтения:
Чтение тестировалось в режиме близком к реальному использованию. Все быстрые запросы (по тикеру) проводились многократно для случайной выборки из 200 тикеров, всего 10000 запросов, результат усреднялся. Интервальные (по времени) запросы проводились для 10-ти случайных интервалов и тоже многократно. В монгу и току посылались одни и те же запросы в одинаковом порядке. Основная цель этого теста была создать активность, максимально близкую к реальной. Время приведено в микросекундах.
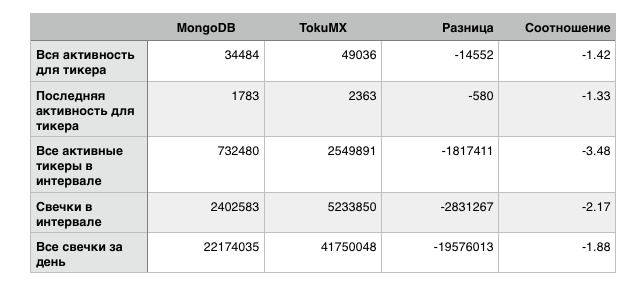
Не поверив своим глазам, я провел эти тесты многократно и подобный результат (с небольшими флуктуациями) повторялся стабильно. Во всех моих тестах подобная разница, где монго обгоняет tokumx в полтора — три раза, неизменно воспроизводилась.
Решив, что возможно дело в том, что для TokuMX надо больше CPU, я провел неравный бой где виртуалка с toku с 4мя процессорами соревновалась с монгой на двух. Результат несколько лучше, но все равно монго остается быстрее даже в этих, неравных условиях (разница в среднем в 1.4 раза). Единственный тест, в котором току обошла монгу (почти в 2 раза) это последний — все свечки за день.
Подумав, как бы все это потестировать еще, я уменьшил объем RAM для обоих конкурсантов, чтоб набор данных не помещался в памяти. Получил вот такие результаты:
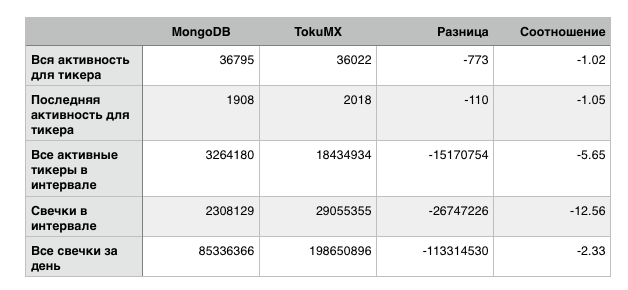
В целом этот результат выглядит еще хуже и разница в 12 раз не вызывает особого оптимизма. Однако первые два теста заметно ближе к монге, и в моем случае общий результат видимо будет сравним, т.к. подобных “улучшенных” запросов у меня многократно больше, чем сильно просевших.
В процессе тестирования в малом количестве памяти, натолкнулся на некую странную особенность току — если заданный объем кеша не помещается в доступный RAM, току просто обрезает ответ и конечно клиентская сторона от этого приходит в сильное недоумение и начинает кричать, что данные закончились раньше чем ожидалось.
И еще одно — во всех этих тестах была монго “из коробки”. Для TokuMX я сделал послабление в последнем тесте — активировал direct IO и задал размер кэша как рекомендовано у них в руководстве.
Выводы:
Мой предварительный вывод такой: то, что TokuMX пишет про себя, а именно “в 20 раз быстрее и в 9 раз компактнее из коробки”, в моем случае не совсем правда. Практически все операции чтения были медленнее (иногда значительно медленнее) в TokuMX и пугающе тихое обрезание ответа тоже не радует. Для меня поддержка транзакций, ускорение записи в 1.4 раза (при этом нет лока на базу, но только на документ) и выигрыш в размере данных в 1.6 раза, не стоят значительного проседания производительности всех операций чтения.
Сейчас я использую несколько mongodb систем разного размера, как в AWS так и в частных дата центрах. Мой паттерн использования в основном ориентирован на редкую, но массивную запись данных (раз в день), несколько более частые массивные операции чтения (набор разнообразных анализов) и постоянное чтения в режиме обеспечения данными фронтэнды. Никаких особых проблем с монгой у меня нет, за исключением подступающей (по расчетом через 6 месяцев) проблемы диска. Данные из нашей системы никогда не удаляются и в конце концов перестанут влезать на диски. В AWS монга бежит на относительно дорогих EBS томах с гарантированным IOPS. Я уже планировал конвенциональное решение проблемы отсутствия места на диске (перенос старых данных на отдельную монгу в дешевой конфигурации), но тут попалась на глаза TokuMX с обещанием сжатия в 9 раз, что отложило бы мою проблему на следующие 4 года. Кроме того, откат записи в монге делается только со стороны клиента, и было бы неплохо обойтись без этого, но перенести на уровень сервера.
Если вам интересно, как именно работает магия TokuMX, то добро пожаловать на их сайт. Здесь я не буду рассказывать что это такое и как его настроить, но поделюсь результатами поверхностного тестирования. Мои тесты не претендуют на научную аккуратность и основной целью имеют показать, что будет в моих реальных системах если перейти с монги на току.
Прозрачность перехода:
С этим все прекрасно. Ни в одном из моих тестов, покрывающих работу с монгой (около 200), никаких проблем не возникло. Все, что работало с монгой работает и с току. Интеграционные тесты тоже не выявили никаких проблем, т.е. в моем случае можно перенаправить клиентские системы на адреса TokuMX и они продолжат работу не заметив подмены. Режим гибридной работы монги с току в одном replica set я не тестировал, но подозреваю что и это будет работать.
Тестирование записи :
Тесты производились на 2х идентичных виртуальных машинках с 2мя процессорами на каждую, 20G диска и 1G RAM. Хостовый компьютер — MBPR i7, SSD, 16G RAM. Встявляись записи (trade candles) за один день, всего 1.4М свечек. Средний размер записи 270 байт. 3 дополнительных индекса (один простой, 2 композитных).
Как видим, разница есть и TokuMX реально быстрее. Конечно не в обещанные 20 раз, но тоже неплохо. Хотя при этом и наблюдается значительно большая нагрузка на процессор, но подобное можно ожидать в связи с компрессией.
Размер данных + индексы в TokuMX тоже оказался меньше, чем у монги, но всего в 1.6 раза.
Тестирование чтения:
Чтение тестировалось в режиме близком к реальному использованию. Все быстрые запросы (по тикеру) проводились многократно для случайной выборки из 200 тикеров, всего 10000 запросов, результат усреднялся. Интервальные (по времени) запросы проводились для 10-ти случайных интервалов и тоже многократно. В монгу и току посылались одни и те же запросы в одинаковом порядке. Основная цель этого теста была создать активность, максимально близкую к реальной. Время приведено в микросекундах.
Не поверив своим глазам, я провел эти тесты многократно и подобный результат (с небольшими флуктуациями) повторялся стабильно. Во всех моих тестах подобная разница, где монго обгоняет tokumx в полтора — три раза, неизменно воспроизводилась.
Решив, что возможно дело в том, что для TokuMX надо больше CPU, я провел неравный бой где виртуалка с toku с 4мя процессорами соревновалась с монгой на двух. Результат несколько лучше, но все равно монго остается быстрее даже в этих, неравных условиях (разница в среднем в 1.4 раза). Единственный тест, в котором току обошла монгу (почти в 2 раза) это последний — все свечки за день.
Подумав, как бы все это потестировать еще, я уменьшил объем RAM для обоих конкурсантов, чтоб набор данных не помещался в памяти. Получил вот такие результаты:
В целом этот результат выглядит еще хуже и разница в 12 раз не вызывает особого оптимизма. Однако первые два теста заметно ближе к монге, и в моем случае общий результат видимо будет сравним, т.к. подобных “улучшенных” запросов у меня многократно больше, чем сильно просевших.
В процессе тестирования в малом количестве памяти, натолкнулся на некую странную особенность току — если заданный объем кеша не помещается в доступный RAM, току просто обрезает ответ и конечно клиентская сторона от этого приходит в сильное недоумение и начинает кричать, что данные закончились раньше чем ожидалось.
И еще одно — во всех этих тестах была монго “из коробки”. Для TokuMX я сделал послабление в последнем тесте — активировал direct IO и задал размер кэша как рекомендовано у них в руководстве.
Выводы:
Мой предварительный вывод такой: то, что TokuMX пишет про себя, а именно “в 20 раз быстрее и в 9 раз компактнее из коробки”, в моем случае не совсем правда. Практически все операции чтения были медленнее (иногда значительно медленнее) в TokuMX и пугающе тихое обрезание ответа тоже не радует. Для меня поддержка транзакций, ускорение записи в 1.4 раза (при этом нет лока на базу, но только на документ) и выигрыш в размере данных в 1.6 раза, не стоят значительного проседания производительности всех операций чтения.
