
Начатый процесс переписывания ядра PHP идет семимильными шагами. Эта статья вольный пересказ поста одного из авторов кода ядра PHP о достигнутых значительных успехах в оптимизации такой структуры данных, как hashtable. Больше технических подробностей под катом.
Простой скрипт, который создает массив из 100000 целых чисел, демонстрирует следующие результаты:
| 32 bit | 64 bit | |
|---|---|---|
| PHP 5.6 | 7.37 MiB | 13.97 MiB |
| PHP 7.0 | 3.00 MiB | 4.00 MiB |
Код теста
$startMemory = memory_get_usage();
$array = range(1, 100000);
echo memory_get_usage() - $startMemory, " bytes\n";
PHP 7, как можно видеть, потребляет в 2.5 меньше памяти в 32-х разрядной версии и в 3.5 раза в 64-х разрядной, что согласитесь впечатляет.
Лирическое отступление
В сущности в PHP все массивы это упорядоченные словари (т.е они представляют собой упорядоченный список пар вида ключ-значение), где ассоциирование ключа значению реализовано на основе hashtable. Сделано это для того, чтобы ключами массива могли выступать не только целочисленные типы, а и сложные типы вроде строк. Сам процесс происходит следующим образом — от ключа массива берется хэш, который представлен целым числом. Это целое число используется как индекс в массиве.
Проблема возникает, когда хэширующая функция возвращает одинаковые хэши для разных ключей, то есть возникает коллизия (то, что это действительно происходит легко убедится – количество возможных ключей бесконечно велико, в то время как количество хэшей ограничено размером типа integer).
Существуют два способа борьбы с коллизиями. Первый – открытая адресация, когда элемент сохраняется с другим индексом, если текущий уже занят, второй – хранить элементы с одинаковым индексом в связном списке. PHP использует второй способ.
Обычно элементы hashtable никак не упорядочены. Но в PHP делая итерацию по массиву, мы получаем элементы именно в том порядке, в котором мы их туда записывали. Это означает, что hashtable должна поддерживать механизм хранения порядка элементов.
Старый механизм работы hashtable
Эта схема наглядно демонстрирует принцип работы hashtable в PHP 5:

Элементы разрешения коллизий на схеме обозначены как buckets (корзина). Для каждой такой «корзины» выделяется память. На картинке не показаны значения, которые хранятся в «корзинах», так как они помещаются в отдельные zval-структуры размером 16 или 24 байта. Также на картинке опущен связный список, который хранит порядок элементов массива. Для массива, который содержит ключи «a», «b», «c» он будет выглядеть так:
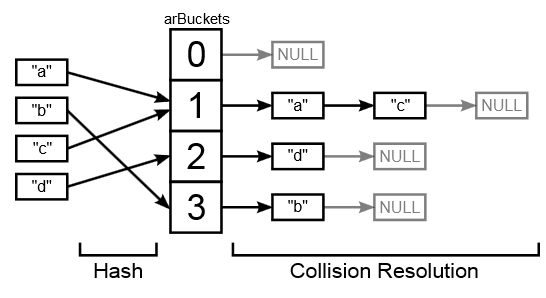
Итак, почему старая структура неэффективна в плане производительности и потребляемой памяти?
- «Корзины» требуют выделения места. Этот процесс довольно медленный и дополнительно требует 8 или 16 байт оверхеда в адресном заголовке. Это не позволяет эффективно использовать память и кэш.
- Структуры zval для данных также требует выделения места. Проблемы с памятью и оверхом заголовка все те же, что и у «корзины», плюс использование zval обязывает нас хранить указатель на него в каждой «корзине»
- Два связных списка требуют в сумме 4 указателя на корзину (т.к. списки двунаправленные). Это отнимает у нас еще от 16 до 32 байт. Кроме того, перемещение по связному списку это операция, которая плохо поддается кешированию.
Новая реализация hashtable призвана решить эти недостатки. Структура zval была переписана таким образом, чтобы ее можно было напрямую включать в сложные объекты (например, в вышеупомянутую «корзину»), а сама «корзина» стала выглядеть так:
typedef struct _Bucket {
zend_ulong h;
zend_string *key;
zval val;
} Bucket;То есть «корзина» стала включать в себя хеш h, ключ key и значение val. Целочисленные ключи сохраняются в переменной h (в таком случае хеш и ключ идентичны).
Давайте взглянем на всю структуру целиком:
typedef struct _HashTable {
uint32_t nTableSize;
uint32_t nTableMask;
uint32_t nNumUsed;
uint32_t nNumOfElements;
zend_long nNextFreeElement;
Bucket *arData;
uint32_t *arHash;
dtor_func_t pDestructor;
uint32_t nInternalPointer;
union {
struct {
ZEND_ENDIAN_LOHI_3(
zend_uchar flags,
zend_uchar nApplyCount,
uint16_t reserve)
} v;
uint32_t flags;
} u;
} HashTable;«Корзины» хранятся в массиве arData. Этот массив кратен степени двойки и его текущий размер хранится в переменной nTableSize (минимальный размер 8). Реальный размер массива хранится в nNumOfElements. Заметьте, что массив теперь включает в себя все «корзины», вместо того чтобы хранить указатели на них.
Порядок элементов
Массив arData теперь хранит элементы в порядке их вставки. При удалении из массива элемент помечается меткой IS_UNDEF и не учитывается в дальнейшем. То есть при удалении элемент физически остается в массиве пока счетчик занятых ячеек не достигнет размера nTableSize. При достижении этого лимита PHP попытается перестроить массив.
Такой подход позволяет сэкономить 8/16 байт на указателях, по сравнению с PHP 5. Приятным бонусом также будет то, что теперь итерация по массиву будет означать линейное сканирование памяти, что гораздо более эффективно для кеширования, чем обход связного списка.
Единственным недостатком остается неуменьшающийся размер arData, что потенциально может привести к значительному потреблению памяти на массивах в миллионы элементов.
Обход Hashtable
Хэшем заведует функция DJBX33A, которая возвращает 32-х или 64-х битное беззнаковое целое, что слишком много для использования в качестве индекса. Для этого выполняем операцию «И» с хэшем и размером таблицы уменьшенным на единицу и результат записываем в переменную ht->nTableMask. Индекс получаем в результате операции
idx = ht->arHash[hash & ht->nTableMask]Полученный индекс будет соответствовать первому элементу в массиве коллизий. То есть ht->arData[idx] это первый элемент, который нам нужно проверить. Если хранимый там ключ соответствует требуемому, то заканчиваем поиск. В противном случае следуем к следующему элементу до тех пор пока не найдем искомый или не получим INVALID_IDX, что будет означать что данный ключ не существует.
Прелесть такого подхода заключается в том, что в отличии от PHP 5, нам больше не требуется двусвязный список.
Сжатые и пустые hashtable
PHP использует hashtable для всех массивов. Но в определенных случаях, например, когда ключи массива целые, это не совсем рационально. В PHP 7 для этого применяется сжатие hashtable. Массив arHash в таком случае равен NULL и поиск идет по индексам arData. К сожалению, такая оптимизация применима, только если ключи идут по возрастанию, т.е. для массива [1 => 2, 0 => 1] сжатие применено не будет.
Пустые hashtable это особый случай в PHP 5 и PHP 7. Практика показывает, что пустой массив имеет неплохие шансы таковым и остаться. В этом случае массивы arData/arHash будет проинициализированы только когда первый элмент будет вставлен в hashtable. Для того чтобы избежать костылей и проверок используется следующий прием: пока меньше или равно своему значению по-умолчанию, nTableMask устанавливается в ноль. Это означает, что выражение hash & ht->nTableMask всегда будет равно нулю. В этом случае массив arHash содержит всего один элемент с нулевым индексом, который содержит значение INVALID_IDX. При итерации по массиву мы всегда ищем до первого встреченного значения INVALID_IDX, что в нашем случае будет означать массив нулевого размера, что и требуется от пустого hashtable.
Итог
Все вышеперечисленные оптимизации позволили сократить занимаемый элементом размер с 144 байт в PHP 5 до 36 (32 в случае сжатия) байт в PHP 7. Небольшой недостаток новой реализации – слегка избыточное выделение памяти и отсутствие ускорения, если все значения массива одинаковы. Напомню, что в PHP 5 в этом случае используется всего один zval, так что уменьшение потребление памяти значительное:
Код теста
$startMemory = memory_get_usage();
$array = array_fill(0, 100000, 42);
echo memory_get_usage() - $startMemory, " bytes\n";
| 32 bit | 64 bit | |
|---|---|---|
| PHP 5.6 | 4.70 MiB | 9.39 MiB |
| PHP 7.0 | 3.00 MiB | 4.00 MiB |
Несмотря на это, PHP 7 все равно показывает лучшую эффективность.
