Привет, дорогой читатель!
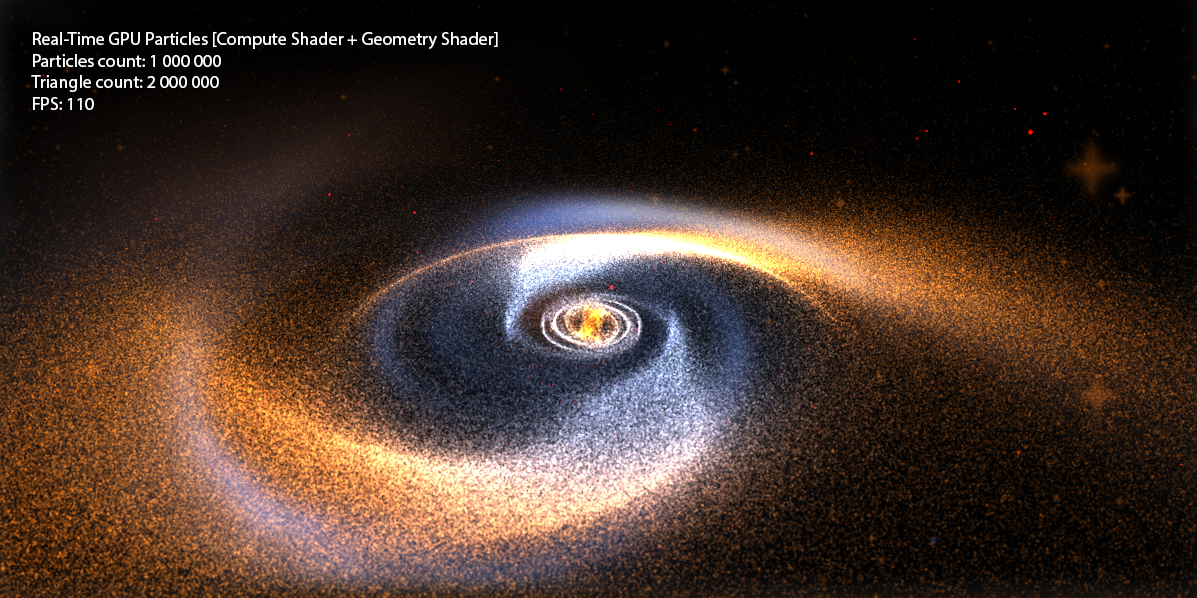
Сегодня мы продолжим изучение графического конвейера, и я расскажу о таких замечательных вещах, как Compute Shader и Geometry Shader на примере создания системы на 1000000+ частиц, которые в свою очередь являются не точками, а квадратами (billboard quads) и имеют свою текстуру. Другими словами, мы выведем 2000000+ текстурированных треугольников при FPS > 100 (на бюджетной видеокарте GeForce 550 Ti).
Я очень много писал о шейдерах среди своих статей, но оперировали мы всегда только двумя типами: Vertex Shader, Pixel Shader. Однако, с появлением DX10+ появились новые типы шейдеров: Geometry Shader, Domain Shader, Hull Shader, Compute Shader. На всякий случай напомню, как выглядит графический конвейер сейчас:

Сразу оговорюсь, что в этой статье мы не затронем Domain Shader и Hull Shader, про тесселяцию я напишу в следующих статьях.
Неизученным остается только Geometry Shader. Что же такое Geometry Shader?
Vertex Shader занимается обработкой вертексов, Pixel Shader занимается обработкой пикселей, и как можно догадаться – Geometry Shader занимается обработкой примитивов.
Этот шейдер является опциональной частью конвейера, т.е. его вовсе может и не быть: вертексы напрямую поступают в Primitive Assembly Stage и дальше идет растеризация примитива.
Geometry Shader находится между Primitive Assembly Stage и Rasterizer Stage.
На вход он может получить информацию как о собранном примитиве, так и о соседних примитивах:

На выходе у нас есть поток примитивов, куда мы в свою очередь добавляем примитив. Причем тип возвращаемого примитива может отличается от входного. К примеру – получаем Point, возвращаем Line. Пример простого геометрического шейдера, который ничего не делает и просто соединяет вход с выходом:
В DirectX10+ появился такой тип буферов как Structured Buffer, такой буфер может быть описан программистом как ему угодно, т.е. в самом классическом понимании – это однородный массив структур определенного типа, который хранится в памяти GPU.
Давайте попробуем создать подобный буфер для нашей системы частиц. Опишем какими свойствами обладает частица (на стороне C#):
И создадим сам буфер (с использованием хелпера SharpDX.Toolkit):
Где initialParticles – массив GPUParticleData с размером в нужное кол-во частиц.
Стоит отметить, что флаги при создании буфера устанавливаются следующие:
BufferFlags.ShaderResource – для возможности обращение к буферу из шейдера
BufferFlags.StructuredBuffer – указывает на принадлежность буфера
BufferFlags.UnorderedAccess – для возможности изменения буфера из шейдера
Создадим буфер размером в 1 000 000 элементов и заполним его случайными элементами:
После чего у нас в памяти GPU будет храниться буфер из 1 000 000 элементов со случайными значениями.
Теперь необходимо придумать, как же нам отрисовать этот буфер? Ведь у нас даже нет вертексов! Вертексы мы будет генерировать на ходу, исходя из значений нашего структурного буфера.
Создадим два шейдера – Vertex Shader и Pixel Shader.
Для начала, опишем входные данные для шейдеров:
Ну и рассмотрим более подробно шейдеры, для начала, вертексный:
В этой стране магии – мы просто читаем из буфера частиц конкретную частицу по текущему VertexID (а он у нас лежит в пределах от 0 до 999999) и используя позицию частицы – проектируем в экранное пространство.
Ну а с Pixel Shader проще простого:
Задаем цвет частицы как float4(0.1, 0.1, 0.1, 1). Почему 0.1? Потому, что частиц у нас миллион, и мы будем использовать Additive Blending.
Зададим буферы и отрисуем геометрию:
Ну и полюбуемся первой победой:

Если вы не забыли первую главу, то можно смело превратить наш набор точек в полноценные Billboard-ы, состоящие из двух треугольников.
Чуть-чуть расскажу о том, что такое QuadBillboard: это квадрат выполненный из двух треугольников и этот квадрат всегда повернут к камере.
Как создать этот квадрат? Нам нужно придумать алгоритм быстрой генерации подобных квадратов. Давайте посмотрим на кое-что в Vertex Shader. Там у нас есть три пространства при построении SV_Position:
View Space как раз то, что нам нужно, ведь эти координаты находятся как раз относительно камеры и плоскость (-1 + p.x, -1 + p.y, p.z) -> (1 + p.x, 1 + p.y, p.z) созданная в этом пространстве всегда будет иметь нормаль, которая направлена на камеру.
Поэтому, кое-что изменим в шейдере:
На выход SV_Position мы будем передавать не ProjectionSpace-position, а ViewSpace-position, для того, чтобы создать новые примитивы в Geometry Shader в ViewSpace.
Добавим новую стадию:
Ну и так, как у нас есть теперь UV – мы можем прочитать текстуру в пиксельном шейдере:
Дополнительно установим сэмплер и текстуру частицы для рендера:
Проверяем, тестируем:

Теперь, все готово, у нас есть особый буфер в памяти GPU и есть рендер частиц, построенный с помощью Geometry Shader, но подобная система — статична. Можно, конечно, менять позицию на CPU, просто каждый раз читать с GPU данные буфера, менять их, а потом загружать обратно, но о какой GPU Power может идти речь? Такая система не выдержит и 100 000 частиц.
И для работы на GPU с такими буферами можно использовать особый шейдер — Compute Shader. Он находится вне традиционного render-pipeline и может использоваться отдельно.
Что же такое Compute Shader?
Своими словами, вычислительный шейдер (Compute Shader) — это особая стадия конвейера, которая заменяет все традиционные (однако все еще могут использоваться вместе с ним), позволяет выполнять произвольный код с помощь GPU, читать/записывать данные в буферы (в том числе и текстурные). Причем исполнение этого кода происходит так параллельно, как настроит разработчик.
Давайте рассмотрим выполнение самого простого кода:
В самом начале кода есть поле numthreads, которое указывает кол-во потоков в группе. Пока мы не будем использовать групповые потоки и сделаем так, чтобы на одну группу приходился один поток.
uint3 DTiD.xyz указывает на текущий поток.
Следующий этап — это запуск такого шейдера, производится он следующим образом:
В методе Dispatch мы указываем — сколько групп потоков у нас должно быть, причем максимальное кол-во каждой размерности ограниченно 65536. И если мы выполним такой код, то код шейдера на GPU выполнится один раз, т.к. у нас 1 группа потоков, в каждой группе 1 поток. Если поставить, например, Dispatch(5, 1, 1) — код шейдера на GPU выполнится пять раз, 5 групп потоков, в каждой группе 1 поток. Если при этом изменить еще и numthreads -> (5, 1, 1), то код выполнится 25 раз, причем в 5 групп потоков, в каждой группе 5 потоков. Более подробно можно рассмотреть, если взглянуть на картинку:

Теперь, вернемся к системе частиц, что у нас есть? У нас есть одномерный массив из 1 000 000 элементов и задача — обработать позиции частиц. Т.к. частицы движутся независимо друг от друга, то эту задачу можно очень хорошо распараллелить.
В DX10 (именно эту версию CS мы используем, для поддержки DX10 карт) максимальное кол-во потоков на группу потоков — 768, причем во всех трех измерениях. Я создаю 32 * 24 * 1 = 768 потоков в сумме на каждую группу потоков, т.е. наша одна группа способна обработать 768 частиц (1 поток — 1 частица). Далее, необходимо посчитать, сколько нужно групп потоков (с учетом того, что одна группа обработает 768 частиц) для того, чтобы обработать N-ое кол-во частиц.
Посчитать это можно по формуле:
После чего — мы можем вызвать Dispatch(_groupSizeX, _groupSizeY, 1), и шейдер будет способен параллельно обработать N-ое кол-во элементов.
Для доступа к конкретному элементу используют формулу:
Далее приведу обновленный код шейдера:
Тут происходит еще одна магия, мы используем наш буфер частиц как особый ресурс: RWStructuredBuffer, это означает, что мы можем читать и писать в этот буфер.
(!) Необходимое условие для записи — этот буфер должен быть при создании помечен флагом UnorderedAccess.
Ну и финальный этап, мы устанавливаем ресурс для шейдера как UnorderedAccessView наш буфер и вызываем Dispatch:
После завершения выполнения кода обязательно необходимо убрать UnorderedAccessView с шейдера, иначе мы не сможем его использовать!
Давайте что-нибудь сделаем с частицами, напишем простейший солвер:
Attractor зададим в константном буфере.
Компилируем, запускает и любуемся:
Если говорить о частицах, то ничего не мешает создать полноценную и мощную систему частиц: точки достаточно легко отсортировать (для обеспечения прозрачности), применить технику soft particles при рисовании, а так же учитывать освещение «не светящихся» частиц. Вычислительные шейдеры в основном применяются для создания эффекта Bokeh Blur (тут нужны еще геометрические), для создания Tiled Deferred Renderer, etc. Геометрические шейдеры, например, можно использовать тогда, когда необходимо сгенерировать много геометрии. Самый яркий пример — трава и частицы. К слову, применение GS и CS безграничны и ограничиваются лишь фантазией разработчика.
Традиционно прикрепляю к посту полный исходный код и демо.
P.S. для запуска демо — нужна видеокарта с поддержкой DX10 и Compute Shader.
Мне очень приятно, когда люди проявляют интерес к тому, что я пишу. И для меня очень важна реакция на статью, будь она в виде плюса или минуса с конструктивным комментарием. Так я смогу определить — какие темы больше интересны хабрасообществу, а какие нет.
Сегодня мы продолжим изучение графического конвейера, и я расскажу о таких замечательных вещах, как Compute Shader и Geometry Shader на примере создания системы на 1000000+ частиц, которые в свою очередь являются не точками, а квадратами (billboard quads) и имеют свою текстуру. Другими словами, мы выведем 2000000+ текстурированных треугольников при FPS > 100 (на бюджетной видеокарте GeForce 550 Ti).
Введение
Я очень много писал о шейдерах среди своих статей, но оперировали мы всегда только двумя типами: Vertex Shader, Pixel Shader. Однако, с появлением DX10+ появились новые типы шейдеров: Geometry Shader, Domain Shader, Hull Shader, Compute Shader. На всякий случай напомню, как выглядит графический конвейер сейчас:
Сразу оговорюсь, что в этой статье мы не затронем Domain Shader и Hull Shader, про тесселяцию я напишу в следующих статьях.
Неизученным остается только Geometry Shader. Что же такое Geometry Shader?
Глава 1: Geometry Shader
Vertex Shader занимается обработкой вертексов, Pixel Shader занимается обработкой пикселей, и как можно догадаться – Geometry Shader занимается обработкой примитивов.
Этот шейдер является опциональной частью конвейера, т.е. его вовсе может и не быть: вертексы напрямую поступают в Primitive Assembly Stage и дальше идет растеризация примитива.
Geometry Shader находится между Primitive Assembly Stage и Rasterizer Stage.
На вход он может получить информацию как о собранном примитиве, так и о соседних примитивах:
На выходе у нас есть поток примитивов, куда мы в свою очередь добавляем примитив. Причем тип возвращаемого примитива может отличается от входного. К примеру – получаем Point, возвращаем Line. Пример простого геометрического шейдера, который ничего не делает и просто соединяет вход с выходом:
struct PixelInput
{
float4 Position : SV_POSITION; // стандартный System-Value для вертекса
};
[maxvertexcount(1)] // максимальное кол-во вертексов, которое мы можем добавить
void SimpleGS( point PixelInput input[1], inout PointStream<PixelInput> stream )
{
PixelInput pointOut = input[0]; // получение вертекса
stream.Append(pointOut); // добавление вертекса
stream.RestartStrip(); // создаем примитив (для Point – требуется один вертекс)
}Глава 2: StructuredBuffer
В DirectX10+ появился такой тип буферов как Structured Buffer, такой буфер может быть описан программистом как ему угодно, т.е. в самом классическом понимании – это однородный массив структур определенного типа, который хранится в памяти GPU.
Давайте попробуем создать подобный буфер для нашей системы частиц. Опишем какими свойствами обладает частица (на стороне C#):
public struct GPUParticleData
{
public Vector3 Position;
public Vector3 Velocity;
};И создадим сам буфер (с использованием хелпера SharpDX.Toolkit):
_particlesBuffer = Buffer.Structured.New<GPUParticleData>(graphics, initialParticles, true);Где initialParticles – массив GPUParticleData с размером в нужное кол-во частиц.
Стоит отметить, что флаги при создании буфера устанавливаются следующие:
BufferFlags.ShaderResource – для возможности обращение к буферу из шейдера
BufferFlags.StructuredBuffer – указывает на принадлежность буфера
BufferFlags.UnorderedAccess – для возможности изменения буфера из шейдера
Создадим буфер размером в 1 000 000 элементов и заполним его случайными элементами:
GPUParticleData[] initialParticles = new GPUParticleData[PARTICLES_COUNT];
for (int i = 0; i < PARTICLES_COUNT; i++)
{
initialParticles[i].Position = random.NextVector3(new Vector3(-30f, -30f, -30f), new Vector3(30f, 30f, 30f));
}После чего у нас в памяти GPU будет храниться буфер из 1 000 000 элементов со случайными значениями.
Глава 3. Рендер Point-частиц
Теперь необходимо придумать, как же нам отрисовать этот буфер? Ведь у нас даже нет вертексов! Вертексы мы будет генерировать на ходу, исходя из значений нашего структурного буфера.
Создадим два шейдера – Vertex Shader и Pixel Shader.
Для начала, опишем входные данные для шейдеров:
struct Particle // описание структуры на GPU
{
float3 Position;
float3 Velocity;
};
StructuredBuffer<Particle> Particles : register(t0); // буфер частиц
cbuffer Params : register(b0) // матрицы вида и проекции
{
float4x4 View;
float4x4 Projection;
};
// т.к. вертексов у нас нет, мы можем получить текущий ID вертекса при рисовании без использования Vertex Buffer
struct VertexInput
{
uint VertexID : SV_VertexID;
};
struct PixelInput // описывает вертекс на выходе из Vertex Shader
{
float4 Position : SV_POSITION;
};
struct PixelOutput // цвет результирующего пикселя
{
float4 Color : SV_TARGET0;
};Ну и рассмотрим более подробно шейдеры, для начала, вертексный:
PixelInput DefaultVS(VertexInput input)
{
PixelInput output = (PixelInput)0;
Particle particle = Particles[input.VertexID];
float4 worldPosition = float4(particle.Position, 1);
float4 viewPosition = mul(worldPosition, View);
output.Position = mul(viewPosition, Projection);
return output;
}В этой стране магии – мы просто читаем из буфера частиц конкретную частицу по текущему VertexID (а он у нас лежит в пределах от 0 до 999999) и используя позицию частицы – проектируем в экранное пространство.
Ну а с Pixel Shader проще простого:
PixelOutput DefaultPS(PixelInput input)
{
PixelOutput output = (PixelOutput)0;
output.Color = float4((float3)0.1, 1);
return output;
}Задаем цвет частицы как float4(0.1, 0.1, 0.1, 1). Почему 0.1? Потому, что частиц у нас миллион, и мы будем использовать Additive Blending.
Зададим буферы и отрисуем геометрию:
graphics.ResetVertexBuffers(); // на всякий случай сбросим буферы
graphics.SetBlendState(_additiveBlendState); // включим Additive Blend State
// и установим наш буфер частиц как SRV (только чтение).
_particlesRender.Parameters["Particles"].SetResource<SharpDX.Direct3D11.ShaderResourceView>(0, _particlesBuffer);
// матрицы
_particlesRender.Parameters["View"].SetValue(camera.View);
_particlesRender.Parameters["Projection"].SetValue(camera.Projection);
// установим шейдер
_particlesRender.CurrentTechnique.Passes[0].Apply();
// выполним отрисвоку 1000000 частиц в виде точек
graphics.Draw(PrimitiveType.PointList, PARTICLES_COUNT);Ну и полюбуемся первой победой:
Глава 4: Рендер QuadBillboard-частиц
Если вы не забыли первую главу, то можно смело превратить наш набор точек в полноценные Billboard-ы, состоящие из двух треугольников.
Чуть-чуть расскажу о том, что такое QuadBillboard: это квадрат выполненный из двух треугольников и этот квадрат всегда повернут к камере.
Как создать этот квадрат? Нам нужно придумать алгоритм быстрой генерации подобных квадратов. Давайте посмотрим на кое-что в Vertex Shader. Там у нас есть три пространства при построении SV_Position:
- World Space – позиция вертекса в мировых координатах
- View Space – позиция вертекса в видовых координатах
- Projection Space – позиция вертекса в экранных координатах
View Space как раз то, что нам нужно, ведь эти координаты находятся как раз относительно камеры и плоскость (-1 + p.x, -1 + p.y, p.z) -> (1 + p.x, 1 + p.y, p.z) созданная в этом пространстве всегда будет иметь нормаль, которая направлена на камеру.
Поэтому, кое-что изменим в шейдере:
PixelInput TriangleVS(VertexInput input)
{
PixelInput output = (PixelInput)0;
Particle particle = Particles[input.VertexID];
float4 worldPosition = float4(particle.Position, 1);
float4 viewPosition = mul(worldPosition, View);
output.Position = viewPosition;
output.UV = 0;
return output;
}На выход SV_Position мы будем передавать не ProjectionSpace-position, а ViewSpace-position, для того, чтобы создать новые примитивы в Geometry Shader в ViewSpace.
Добавим новую стадию:
// функция изменения вертекса и последующая проекция его в Projection Space
PixelInput _offsetNprojected(PixelInput data, float2 offset, float2 uv)
{
data.Position.xy += offset;
data.Position = mul(data.Position, Projection);
data.UV = uv;
return data;
}
[maxvertexcount(4)] // результат работы GS – 4 вертекса, которые образуют TriangleStrip
void TriangleGS( point PixelInput input[1], inout TriangleStream<PixelInput> stream )
{
PixelInput pointOut = input[0];
const float size = 0.1f; // размер конченого квадрата
// описание квадрата
stream.Append( _offsetNprojected(pointOut, float2(-1,-1) * size, float2(0, 0)) );
stream.Append( _offsetNprojected(pointOut, float2(-1, 1) * size, float2(0, 1)) );
stream.Append( _offsetNprojected(pointOut, float2( 1,-1) * size, float2(1, 0)) );
stream.Append( _offsetNprojected(pointOut, float2( 1, 1) * size, float2(1, 1)) );
// создать TriangleStrip
stream.RestartStrip();
}Ну и так, как у нас есть теперь UV – мы можем прочитать текстуру в пиксельном шейдере:
PixelOutput TrianglePS(PixelInput input)
{
PixelOutput output = (PixelOutput)0;
float particle = ParticleTexture.Sample(ParticleSampler, input.UV).x * 0.3;
output.Color = float4((float3)particle, 1);
return output;
}Дополнительно установим сэмплер и текстуру частицы для рендера:
_particlesRender.Parameters["ParticleSampler"].SetResource<SamplerState>(_particleSampler);
_particlesRender.Parameters["ParticleTexture"].SetResource<Texture2D>(_particleTexture);Проверяем, тестируем:
Глава 5: Движение частиц
Теперь, все готово, у нас есть особый буфер в памяти GPU и есть рендер частиц, построенный с помощью Geometry Shader, но подобная система — статична. Можно, конечно, менять позицию на CPU, просто каждый раз читать с GPU данные буфера, менять их, а потом загружать обратно, но о какой GPU Power может идти речь? Такая система не выдержит и 100 000 частиц.
И для работы на GPU с такими буферами можно использовать особый шейдер — Compute Shader. Он находится вне традиционного render-pipeline и может использоваться отдельно.
Что же такое Compute Shader?
Своими словами, вычислительный шейдер (Compute Shader) — это особая стадия конвейера, которая заменяет все традиционные (однако все еще могут использоваться вместе с ним), позволяет выполнять произвольный код с помощь GPU, читать/записывать данные в буферы (в том числе и текстурные). Причем исполнение этого кода происходит так параллельно, как настроит разработчик.
Давайте рассмотрим выполнение самого простого кода:
[numthreads(1, 1, 1)]
void DefaultCS( uint3 DTiD: SV_DispatchThreadID )
{
// DTiD.xyz - текущий поток
// ... произвольный код
}
technique ComputeShader
{
pass DefaultPass
{
Profile = 10.0;
ComputeShader = DefaultCS;
}
}В самом начале кода есть поле numthreads, которое указывает кол-во потоков в группе. Пока мы не будем использовать групповые потоки и сделаем так, чтобы на одну группу приходился один поток.
uint3 DTiD.xyz указывает на текущий поток.
Следующий этап — это запуск такого шейдера, производится он следующим образом:
_effect.CurrentTechnique.Passes[0].Apply();
graphics.Dispatch(1, 1, 1);В методе Dispatch мы указываем — сколько групп потоков у нас должно быть, причем максимальное кол-во каждой размерности ограниченно 65536. И если мы выполним такой код, то код шейдера на GPU выполнится один раз, т.к. у нас 1 группа потоков, в каждой группе 1 поток. Если поставить, например, Dispatch(5, 1, 1) — код шейдера на GPU выполнится пять раз, 5 групп потоков, в каждой группе 1 поток. Если при этом изменить еще и numthreads -> (5, 1, 1), то код выполнится 25 раз, причем в 5 групп потоков, в каждой группе 5 потоков. Более подробно можно рассмотреть, если взглянуть на картинку:
Теперь, вернемся к системе частиц, что у нас есть? У нас есть одномерный массив из 1 000 000 элементов и задача — обработать позиции частиц. Т.к. частицы движутся независимо друг от друга, то эту задачу можно очень хорошо распараллелить.
В DX10 (именно эту версию CS мы используем, для поддержки DX10 карт) максимальное кол-во потоков на группу потоков — 768, причем во всех трех измерениях. Я создаю 32 * 24 * 1 = 768 потоков в сумме на каждую группу потоков, т.е. наша одна группа способна обработать 768 частиц (1 поток — 1 частица). Далее, необходимо посчитать, сколько нужно групп потоков (с учетом того, что одна группа обработает 768 частиц) для того, чтобы обработать N-ое кол-во частиц.
Посчитать это можно по формуле:
int numGroups = (PARTICLES_COUNT % 768 != 0) ? ((PARTICLES_COUNT / 768) + 1) : (PARTICLES_COUNT / 768);
double secondRoot= System.Math.Pow((double)numGroups, (double)(1.0 / 2.0));
secondRoot= System.Math.Ceiling(secondRoot);
_groupSizeX = _groupSizeY = (int)secondRoot;После чего — мы можем вызвать Dispatch(_groupSizeX, _groupSizeY, 1), и шейдер будет способен параллельно обработать N-ое кол-во элементов.
Для доступа к конкретному элементу используют формулу:
uint index = groupID.x * THREAD_IN_GROUP_TOTAL + groupID.y * GROUP_COUNT_Y * THREAD_IN_GROUP_TOTAL + groupIndex; Далее приведу обновленный код шейдера:
struct Particle
{
float3 Position;
float3 Velocity;
};
cbuffer Handler : register(c0)
{
int GroupDim;
uint MaxParticles;
float DeltaTime;
};
RWStructuredBuffer<Particle> Particles : register(u0);
#define THREAD_GROUP_X 32
#define THREAD_GROUP_Y 24
#define THREAD_GROUP_TOTAL 768
[numthreads(THREAD_GROUP_X, THREAD_GROUP_Y, 1)]
void DefaultCS( uint3 groupID : SV_GroupID, uint groupIndex : SV_GroupIndex )
{
uint index = groupID.x * THREAD_GROUP_TOTAL + groupID.y * GroupDim * THREAD_GROUP_TOTAL + groupIndex;
[flatten]
if(index >= MaxParticles)
return;
Particle particle = Particles[index];
float3 position = particle.Position;
float3 velocity = particle.Velocity;
// payload
particle.Position = position + velocity * DeltaTime;
particle.Velocity = velocity;
Particles[index] = particle;
}
technique ParticleSolver
{
pass DefaultPass
{
Profile = 10.0;
ComputeShader = DefaultCS;
}
}Тут происходит еще одна магия, мы используем наш буфер частиц как особый ресурс: RWStructuredBuffer, это означает, что мы можем читать и писать в этот буфер.
(!) Необходимое условие для записи — этот буфер должен быть при создании помечен флагом UnorderedAccess.
Ну и финальный этап, мы устанавливаем ресурс для шейдера как UnorderedAccessView наш буфер и вызываем Dispatch:
/* SOLVE PARTICLES */
_particlesSolver.Parameters["GroupDim"].SetValue(_threadGroupSize);
_particlesSolver.Parameters["MaxParticles"].SetValue(PARTICLES_COUNT);
_particlesSolver.Parameters["DeltaTime"].SetValue(deltaTime);
_particlesSolver.Parameters["Particles"].SetResource<SharpDX.Direct3D11.UnorderedAccessView>(0, _particlesBuffer);
_particlesSolver.CurrentTechnique.Passes[0].Apply();
graphics.Dispatch(
_threadSize,
_threadSize,
1);
_particlesSolver.CurrentTechnique.Passes[0].UnApply(false);После завершения выполнения кода обязательно необходимо убрать UnorderedAccessView с шейдера, иначе мы не сможем его использовать!
Давайте что-нибудь сделаем с частицами, напишем простейший солвер:
float3 _calculate(float3 anchor, float3 position)
{
float3 direction = anchor - position;
float distance = length(direction);
direction /= distance;
return direction * max(0.01, (1 / (distance*distance)));
}
// main
{
...
velocity += _calculate(Attractor, position);
velocity += _calculate(-Attractor, position);
...
}Attractor зададим в константном буфере.
Компилируем, запускает и любуемся:
Заключение 1
Если говорить о частицах, то ничего не мешает создать полноценную и мощную систему частиц: точки достаточно легко отсортировать (для обеспечения прозрачности), применить технику soft particles при рисовании, а так же учитывать освещение «не светящихся» частиц. Вычислительные шейдеры в основном применяются для создания эффекта Bokeh Blur (тут нужны еще геометрические), для создания Tiled Deferred Renderer, etc. Геометрические шейдеры, например, можно использовать тогда, когда необходимо сгенерировать много геометрии. Самый яркий пример — трава и частицы. К слову, применение GS и CS безграничны и ограничиваются лишь фантазией разработчика.
Заключение 2
Традиционно прикрепляю к посту полный исходный код и демо.
P.S. для запуска демо — нужна видеокарта с поддержкой DX10 и Compute Shader.
Заключение 3
Мне очень приятно, когда люди проявляют интерес к тому, что я пишу. И для меня очень важна реакция на статью, будь она в виде плюса или минуса с конструктивным комментарием. Так я смогу определить — какие темы больше интересны хабрасообществу, а какие нет.
