Comments 30
О сравнении чисел с плавающей запятой тут не писал только ленивый. Замечу, что (коль скоро у вас есть математики в штате) такое сравнение нужно делать на основании того, как представлено сравнение в числовых множествах, с которыми работает задача. Да, чаще всего это модуль разности (абсолютная разность), но иногда предлагают комбинацию абсолютной и относительной разности, как в этом топике.
Странно, что ничего не сказано о «настоящем» тестировании математических алгоритмов (триада «аппроксимация — устойчивость — сходимость»)
Странно, что ничего не сказано о «настоящем» тестировании математических алгоритмов (триада «аппроксимация — устойчивость — сходимость»)
Про устойчивость как раз сказано. Если ошибки, вызванные ограниченной разрядностью вещественных чисел, существенно влияют на результат — то о какой устойчивости можно говорить? Алгоритмы явно работают в зоне хаотического поведения.
Устойчивость, как правило, нужно доказывать чисто математически, например анализируя спектры операторов, входящих в задачу. Если критерий устойчивости не работает, алгоритм и при ста знаках точности насосет погрешность.
Здесь же нам привели «студенческие» проблемы. В эту копилку можно добавить «всю задачу считали в double, но один параметр посчитали во float, теперь удивляемся» и «в матлабе был красивый график, а у программы получился забор».
Здесь же нам привели «студенческие» проблемы. В эту копилку можно добавить «всю задачу считали в double, но один параметр посчитали во float, теперь удивляемся» и «в матлабе был красивый график, а у программы получился забор».
То, что алгоритм «насосёт погрешность», не всегда страшно. Правильный результат не обязан быть единственным — главное, чтобы он с нужной точностью удовлетворял заданным условиям. Особенно, когда расчёты идут с элементами случайности — и анализируется статистика нужных характеристик исходов. Правда, не представляю, как такое можно тестировать. Впрочем, и «генерация наборов входных данных» мне кажется чем-то нереальным. Когда анализируется сигнал в реальном времени, например, что можно генерировать? Синтетический гигабайт входного потока? Но, конечно, всё зависит от задачи…
Про спектр — спасибо, что напомнили. У меня уже несколько лет в промышленном коде используется решение почти вырожденной системы (отношение собственных значений — порядка 10^25), но ничего, как-то работает. Всё руки не доходят сделать ситуацию более регулярной.
Про спектр — спасибо, что напомнили. У меня уже несколько лет в промышленном коде используется решение почти вырожденной системы (отношение собственных значений — порядка 10^25), но ничего, как-то работает. Всё руки не доходят сделать ситуацию более регулярной.
Проблемы скорее не «студенческие», а «инженерные».
Было бы интересно перевести дискуссию в более инженерное русло.
Пытался ли кто-нибудь на работе доказывать устойчивость эвристического алгоритма прогнозирования, который он придумал для прогнозирования продаж молока?
Как понять, когда нужно этим заниматься, когда нет?
Было бы интересно перевести дискуссию в более инженерное русло.
Пытался ли кто-нибудь на работе доказывать устойчивость эвристического алгоритма прогнозирования, который он придумал для прогнозирования продаж молока?
Как понять, когда нужно этим заниматься, когда нет?
Если с позиции математики подходить — нужно доказывать всегда, это просто один из этапов работы добросовестного математика.
Если с позиции бизнеса подходить — если кривая работа этого решения приносит убытка больше, чем стоимость исследования ошибки. Именно исследования, потому что потом еще есть этап исправления, который по отдельному прайсу.
Если с позиции инженера: «Работает — не трогай!»
Если с позиции бизнеса подходить — если кривая работа этого решения приносит убытка больше, чем стоимость исследования ошибки. Именно исследования, потому что потом еще есть этап исправления, который по отдельному прайсу.
Если с позиции инженера: «Работает — не трогай!»
Не совсем.
В реальных данных из реальной жизни часто встречаются «круглые» значения.
После произведения математических операций над ними производные значения тоже часто получаются «круглыми».
Затем это производное значение сравнивается, например, с нулём: больше нуля или нет. В этой ситуации при прямом сравнении на "> 0" результат заранее не известен. Приходится сравнивать на "> 0 — eps".
Результат такого сравнения скорее всего существенно не влияет на результат по качеству. Но получившиеся на выходе алгоритма цифры будут другими и программиста скорее всего заставят искать ошибку там, где её нет.
В реальных данных из реальной жизни часто встречаются «круглые» значения.
После произведения математических операций над ними производные значения тоже часто получаются «круглыми».
Затем это производное значение сравнивается, например, с нулём: больше нуля или нет. В этой ситуации при прямом сравнении на "> 0" результат заранее не известен. Приходится сравнивать на "> 0 — eps".
Результат такого сравнения скорее всего существенно не влияет на результат по качеству. Но получившиеся на выходе алгоритма цифры будут другими и программиста скорее всего заставят искать ошибку там, где её нет.
Если сравнение с нулём влияет на логику выполнения алгоритма, то есть несколько вариантов.
A. От знака f(x) действительно зависит результат. Например, если f(x) > 0, то критерий пройден, в противном случае нет. Тогда ситуация, где f(x) близко к нулю, является пограничной, и оба результата выполнения допустимы. Сравнивать с 0-eps здесь смысла нет.
B. В зависимости от знака получаются разные промежуточные результаты, или даже разные результаты работы алгоритма, но на то, что увидит пользователь, они не повлияют. Например, какую диагональ 4-угольника провести при триангуляции выпуклой оболочки. Формально разные диагонали дадут разные результаты, но фактически тело (и его изображение) будет одним и тем же. Здесь тоже возиться с eps незачем — может оказаться только хуже.
C. Самый неприятный случай — когда логика программы меняется при f(x)=0. Например, когда при решении какого-нибудь дифф.уравнения мы переходим от функции 10001*exp(-x)-10000*exp(-1.0001*x) к exp(-x)*(1+x). Здесь от eps уже не отмахнёшься — если f(x) достаточно близко к нулю, то в представлении функции могут получиться слишком большие коэффициенты, и нужно искать либо баланс — когда замена eps на 0 даст меньшую ошибку, чем потеря точности — либо более регулярную модель.
В случае, если тестовый пример привёл к ситуации А, то математик сам дурак — нечего давать тесты с неустойчивым результатом.
В случае С явное сравнение с eps будет и в коде математика, и в коде программиста. И возникнет более серьёзная проблема — как быть с тестами, в которых f(x) близко к eps. Такие тесты должны быть, чтобы удостовериться в достаточно одинаковом поведении по обеим сторонам границы. Как написать сравнение, чтобы C# и MatLab давали одинаковый результат, уже непонятно. Ответ — не давать таких тестов, а предложить f(x)=eps/2 и f(x)=2*eps.
Возможно, проблема будет в случае B. По-хорошему, написать f(x) < eps надо и в MatLab, и в C# — тогда появится шанс, что на пограничном тесте логика будет одинаковой. Но ведь кроме этого потребуется, чтобы был, например, одинаковый порядок перебора коллекций — ведь выбор первого элемента множества тоже может повлиять на логику. И хуже всего в этом подходе — что если число eps/2 вы объявите отрицательным, то модель может стать противоречивой, и уже не в тестовом, а в рабочем режиме. Честное слово, я бы оставил f(x) < 0. И пусть этот пример программист разбирает вместе с математиком, чтобы быть уверенным, что разное поведение это не ошибка.
A. От знака f(x) действительно зависит результат. Например, если f(x) > 0, то критерий пройден, в противном случае нет. Тогда ситуация, где f(x) близко к нулю, является пограничной, и оба результата выполнения допустимы. Сравнивать с 0-eps здесь смысла нет.
B. В зависимости от знака получаются разные промежуточные результаты, или даже разные результаты работы алгоритма, но на то, что увидит пользователь, они не повлияют. Например, какую диагональ 4-угольника провести при триангуляции выпуклой оболочки. Формально разные диагонали дадут разные результаты, но фактически тело (и его изображение) будет одним и тем же. Здесь тоже возиться с eps незачем — может оказаться только хуже.
C. Самый неприятный случай — когда логика программы меняется при f(x)=0. Например, когда при решении какого-нибудь дифф.уравнения мы переходим от функции 10001*exp(-x)-10000*exp(-1.0001*x) к exp(-x)*(1+x). Здесь от eps уже не отмахнёшься — если f(x) достаточно близко к нулю, то в представлении функции могут получиться слишком большие коэффициенты, и нужно искать либо баланс — когда замена eps на 0 даст меньшую ошибку, чем потеря точности — либо более регулярную модель.
В случае, если тестовый пример привёл к ситуации А, то математик сам дурак — нечего давать тесты с неустойчивым результатом.
В случае С явное сравнение с eps будет и в коде математика, и в коде программиста. И возникнет более серьёзная проблема — как быть с тестами, в которых f(x) близко к eps. Такие тесты должны быть, чтобы удостовериться в достаточно одинаковом поведении по обеим сторонам границы. Как написать сравнение, чтобы C# и MatLab давали одинаковый результат, уже непонятно. Ответ — не давать таких тестов, а предложить f(x)=eps/2 и f(x)=2*eps.
Возможно, проблема будет в случае B. По-хорошему, написать f(x) < eps надо и в MatLab, и в C# — тогда появится шанс, что на пограничном тесте логика будет одинаковой. Но ведь кроме этого потребуется, чтобы был, например, одинаковый порядок перебора коллекций — ведь выбор первого элемента множества тоже может повлиять на логику. И хуже всего в этом подходе — что если число eps/2 вы объявите отрицательным, то модель может стать противоречивой, и уже не в тестовом, а в рабочем режиме. Честное слово, я бы оставил f(x) < 0. И пусть этот пример программист разбирает вместе с математиком, чтобы быть уверенным, что разное поведение это не ошибка.
Я думаю, что математики знаю определение и устойчивости, и сходимости, включая неточное представление чисел — они не зря численные методы в приложении к диплому имеют, которые созданы именно для вычтеха.
Достаточно попросить их доказать вам, что они решили именно запрошенную задачу, а не что либо другое случайно или злонамеренно. Такой аппарат у них есть.
Достаточно попросить их доказать вам, что они решили именно запрошенную задачу, а не что либо другое случайно или злонамеренно. Такой аппарат у них есть.
Ценное замечание! Позволю себе перетащить в топик формулу:
Касательно «аппроксимация — устойчивость — сходимость» — этот пост по другой тематике. Но раз уж вопрос прозвучал: вы знаете хорошую статью/автора по этой теме? Применительно к IT?
a == b => if (Abs(x – y) <= EPSILON * Max(1.0f, Abs(x), Abs(y))Касательно «аппроксимация — устойчивость — сходимость» — этот пост по другой тематике. Но раз уж вопрос прозвучал: вы знаете хорошую статью/автора по этой теме? Применительно к IT?
Любой учебник по численным методам, лучше импортный (наши написаны дичайшим канцеляритом и их месседж «смотрите, какой я академический академик и какие рулезные термины я знаю»). Патанкар (Численные методы для задач теплообмена и динамики жидкости), например, написан вполне человеческим языком — его можно студентам давать для самостоятельного просвещения. Из IT там правда исходники в конце книги на последней странице (Фортран-77 конечно же), но подружиться с вычислительной математикой он поможет.
Как вариант, для тестирования везде использовать GMP, выставить точность побольше, в матлабе тоже использовать gmp-числа, а сравнивать только первые N разрядов.
Спасибо, мысль в копилку идей.
Arbitrary-precision для целых чисел в C# оказывается есть из коробки: msdn.microsoft.com/en-us/library/system.numerics.biginteger%28v=vs.110%29.aspx
Для double, правда, видимо нет.
Arbitrary-precision для целых чисел в C# оказывается есть из коробки: msdn.microsoft.com/en-us/library/system.numerics.biginteger%28v=vs.110%29.aspx
Для double, правда, видимо нет.
Он не поможет.
Проводить численные расчёты с неограниченной точностью нельзя: длина числителей и знаменателей растёт экспоненциально (за исключением особых случаев вроде вычисления определителя — когда гарантируется, что результат целый, хотя промежуточные числа рациональны).
Если будете считать с ограниченной точностью, то результаты MatLab и библиотеки из C# всё равно начнут расходиться. И если вам не хватило 15 знаков, то где гарантия, что хватит 100?
Да и программист не скажет спасибо, когда код, написанный под длинную арифметику, придётся переводить обратно на double. Особенно, если этого кода много… Ему же всю работу придётся вести в классе MyDouble, совместимом по интерфейсу с MyLongDouble. Стоит ли оно того?
Проводить численные расчёты с неограниченной точностью нельзя: длина числителей и знаменателей растёт экспоненциально (за исключением особых случаев вроде вычисления определителя — когда гарантируется, что результат целый, хотя промежуточные числа рациональны).
Если будете считать с ограниченной точностью, то результаты MatLab и библиотеки из C# всё равно начнут расходиться. И если вам не хватило 15 знаков, то где гарантия, что хватит 100?
Да и программист не скажет спасибо, когда код, написанный под длинную арифметику, придётся переводить обратно на double. Особенно, если этого кода много… Ему же всю работу придётся вести в классе MyDouble, совместимом по интерфейсу с MyLongDouble. Стоит ли оно того?
А автогенерацией кода из Матлаба не пробовали пользоваться?
Когда-то давно, когда в Matlab ещё не было .NET-интерфейса, пробовали C++-генерацию. Она работала не очень, хуже всего было то, что не все функции Matlab поддерживались.
Сейчас есть .NET-генерация, но она требует установки Matlab Redistributable Package.
Здесь два вопроса:
1) производительность такого решения
2) лицензии при установке на сервер клиента
готовых ответов у меня нет.
А вы пробовали?
Сейчас есть .NET-генерация, но она требует установки Matlab Redistributable Package.
Здесь два вопроса:
1) производительность такого решения
2) лицензии при установке на сервер клиента
готовых ответов у меня нет.
А вы пробовали?
Если говорить про программный код, то сожаление только баловался. Отвечая на второй ваш вопрос — никаких дополнительных лицензий требоваться не должно, лицензия должна быть только у вас как у разработчика на сам Матлаб (с нужными опциями).
Но на самом деле там интереснее Embedded Coder, предлагаемый для встраиваемых решений. Он порождает чистый c/c++ и не должен требовать никаких дополнительных библиотек. Да, там действительно ограниченный набор возможностей, но зато сразу из модели можно получить готовый код без этапа ручного кодирования.
Но на самом деле там интереснее Embedded Coder, предлагаемый для встраиваемых решений. Он порождает чистый c/c++ и не должен требовать никаких дополнительных библиотек. Да, там действительно ограниченный набор возможностей, но зато сразу из модели можно получить готовый код без этапа ручного кодирования.
а можно вопрос оффтоп, не сочтите за тролинг -)
что значит заточенность под высокое качество результата? разве кто намеренно и не скрывая ни от кого делает ПО заточенное под низкое качество результата? слабо могу представить компанию, продажник которой приходит к потенциальному заказчику и говорит «привет, наша ключевая особенность — заточенность под низкое качество результата» или «мы не заморачиваемся (не заточенны) над высоким качеством результата», ну или на крайняк «привет заказчик, знаете, мы делаем софт вообще говоря среднего качества, и результат будет сами понимаете каким»
Наша ключевая особенность – алгоритмы собственной разработки, заточенные под высокое качество результата.
что значит заточенность под высокое качество результата? разве кто намеренно и не скрывая ни от кого делает ПО заточенное под низкое качество результата? слабо могу представить компанию, продажник которой приходит к потенциальному заказчику и говорит «привет, наша ключевая особенность — заточенность под низкое качество результата» или «мы не заморачиваемся (не заточенны) над высоким качеством результата», ну или на крайняк «привет заказчик, знаете, мы делаем софт вообще говоря среднего качества, и результат будет сами понимаете каким»
Здесь под качеством подразумевается именно качество анализа данных, например, прогнозирования (его сравнительно легко измерить).
Большинство наших конкурентов внедряют и настраивают продукты зарубежных вендоров, а не делают свой BI-софт. При внедрении они делают упор на качество настройки процессов, а собственно прогнозирование имеет более низкий приоритет.
Прежде всего это происходит по причине отсутствия экспертизы, которые могут дать люди, одновременно разбирающиеся в математике и бизнесе (такие люди, особенно русскоговорящие — редкость). Ещё одна причина — недостатки инструментов во внедряемом софте.
Поскольку у нас есть специалисты, и свой софт, в BI-продуктах мы делаем упор на качество [прогнозирования/анализа данных], и по этому критерию били на пресейлах, например, Oracle.
Большинство наших конкурентов внедряют и настраивают продукты зарубежных вендоров, а не делают свой BI-софт. При внедрении они делают упор на качество настройки процессов, а собственно прогнозирование имеет более низкий приоритет.
Прежде всего это происходит по причине отсутствия экспертизы, которые могут дать люди, одновременно разбирающиеся в математике и бизнесе (такие люди, особенно русскоговорящие — редкость). Ещё одна причина — недостатки инструментов во внедряемом софте.
Поскольку у нас есть специалисты, и свой софт, в BI-продуктах мы делаем упор на качество [прогнозирования/анализа данных], и по этому критерию били на пресейлах, например, Oracle.
ох уж этот маркетинг имаркетологи
но мне вот все равно не понятно, у компании стоит цель допустим прогнозирование тренда в цене на нефть, к ним приходит ваш конурент и говорит: "господа, наша ключевая особенность — алгоритмы собственной разработки (или чужой, заказчику не так это важно, важен таки результат же), заточенные под отказоустойчивость/юзабилити/биг дата/скорость", у него спрашивают, а как у вас с качеством прогнозирования, а он такой "да средненькое оно у нас, но ведь это не важно, главное качество софта, у нас же трехступенчатое тестирование ПО"
а можете назвать хоть одного вашего конкурента, который позиционирует себя как софт для анализа данных, и они не говорят, что делают прогноз качественно, но говорят что остальное у них лучше все?
ну и второй вопрос, у вас получается более низкий приоритет на качество настройки процессов?
но мне вот все равно не понятно, у компании стоит цель допустим прогнозирование тренда в цене на нефть, к ним приходит ваш конурент и говорит: "господа, наша ключевая особенность — алгоритмы собственной разработки (или чужой, заказчику не так это важно, важен таки результат же), заточенные под отказоустойчивость/юзабилити/биг дата/скорость", у него спрашивают, а как у вас с качеством прогнозирования, а он такой "да средненькое оно у нас, но ведь это не важно, главное качество софта, у нас же трехступенчатое тестирование ПО"
При внедрении они делают упор на качество настройки процессов, а собственно прогнозирование имеет более низкий приоритет.
а можете назвать хоть одного вашего конкурента, который позиционирует себя как софт для анализа данных, и они не говорят, что делают прогноз качественно, но говорят что остальное у них лучше все?
ну и второй вопрос, у вас получается более низкий приоритет на качество настройки процессов?
а можете назвать хоть одного вашего конкурента, который позиционирует себя как софт для анализа данных, и они не говорят, что делают прогноз качественно, но говорят что остальное у них лучше все?
Все конечно говорят, что всё самое лучшее, но внутри приоритеты расставляются по-разному. Мы бьёмся за качество, а кто-то нет, и этот кто-то не обязательно хуже в совокупности.
ну и второй вопрос, у вас получается более низкий приоритет на качество настройки процессов?
Просто по этому параметру сложнее стать лучше конкурентов.
Все конечно говорят, что всё самое лучшее, но внутри приоритеты расставляются по-разному. Мы бьёмся за качество, а кто-то нет, и этот кто-то не обязательно хуже в совокупности.
вот вы так как бы намекаете, что среди продуктов по анализу данных (а из названия класса продуктов следует что анализ данных — это ключевой параметр этого класса ПО), есть продукты которые на самом то деле плохие, по ключевому показателю, а вы вот как бы нет
так если вы обладаете информацией о том, что кто то обманывает своих клиентов, говоря, что они крутые в аланиле данных, а вы знаете что внутри то на самом деле там все не так, так почему бы не помочь всем потенциально обманутым клиентам ваших конкурентов и не выложить в чем же там и у кого косяки?
и как вы оцениваете, что ваш продукт по качеству анализа, как вы говорите, лучше других?
давайте я приведу пример как это делается в мире, так, что бы ни у кого не возникало вопросов
вот компания baidu, а вот ее главный по науке Andrew Ng, а вот его выступление на gtc 2015, а вот его слайд про их новую собственную разработку, которая лучше всех в мире распознает лица на общедоступном бенчмарк датасете, и вот он прямо говорит, что все остальные хуже них, приводя названия компаний
слайд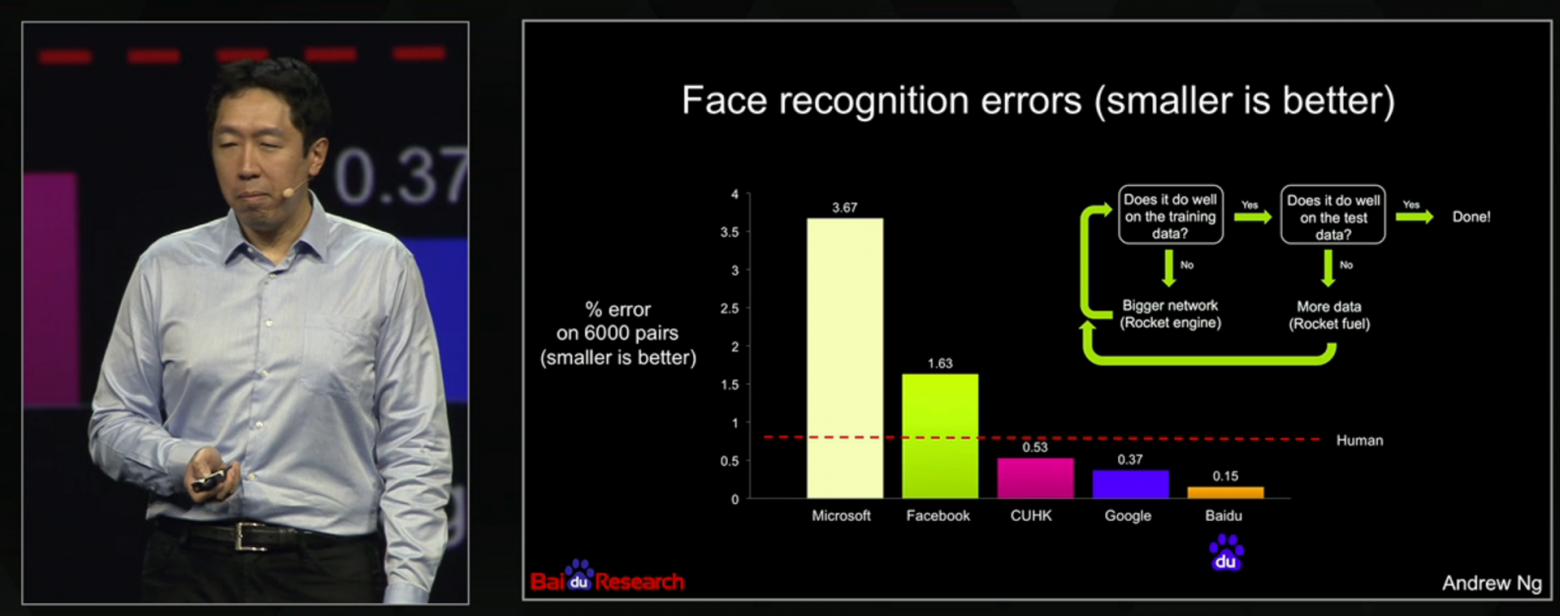
SciPy + Cython для повышения производительности. Быстрая и качественная разработка+легкая оптимизация без сильного переписывания кода. PySide для интерфейса. Если Вы считаете. что лучше использовать монстры Matlab и .NET., то это Ваши проблемы.
И главное, если у вас проблема с плавающий точкой, не забывайте, что арифметические операции +, * коммутативны, но не ассоциативны. В этом весь корень проблем.
И главное, если у вас проблема с плавающий точкой, не забывайте, что арифметические операции +, * коммутативны, но не ассоциативны. В этом весь корень проблем.
Сегодня обнаружил у себя очередную ошибку в алгоритме, написанном несколько лет назад. В алгоритме оптимизации методом наименьших квадратов при вычислении градиента пара координат вычислялась неправильно. Несмотря на это, всё работало, и после исправления лучше не стало. А вы говорите «ошибки вещественной арифметики»… Математические алгоритмы обладают громадной устойчивостью к ошибкам, их даже неправильным индексом или перепутанным знаком не собьёшь :)
Sign up to leave a comment.
Тестирование математических алгоритмов