В первой части я рассказал о кодировании видео в Linux с использованием Nvidia NVENC. Как уже упоминалось ранее, Nvidia для десктопных видеокарт ограничивает количество потоков кодирования до двух сессий на систему. Данная часть посвящена борьбе с этим ограничением.
Окружение
Всё описываемое происходит на машине с GTX 970 и установленным FFmpeg, в соответствии с конфигурацией, рассмотренной ранее.
Внешние проявления
При попытке запустить параллельно кодирование более двух потоков видео FFmpeg выдаст ошибку:
... [nvenc @ 0x3187200] OpenEncodeSessionEx failed: 0xa - invalid license key? ... Error while opening encoder for output stream #0:0 - maybe incorrect parameters such as bit_rate, rate, width or height
Чтобы постоянно и удобно воспроизводить эту ошибку, я запустил два раза перекодирование в ffmpeg и поставил процесс на паузу, послав ему SIGSTOP (Ctrl+Z в терминале):
$ /usr/local/bin/ffmpeg -y -i input.mov -vcodec nvenc output1.mp4 ... Stream mapping: Stream #0:1 -> #0:0 (mpeg4 (native) -> h264 (nvenc)) Stream #0:0 -> #0:1 (aac (native) -> aac (libfdk_aac)) Press [q] to stop, [?] for help frame= 81 fps= 80 q=0.0 size= 1362kB time=00:00:03.24 bitrate=3444.9kbits/s [1]+ Stopped /usr/local/bin/ffmpeg -y -i input.mov -vcodec nvenc out1.mp4 $ /usr/local/bin/ffmpeg -y -i input.mov -vcodec nvenc output2.mp4 ... Stream mapping: Stream #0:1 -> #0:0 (mpeg4 (native) -> h264 (nvenc)) Stream #0:0 -> #0:1 (aac (native) -> aac (libfdk_aac)) Press [q] to stop, [?] for help frame= 81 fps= 80 q=0.0 size= 1362kB time=00:00:03.24 bitrate=3444.9kbits/s [2]+ Stopped /usr/local/bin/ffmpeg -y -i input.mov -vcodec nvenc out1.mp4
ltrace
Посмотрим на это место детальнее:
$ ltrace /usr/local/bin/ffmpeg -y -i input.mov -vcodec nvenc out3.mp4 2>&1 | less
...
dlsym(0x313e360, "cuInit") = 0x7f93974182c0
dlsym(0x313e360, "cuDeviceGetCount") = 0x7f9397418760
dlsym(0x313e360, "cuDeviceGet") = 0x7f93974185c0
dlsym(0x313e360, "cuDeviceGetName") = 0x7f93974188e0
dlsym(0x313e360, "cuDeviceComputeCapability") = 0x7f9397418f80
dlsym(0x313e360, "cuCtxCreate_v2") = 0x7f9397419940
dlsym(0x313e360, "cuCtxPopCurrent_v2") = 0x7f9397419df0
dlsym(0x313e360, "cuCtxDestroy_v2") = 0x7f9397419af0
dlopen("libnvidia-encode.so.1", 1) = 0x3231970
dlsym(0x3231970, "NvEncodeAPICreateInstance") = 0x7f93970d4370
posix_memalign(0x7fffb429d490, 32, 640, 0x7fffb429d3f8) = 0
memset(0x3141420, '\0', 640) = 0x3141420
free(0) = <void>
pthread_mutex_lock(0x19a90e0, 8, 0xf8f340, 0x7fffb429d3f8) = 0
__vsnprintf_chk(0x7fffb429c3b4, 1004, 1, -1) = 20
__vsnprintf_chk(0x7fffb429cbb4, 1004, 1, -1) = 55
__snprintf_chk(0x7fffb429cfa0, 1024, 1, 1024) = 75
strcmp("[nvenc @ 0x3187200] OpenEncodeSe"..., "\n") = 81
__strcpy_chk(0x19a8cc0, 0x7fffb429cfa0, 1024, 0) = 0x19a8cc0
fputs("[nvenc @ 0x3187200] ", 0x7f93a554e1c0[nvenc @ 0x3187200] ) = 1
fputs("OpenEncodeSessionEx failed: 0xa "..., 0x7f93a554e1c0OpenEncodeSessionEx failed: 0xa - invalid license key?
) = 1
pthread_mutex_unlock(0x19a90e0, 0, 0x7fffb429cbb4, -1) = 0
...
Видно, что какая-то ошибка вывелась, но что вызывалось не видно из-за динамической загрузки библиотеки и её символов (функций).
Исходный код FFmpeg
Поищем это место в исходниках самого FFmpeg, чтобы взять его отправной точкой.
~/ffmpeg-2.7.1$ fgrep -r OpenEncodeSessionEx ... libavcodec/nvenc.c:606: nv_status = p_nvenc->nvEncOpenEncodeSessionEx(&encode_session_params, &ctx->nvencoder); libavcodec/nvenc.c:609: av_log(avctx, AV_LOG_FATAL, "OpenEncodeSessionEx failed: 0x%x - invalid license key?\n", (int)nv_status); ...
Всё понятно, тут и поставим брейкпоинт.
Светлый GDB
GNU Debugger — это основной юниксовый отладчик, предназначение которого отлаживать программы, дабы они не генерировали ошибки.
Для ориентирования в машинном коде скомпилированного приложения и соотношения его с исходным кодом, желательно чтобы приложение было скомпилировано с отладочными символами. Они, в первую очередь, содержат информацию о соответствии машинного и исходных кодов.
В большинстве дистритубивов пакеты содержат бинарные файлы с обрезанной отладочной информацией и для некоторых пакетов отладочная информация поставляется в виде отдельного пакета. В ubuntu это, как правило, пакеты с суффиксом -dbg. В centos нужно подключить репозиторий с отладочными символами и воспользоваться утилитой debuginfo-install из состава yum-utils, которая установит отладочные символы для пакета и его зависимостей.
В нашем же случае с самосборным FFmpeg, необрезанный бинарь доступен в его сборочной директории под именем ffmpeg_g. Мы можем запустить его под отладчиком и сразу поставить брейкпоинт на нужную строчку в исходном коде.
# gdb ffmpeg-2.7.1/ffmpeg_g GNU gdb (Ubuntu 7.7.1-0ubuntu5~14.04.2) 7.7.1 Copyright (C) 2014 Free Software Foundation, Inc. ... Reading symbols from ffmpeg-2.7.1/ffmpeg_g...done. (gdb)
Установим брейкпоинт на интересующее нас место:
(gdb) break nvenc.c:606 Breakpoint 1 at 0x44a890: file libavcodec/nvenc.c, line 606.
Запускаем программу, указав аргументы запуска через аргументы команде run:
(gdb) run -i in.mov -vcodec nvenc out3.mp4
...
Breakpoint 1, nvenc_encode_init (avctx=0x1b806e0) at libavcodec/nvenc.c:606
606 nv_status = p_nvenc->nvEncOpenEncodeSessionEx(&encode_session_params, &ctx->nvencoder);
(gdb) list
601 }
602
603 encode_session_params.device = ctx->cu_context;
604 encode_session_params.deviceType = NV_ENC_DEVICE_TYPE_CUDA;
605
606 nv_status = p_nvenc->nvEncOpenEncodeSessionEx(&encode_session_params, &ctx->nvencoder);
607 if (nv_status != NV_ENC_SUCCESS) {
608 ctx->nvencoder = NULL;
609 av_log(avctx, AV_LOG_FATAL, "OpenEncodeSessionEx failed: 0x%x - invalid license key?\n", (int)nv_status);
610 res = AVERROR_EXTERNAL;
(gdb)
Брейкпоинт сработал и мы действительно достигли нужного места в коде. Для удобства нажатием Ctrl+X, Ctrl+A можно переключить GDB в режим разделения командного экрана с экраном исходника.

Пройдём код пошагово до возврата этой функции.
606 nv_status = p_nvenc->nvEncOpenEncodeSessionEx(&encode_session_params, &ctx->nvencoder);
(gdb) step
603 encode_session_params.device = ctx->cu_context;
(gdb) step
606 nv_status = p_nvenc->nvEncOpenEncodeSessionEx(&encode_session_params, &ctx->nvencoder);
(gdb) step
607 if (nv_status != NV_ENC_SUCCESS) {
Последнюю введённую команду, к слову, можно повторять простым нажатием Enter. Возврат функции сохраняется в локальную переменную nv_status. Посмотрим, что же в ней:
(gdb) info locals ... nv_status = NV_ENC_ERR_OUT_OF_MEMORY ...
Убиваем висящие ffmpeg-и, в отладчике перезапускаем программу командой run. Это запустит её с теми же аргументами. Дойдя до того же места, мы увидим:
(gdb) info locals ... nv_status = NV_ENC_SUCCESS ...
Таким образом, функция создания сессии кодирования возвращает NV_ENC_SUCCESS (0) в случае успеха, либо NV_ENC_ERR_OUT_OF_MEMORY (10), если пользователь уже открыл 2 сессии кодирования. Спустимся вглубь этой функции.
Тёмный GDB
Дойдём до вызова этой функции и спустимся вглубь неё.
Breakpoint 1, nvenc_encode_init (avctx=0x1b806e0) at libavcodec/nvenc.c:606 606 nv_status = p_nvenc->nvEncOpenEncodeSessionEx(&encode_session_params, &ctx->nvencoder); (gdb) layout asm
Интерфейс GDB примет вид:

Принудительно перерисовать экран, если он оказался замусорен, можно нажатием Ctrl+L.
Указатель исполнения стоит на загрузке параметров функции перед её вызовом. Отправляемся вглубь:
(gdb) set step-mode on (gdb) step ...
Оказываемся внутри функции из /usr/lib/x86_64-linux-gnu/libnvidia-encode.so.1:
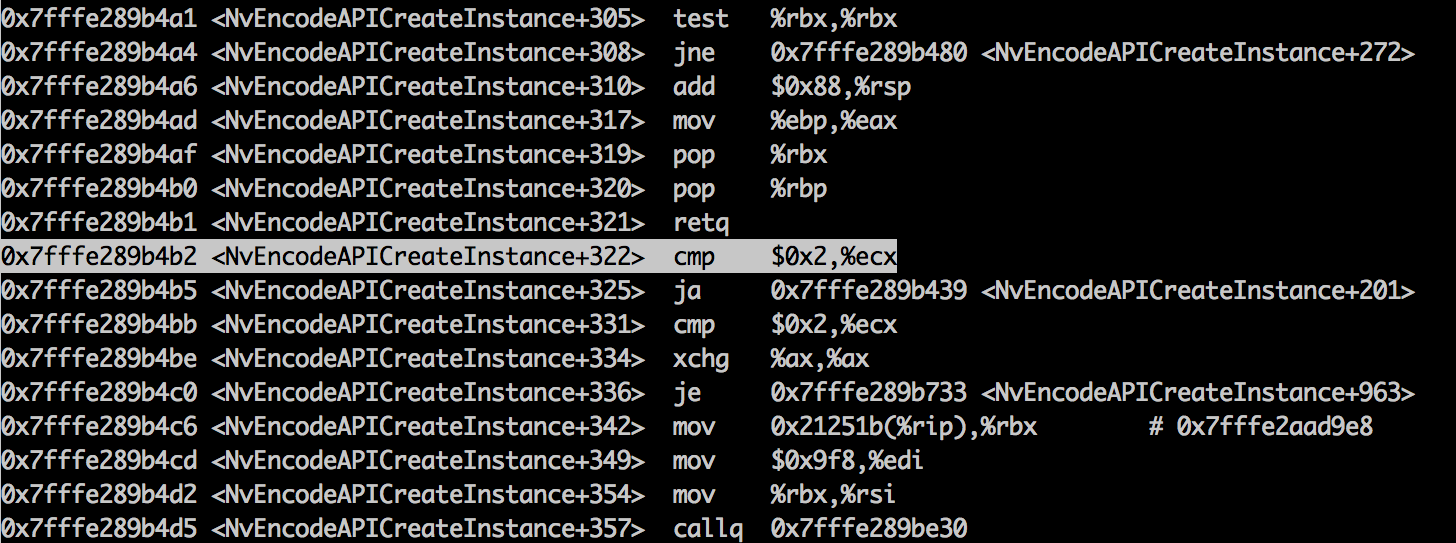
>|0x7fffe289b010 mov %rbp,-0x20(%rsp) | |0x7fffe289b015 mov %r12,-0x18(%rsp) | |0x7fffe289b01a mov $0x6,%ebp | |0x7fffe289b01f mov %rbx,-0x28(%rsp) | |0x7fffe289b024 mov %r13,-0x10(%rsp) | |0x7fffe289b029 mov %rsi,%r12 | |0x7fffe289b02c mov %r14,-0x8(%rsp) | |0x7fffe289b031 sub $0xa8,%rsp | |0x7fffe289b038 test %rdi,%rdi | |0x7fffe289b03b sete %dl | |0x7fffe289b03e test %rsi,%rsi | |0x7fffe289b041 sete %al | |0x7fffe289b044 or %al,%dl | |0x7fffe289b046 jne 0x7fffe289b060 | |0x7fffe289b048 mov (%rdi),%eax
Так проходим пошагово всю функцию, записывая на бумажке направления условных переходов. Заходя в вызовы других функций, чтобы не углубляться, сразу выходим из них командой finish. Проделываем это 2 раза, когда все кодирующие сессии заняты и когда есть свободные.
Следуя такой методологии, приходим к тому, что разветвление начинается с места:
|0x7fffe289b319 callq 0x7fffe288d510 | |0x7fffe289b31e test %eax,%eax | |0x7fffe289b320 mov %eax,%ebp | |0x7fffe289b322 jne 0x7fffe289b332 |
Функция, принимающая решение:
>|0x7fffe288d510 mov %rbx,-0x20(%rsp) | |0x7fffe288d515 mov %rbp,-0x18(%rsp) | |0x7fffe288d51a mov %rdi,%rbx | |0x7fffe288d51d mov %r12,-0x10(%rsp) | |0x7fffe288d522 mov %r13,-0x8(%rsp) | |0x7fffe288d527 sub $0x28,%rsp | |0x7fffe288d52b test %rsi,%rsi | |0x7fffe288d52e mov %rsi,%r12 | |0x7fffe288d531 mov %rcx,%r13 | |0x7fffe288d534 mov $0x6,%ebp | |0x7fffe288d539 je 0x7fffe288d54d | |0x7fffe288d53b dec %edx | |0x7fffe288d53d mov $0xa,%bpl | |0x7fffe288d540 je 0x7fffe288d568 | |0x7fffe288d542 cmpb $0x1,0x10(%rbx) | |0x7fffe288d546 je 0x7fffe288d5a3 | |0x7fffe288d548 mov $0x2,%ebp | |0x7fffe288d54d mov %ebp,%eax | |0x7fffe288d54f mov 0x8(%rsp),%rbx | |0x7fffe288d554 mov 0x10(%rsp),%rbp | |0x7fffe288d559 mov 0x18(%rsp),%r12 | |0x7fffe288d55e mov 0x20(%rsp),%r13 | |0x7fffe288d563 add $0x28,%rsp | |0x7fffe288d567 retq |
Эта функция что-то проверяет в памяти, если успешно, — то делает что-то и возвращает 0, если нет, — то 10. Ровно такой код ошибки из результата этой функции возвращает сама nvEncOpenEncodeSessionEx() в случае неудачи. Попробуем игнорировать возврат этой функции, как если бы она вернула 0.
Останавливаемся после callq 0x7fffe288d510 и перед test %eax,%eax. Обнуляем регистр с результатом функции и продолжаем свободное выполнение программы:
(gdb) set $eax = 0 (gdb) continue
Перекодировка началась! И даже производит правильные результаты. Значит необходимо, чтобы в коде всегда было так. Зафиксируем это в самой libnvidia-encode.so.1
Нужно понять где это место находится в физическом файле на диске. Узнаем какому смещению в файле соответствует виртуальный адрес в коде библиотеки, загруженной в память.
(gdb) info proc mappings
process 1692
Mapped address spaces:
Start Addr End Addr Size Offset objfile
...
0x7fffe2887000 0x7fffe28a8000 0x21000 0x0 /usr/lib/x86_64-linux-gnu/libnvidia-encode.so.346.46
...
Нас интересует окрестность адреса 0x7fffe289b31e, она попадает в этот регион. Тогда смещение в файле равно: адрес — начальный адрес + смещение сегмента.
(gdb) print/x 0x7fffe289b31e - 0x7fffe2887000 + 0x0 $7 = 0x1431e
Biew
Осталось пропатчить сам файл. Я не нашёл пока ничего лучше, чем biew (был переименован в beye). Предварительно сделав резервную копию, исправим файл:
biew /usr/lib/x86_64-linux-gnu/libnvidia-encode.so.346.46
В нём: F2 -> Disassembler, F5 -> 1431e
Получим такую картину:

Выглядит точь-в-точь как искомый код, значит мы попали верно. Нам необходимо, чтобы в регистре eax оказался 0, а условный переход не произошёл никогда.
Нажатие F4 включает режим редактирования. В biew нет такого удобного режима как в hiew, в котором можно непосредственно вводить инструкцию, а редактор её ассемблирует. Поэтому придётся манипулировать опкодами численно. Записываем, к примеру, так:
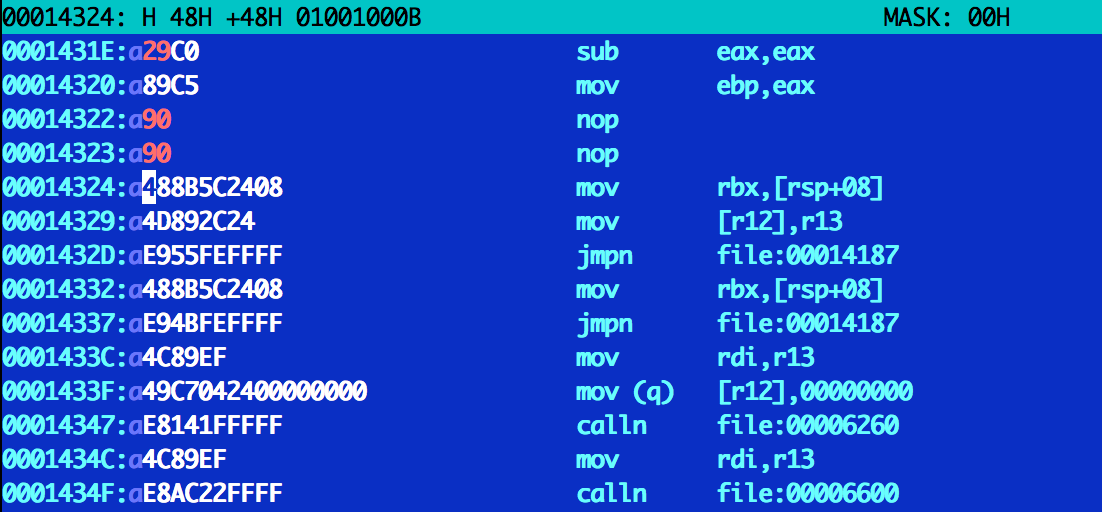
Байт по смещению 0x1431e со значения 0x85 меняем на 0x29. Инструкция «test eax, eax» превращается в «sub eax, eax». Два байта по смещениям 0x14322 и 0x14323 заменяем на 0x90 — это широко известный опкод nop.
Итог
Полученное решение вполне хорошо работает. Применив стандартные инструменты, можно достичь многого и расширить границы возможного.
