Всем привет!
Так бывает, что используемые языки программирования накладывают ограничение на то, что мы хотим сделать, доставляя неудобство при разработке. Что с этим делают разработчики? Либо смиряются, либо как-то пытаются выйти из положения.
Один из вариантов — использование автогенерации кода.
В этой статье я расскажу:
Если интересно, добро пожаловать под кат!
Исходим из того, что вы разрабатываете на языке Verilog-2001 и необходимо сделать простой мультиплексор:
Ничего сложного здесь нет.
Однако, если вы разрабатываете какой-нибудь коммутатор на 24/48 портов, то в какой-то момент вам нужен будет модуль, где будет происходить коммутация пакетов (для этого и нужны будут многопортовые мультиплексоры).
Делать вручную:
не очень правильно. В реальной жизни нужен мультиплексор не просто данных, а специализированных интерфейсов, где сигналов будет не один, а несколько на каждый из потоков данных (читай, портов).
Душа просит написать что-то типа такого:
Однако использование массивов в портах модуля не разрешается стандартом IEEE 1364-2001 (где и описан Verilog-2001).
Так, например, Quartus выдаст вот такую ошибку:
Что же делать?
Один из возможных вариантов обхода рассмотрен на StackOverflow. Идея рабочая, но статья не об этом :)
Конечно можно сдаться и сделать нужные провода ручками, но лучше чтобы за нас это сделала машина:
используем класс Template из шаблонизатора Jinja2
Мы сделали шаблон модуля, где с помощью for описали то, что нам надо продублировать, а затем дернули render, передав необходимые параметры (количество портов, название модуля и пр.). Эти параметры с помощью {{ }} можно будет использовать в шаблоне, обеспечив вставку переменных в необходимое место.
На выходе получился вот такой замечательный модуль:
Прелесть заключается в том, что в качестве переменных можно передать не просто числа или строчки, но еще и типы Python'a (листы, словари, объекты своих классов), а затем в шаблоне обращаться так же, как и в коде Python'a. Например, обращение к элементу словаря будет выглядеть так:
Конечно, это простой пример, и, скорее всего, его можно было сделать с помощью perl/sed/awk и пр.
Когда я прочитал про Jinja и поигрался с простым примером, мне стало интересно, можно ли его использовать для более серьезных вещей. Я вспомнил об одной задаче, которая возникает при FPGA разработке, которая вроде бы должна хорошо автоматизироваться. Для того, чтобы плавно подвести вас к этой задаче я немного расскажу из чего складывается разработка.
Считается, что в основе быстрой разработки под ASIC/FPGA идет использование готового кода, оформленного как IP-ядра. Не вдаваясь в подробности, можно считать, что IP-ядро это библиотека.
Идея заключается в том, что вся прошивка разбивается на IP-ядра, которые пишутся самим или покупаются,воруются/взламываются, а затем соединяются, используя стандартные интерфейсы (типа AXI или Avalon). Соединение может происходить как ручками, так и с помощью GUI приложений, где мышкой можно кликать и соединять нужные ядра. Например, Qsys, который идет в составе Quartus.
Плюсы такого подхода очевидны:
Одним из минусов считает то, что появляется оверхэд на соединение через стандартные интерфейсы: это может занимать как больше кода, так и больше ресурсов (ячеек).
У каждого ядер предусмотрен набор контрольно-статусных регистров CSR.
Чаще всего они сгруппированы по словам (например, 32-битным), где внутри разделяются по полям, у которых могут быть различные режимы работы:
В пределах одного регистра могут быть несколько полей, причем их режимы работы могут быть различны.
CSR так же есть у различных чипов, начиная от простых I2C экспандеров, заканчивая трансиверами, и даже сетевыми карточками.
Как это выглядит со стороны программистов верхнего уровня?
Рассмотрим MAC-контроллер Triple Speed Ethernet от фирмы Altera. Если откроем документацию и перейдем на главу Configuration Register Space, то увидим списов всех регистров, через которые можно как и управлять ядром, так и получать информацию о его состоянии (например, счетчики принятых/отправленных пакетов).
Приведу часть таблицы, где описаны регистры:
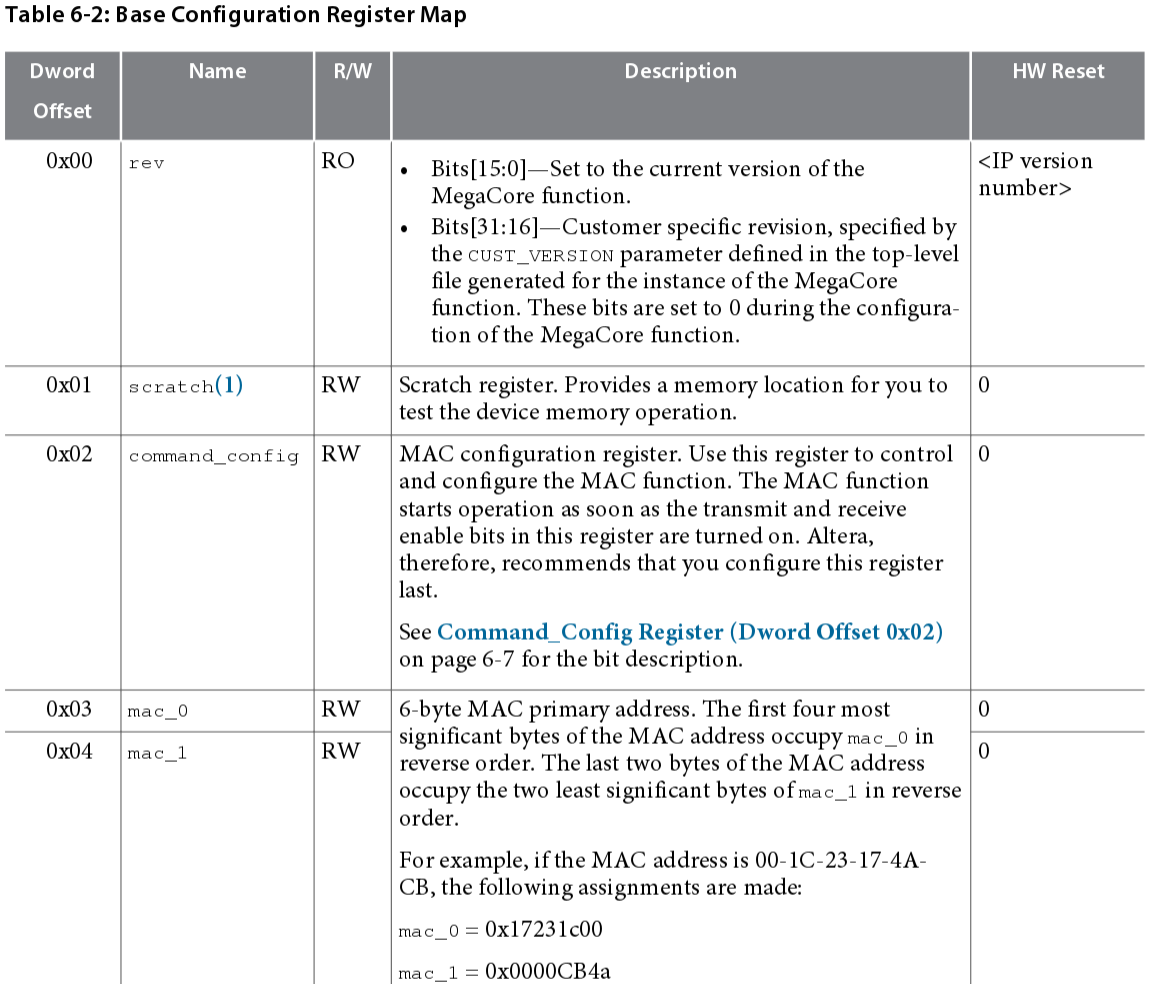
Кстати, не исключено, что пакеты, благодаря которым вы читаете эти строчки, проходили через это IP-ядро.
Например, регистры 0x03 и 0x04 в этом ядре отвечают за настройку MAC-адреса. Для какого-нибудь ядра (от Xilinx или от Intel) это могут быть другие регистры.
Вот так выглядит смена MAC-адреса в драйвере:
mac_addr_0 и mac_addr_1 это как раз наши 0x03 и 0x04, которые очень хитро (на мой субъективный взгляд, хотя допускаю, что в драйверах это нормально) определены в соседнем заголовочном файле.
Разработчики IP-ядра предоставляют документ, где описаны все CSR, а так же то, что, как и в каком порядке надо настраивать. Эта документация передается программистам высокого уровня, они в свою очередь пишут функции, аналогичные tse_update_mac_addr и заставляют это всё работать :)
Часто поставленную задачу одним ядром решить нельзя — их в системе их появляется несколько.
Интерфейсы управления можно повесить на одну шину, выделив каждому из ядер свое адресное пространство:
Если верхнему уровню надо записать в 0x03 регистр ядра B, то оно должно провести транзакцию по адресу 0x0103. (Для упрощения считаем, что адреса не байтовые, а по словам. В реальной жизни может оказаться, что надо писать по байтовым адресам, и тогда наш запрос для 32-битного регистра окажется транзакцией по адресу 0x010C).
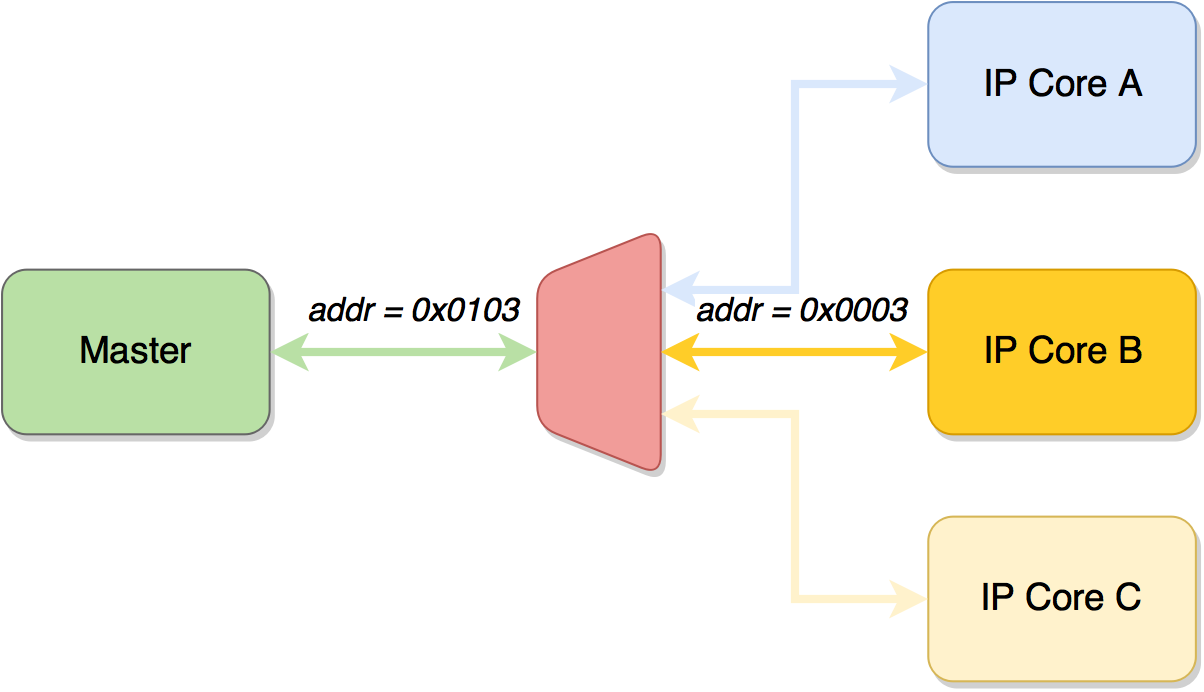
Мастер (это может быть CPU (ARM/x86) или MCU, или вообще какое-нибудь другое IP-ядро) через интерфейс управления производит транзакцию чтения или записи. Очень часто интерфейсы управления IP-ядра делают по одному из стандартов (AXI или Avalon).
Если слейвов несколько, то возникает модуль интерконнекта (мультиплексор или арбитр шины). Его задача принимать запросы от мастера и смотреть куда надо этот запрос передать, так же он может удерживать шину, пока слейв отвечает и т.д. Так, до этого модуля адрес запроса был 0x0103, а после — 0x0003, т.к. IP-ядро ничего не знает (да и не должно) какое адресное пространство за ним закреплено.
Внутри IP-ядра должен быть модуль, который и содержит все эти регистры и преобразует их в набор сигналов для управления модулями, которые находятся внутри IP-ядра, но скрыты от внешнего мира.
Для того, чтобы не говорить на пальцах, рассмотрим очень простое абстрактное IP-ядро генератора Ethernet-пакетов, которое может быть использовано, например, в измерительном оборудовании.
Пускай у это ядра будут такие регистры:
Само IP-ядро будет выглядеть примерно так:
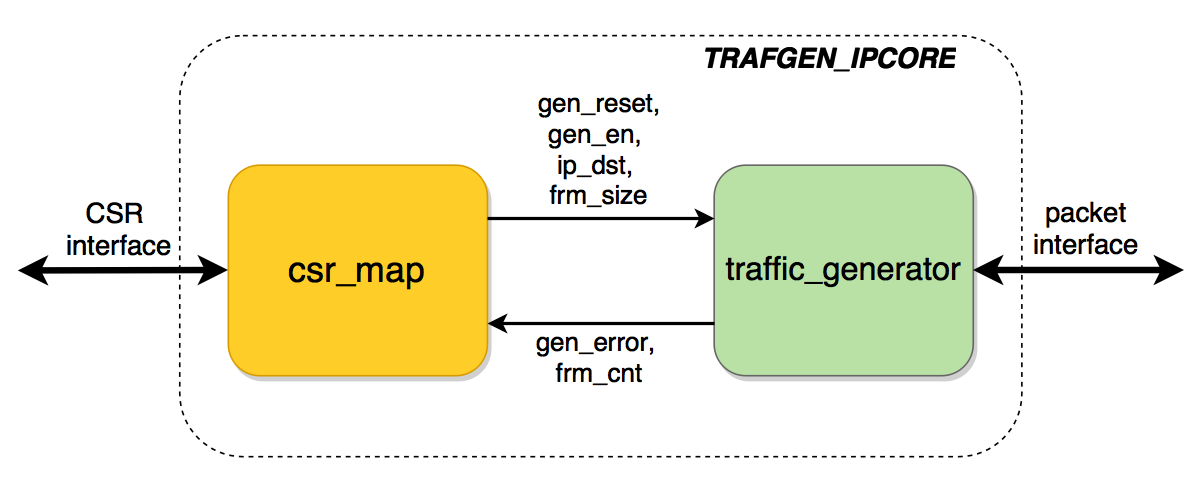
Модуль csr_map служит для того, что «перевести» стандартный интерфейс в набор сигналов управления для модуля traffic_generator, который и выполняет основую функцию ядра. Конечно, редко IP-ядро состоит только из двух модулей: скорее всего сигналы управления будут раздаваться на несколько модулей внутри IP-ядра.
Надеюсь, вы догадались, к чему я клоню:
нельзя ли этот csr_map сгенерировать автоматически из какого-нибудь описания этих регистров?
В реальной жизни регистров может быть под сотню, и если это автоматизировать, то:
Делаем два примитивных класса для хранения информации по регистрам, и по битам (полям).
Используя эти классы, создаем описание CSR:
Сам шаблон выглядит вот так:
Дергаем генерацию шаблона:
Получили вот такой модуль:
Как видим идея сработала: из простого текстового описания появился полноценный модуль, который не надо допиливать руками — можно сразу брать в продакшен)
В качестве интерфейса управления использовалось подобие Avalon-MM.
С Jinja2 я познакомился буквально пару дней назад, когда смотрел на гитхабе реализацию 1G и 10G MAC-ядер вместе с UDP/IP стеком. Кстати, написано неплохо, но я смотрел довольно-таки поверхностно и в симуляции, а тем более на железе не пробовал.
Автор использует Jinja2 для генерации различных модулей, например, N-портового мультиплексора AXI4-Stream. Этот мультиплексор намного хитрее, чем тот, который я писал в начале статьи.
Скрипт для генерации csr_map я накидал на скорую руку, чтобы прочувствовать возможности Jinja2 (уверен, оценил я её малую часть), но могу рекомендовать всем коллегам, которые занимаются разработкой под FPGA поиграться с этой библиотекой, возможно, вы сможете ускорить свою разработку за счёт автогенерации кода.
Конечно, этот скрипт сырой, и мы его еще не использовали в разработке (и я даже не знаю, будем использовать или нет, т.к. по различным причинам красивая архитектура IP-ядер иногда остается просто красивой архитектурой).
Выложил полностью исходник на гитхаб. Если этот шаблон кому-то пригодится, буду рад: готов по запросам его улучшить, либо принять чьи-то pull-request'ы)
Спасибо за внимание! Если появились вопросы, задавайте без сомнений.
Так бывает, что используемые языки программирования накладывают ограничение на то, что мы хотим сделать, доставляя неудобство при разработке. Что с этим делают разработчики? Либо смиряются, либо как-то пытаются выйти из положения.
Один из вариантов — использование автогенерации кода.
В этой статье я расскажу:
- как можно обойти одно из ограничений языка Verilog, применяемого при разработке ASIC/FPGA, используя автогенерацию кода с помощью Python и библиотеки Jinja.
- как можно ускорить разработку IP-ядер, сгенерировав модуль контрольно-статусных регистров из их описания.
Если интересно, добро пожаловать под кат!
Параметризация модулей
Исходим из того, что вы разрабатываете на языке Verilog-2001 и необходимо сделать простой мультиплексор:
module simple_mux #(
parameter D_WIDTH = 8
) (
input [D_WIDTH-1:0] data_0_i,
input [D_WIDTH-1:0] data_1_i,
input sel_i,
output [D_WIDTH-1:0] data_o
);
assign data_o = ( sel_i ) ? ( data_1_i ):
( data_0_i );
endmodule
Ничего сложного здесь нет.
Однако, если вы разрабатываете какой-нибудь коммутатор на 24/48 портов, то в какой-то момент вам нужен будет модуль, где будет происходить коммутация пакетов (для этого и нужны будут многопортовые мультиплексоры).
Делать вручную:
input [D_WIDTH-1:0] data_0_i,
input [D_WIDTH-1:0] data_1_i,
...
input [D_WIDTH-1:0] data_47_i,
не очень правильно. В реальной жизни нужен мультиплексор не просто данных, а специализированных интерфейсов, где сигналов будет не один, а несколько на каждый из потоков данных (читай, портов).
Душа просит написать что-то типа такого:
module simple_mux #(
parameter D_WIDTH = 8,
parameter PORT_CNT = 48,
// internal param
parameter SEL_WIDTH = $clog2( PORT_CNT )
) (
input [D_WIDTH-1:0] data_i [PORT_CNT-1:0],
input [SEL_WIDTH-1:0] sel_i,
output [D_WIDTH-1:0] data_o
);
assign data_o = data_i[ sel_i ];
endmodule
Однако использование массивов в портах модуля не разрешается стандартом IEEE 1364-2001 (где и описан Verilog-2001).
Так, например, Quartus выдаст вот такую ошибку:
Error (10773): Verilog HDL error: declaring module ports or function arguments with unpacked array types requires SystemVerilog extensions
Что же делать?
Скрытый текст
Использовать SystemVerilog.
Скрытый текст
:)
Один из возможных вариантов обхода рассмотрен на StackOverflow. Идея рабочая, но статья не об этом :)
Конечно можно сдаться и сделать нужные провода ручками, но лучше чтобы за нас это сделала машина:
используем класс Template из шаблонизатора Jinja2
t = Template(u"""
module {{name}} #(
parameter D_WIDTH = 8
) (
{%- for p in ports %}
input [D_WIDTH-1:0] data_{{p}}_i,
{%- endfor %}
input [{{sel_width-1}}:0] sel_i,
output [D_WIDTH-1:0] data_o
);
always @(*)
begin
case( sel_i )
{% for p in ports %}
{{sel_width}}'d{{p}}:
begin
data_o = data_{{p}}_i;
end
{% endfor %}
endcase
end
endmodule
""")
print t.render(
n = 4,
sel_width = 2,
name = "simple_mux_4habr",
ports = range( 4 )
)
Мы сделали шаблон модуля, где с помощью for описали то, что нам надо продублировать, а затем дернули render, передав необходимые параметры (количество портов, название модуля и пр.). Эти параметры с помощью {{ }} можно будет использовать в шаблоне, обеспечив вставку переменных в необходимое место.
На выходе получился вот такой замечательный модуль:
Скрытый текст
module simple_mux_4habr #(
parameter D_WIDTH = 8
) (
input [D_WIDTH-1:0] data_0_i,
input [D_WIDTH-1:0] data_1_i,
input [D_WIDTH-1:0] data_2_i,
input [D_WIDTH-1:0] data_3_i,
input [1:0] sel_i,
output [D_WIDTH-1:0] data_o
);
always @(*)
begin
case( sel_i )
2'd0:
begin
data_o = data_0_i;
end
2'd1:
begin
data_o = data_1_i;
end
2'd2:
begin
data_o = data_2_i;
end
2'd3:
begin
data_o = data_3_i;
end
endcase
end
endmodule
Прелесть заключается в том, что в качестве переменных можно передать не просто числа или строчки, но еще и типы Python'a (листы, словари, объекты своих классов), а затем в шаблоне обращаться так же, как и в коде Python'a. Например, обращение к элементу словаря будет выглядеть так:
{{ foo['bar'] }}
Конечно, это простой пример, и, скорее всего, его можно было сделать с помощью perl/sed/awk и пр.
Когда я прочитал про Jinja и поигрался с простым примером, мне стало интересно, можно ли его использовать для более серьезных вещей. Я вспомнил об одной задаче, которая возникает при FPGA разработке, которая вроде бы должна хорошо автоматизироваться. Для того, чтобы плавно подвести вас к этой задаче я немного расскажу из чего складывается разработка.
IP-ядра
Считается, что в основе быстрой разработки под ASIC/FPGA идет использование готового кода, оформленного как IP-ядра. Не вдаваясь в подробности, можно считать, что IP-ядро это библиотека.
Идея заключается в том, что вся прошивка разбивается на IP-ядра, которые пишутся самим или покупаются,
Плюсы такого подхода очевидны:
- реюз готового кода
- отдельное тестирования ядер
- стандартизация обмена данных между модулями
Одним из минусов считает то, что появляется оверхэд на соединение через стандартные интерфейсы: это может занимать как больше кода, так и больше ресурсов (ячеек).
У каждого ядер предусмотрен набор контрольно-статусных регистров CSR.
Чаще всего они сгруппированы по словам (например, 32-битным), где внутри разделяются по полям, у которых могут быть различные режимы работы:
- RW — read and write: можно писать и читать. Служат для настройки ядра (например, включение того или иного режима работы, настройка каких-то параметров и пр.).
- RW/SC — read write self clear: если записать единицу, то она сама сбросит в ноль (может быть удобно для ресета ядра или модуля ядра: ставишь единицу, а он сам сбросит себя в ноль).
- RO — read only: только читать (например, для статистики или о состояния ядра). Так же некоторые регистры делаются RO для хранения константных значений (например, версию ядра, либо его возможности (capabilities) ).
- RO/LL и RO/LH — read only latch low / latch high: еще один хитрый регистр — может служить для отслеживания аварий, к примеру, произошло переполнение фифошки (сигнал full стал равным единице), если его просто завести на RO регистр, то CPU, который читает эти регистры может это событие пропустить, т.к. это может произойти буквально на несколько тактов. Но если сделать LH, то как только там станет единица, оно защелкнется и будет ждать следующего чтения. Если этот регистр был прочитан, то значения регистра автоматически сбросится в ноль.
В пределах одного регистра могут быть несколько полей, причем их режимы работы могут быть различны.
CSR так же есть у различных чипов, начиная от простых I2C экспандеров, заканчивая трансиверами, и даже сетевыми карточками.
Как это выглядит со стороны программистов верхнего уровня?
Рассмотрим MAC-контроллер Triple Speed Ethernet от фирмы Altera. Если откроем документацию и перейдем на главу Configuration Register Space, то увидим списов всех регистров, через которые можно как и управлять ядром, так и получать информацию о его состоянии (например, счетчики принятых/отправленных пакетов).
Приведу часть таблицы, где описаны регистры:
Кстати, не исключено, что пакеты, благодаря которым вы читаете эти строчки, проходили через это IP-ядро.
Например, регистры 0x03 и 0x04 в этом ядре отвечают за настройку MAC-адреса. Для какого-нибудь ядра (от Xilinx или от Intel) это могут быть другие регистры.
Вот так выглядит смена MAC-адреса в драйвере:
static void tse_update_mac_addr(struct altera_tse_private *priv, u8 *addr)
{
u32 msb;
u32 lsb;
msb = (addr[3] << 24) | (addr[2] << 16) | (addr[1] << 8) | addr[0];
lsb = ((addr[5] << 8) | addr[4]) & 0xffff;
/* Set primary MAC address */
csrwr32(msb, priv->mac_dev, tse_csroffs(mac_addr_0));
csrwr32(lsb, priv->mac_dev, tse_csroffs(mac_addr_1));
}
mac_addr_0 и mac_addr_1 это как раз наши 0x03 и 0x04, которые очень хитро (на мой субъективный взгляд, хотя допускаю, что в драйверах это нормально) определены в соседнем заголовочном файле.
Разработчики IP-ядра предоставляют документ, где описаны все CSR, а так же то, что, как и в каком порядке надо настраивать. Эта документация передается программистам высокого уровня, они в свою очередь пишут функции, аналогичные tse_update_mac_addr и заставляют это всё работать :)
Системы из нескольких ядер
Часто поставленную задачу одним ядром решить нельзя — их в системе их появляется несколько.
Интерфейсы управления можно повесить на одну шину, выделив каждому из ядер свое адресное пространство:
- IP-ядро A: 0x0000 — 0x00FF
- IP-ядро B: 0x0100 — 0x01FF
- IP-ядро C: 0x0200 — 0x02FF
Если верхнему уровню надо записать в 0x03 регистр ядра B, то оно должно провести транзакцию по адресу 0x0103. (Для упрощения считаем, что адреса не байтовые, а по словам. В реальной жизни может оказаться, что надо писать по байтовым адресам, и тогда наш запрос для 32-битного регистра окажется транзакцией по адресу 0x010C).
Мастер (это может быть CPU (ARM/x86) или MCU, или вообще какое-нибудь другое IP-ядро) через интерфейс управления производит транзакцию чтения или записи. Очень часто интерфейсы управления IP-ядра делают по одному из стандартов (AXI или Avalon).
Если слейвов несколько, то возникает модуль интерконнекта (мультиплексор или арбитр шины). Его задача принимать запросы от мастера и смотреть куда надо этот запрос передать, так же он может удерживать шину, пока слейв отвечает и т.д. Так, до этого модуля адрес запроса был 0x0103, а после — 0x0003, т.к. IP-ядро ничего не знает (да и не должно) какое адресное пространство за ним закреплено.
Разбираем конкретное IP-ядро (обозначаем проблему)
Внутри IP-ядра должен быть модуль, который и содержит все эти регистры и преобразует их в набор сигналов для управления модулями, которые находятся внутри IP-ядра, но скрыты от внешнего мира.
Для того, чтобы не говорить на пальцах, рассмотрим очень простое абстрактное IP-ядро генератора Ethernet-пакетов, которое может быть использовано, например, в измерительном оборудовании.
Пускай у это ядра будут такие регистры:
0x0:
[7:0] - IP_CORE_VERSION [RO] - Версия IP-ядра
[15:8] - Reserved
[16] - GEN_EN [RW] - Разрешение генерации
[17] - GEN_ERROR [ROLH] - Произошла ошибка при генерации
[30:18] - Reserved
[31] - GEN_RESET [RWSC] - Сброс генератора
0x1:
[31:0] - IP_DST [RW] - IP-адрес получателя пакетов
0x2:
[15:0] - FRM_SIZE [RW] - Размер пакета
[31:16] - Reserved
0x3:
[31:0] - FRM_CNT [RO] - Количество сгенерированных пакетов
Само IP-ядро будет выглядеть примерно так:
Модуль csr_map служит для того, что «перевести» стандартный интерфейс в набор сигналов управления для модуля traffic_generator, который и выполняет основую функцию ядра. Конечно, редко IP-ядро состоит только из двух модулей: скорее всего сигналы управления будут раздаваться на несколько модулей внутри IP-ядра.
Надеюсь, вы догадались, к чему я клоню:
нельзя ли этот csr_map сгенерировать автоматически из какого-нибудь описания этих регистров?
В реальной жизни регистров может быть под сотню, и если это автоматизировать, то:
- можно избежать ошибок и неинтересной работы.
- если платят за строчки кода, то получить бонус от руководства (автосгеренный код часто много строк занимает).
- сэкономленное время потратить на чтение хабра (ну, или гиктаймса, т.к. хаб FPGA переехал туда >_<) или игру в кикер.
Решаем проблему
Делаем два примитивных класса для хранения информации по регистрам, и по битам (полям).
class Reg( ):
def __init__( self, num, name ):
self.num = '{:X}'.format( num )
self.name = name
self.name_lowcase = self.name.lower()
self.bits = []
def add_bits( self, reg_bits ):
self.bits.append( reg_bits )
class RegBits( ):
def __init__( self, bit_msb, bit_lsb, name, mode = "RW", init_value = 0 ):
self.bit_msb = bit_msb
self.bit_lsb = bit_lsb
self.width = bit_msb - bit_lsb + 1
self.name = name
self.name_lowcase = self.name.lower()
self.mode = mode
self.init_value = '{:X}'.format( init_value )
# bit modes:
# RO - read only
# RO_CONST - read only, constant value
# RO_LH - read only, latch high
# RO_LL - read only, latch low
# RW - read and write
# RW_SC - read and write, self clear
assert self.mode in ["RO", "RO_CONST", "RO_LH", "RO_LL", "RW", "RW_SC" ], "Unknown bit mode"
if self.mode in ["RO_LH", "RO_LL", "RW_SC"]:
assert self.width == 1, "Wrong width for this bit mod"
self.port_signal_input = self.mode in ["RO", "RO_LH", "RO_LL"]
self.port_signal_output = self.mode in ["RW", "RW_SC"]
self.need_port_signal = self.port_signal_input or self.port_signal_output
Используя эти классы, создаем описание CSR:
MODULE_NAME = "trafgen_map_4habr"
r0 = Reg( 0x0, "MAIN")
r0.add_bits( RegBits( 7, 0, "IP_CORE_VERSION", "RO_CONST", 0x7 ) )
r0.add_bits( RegBits( 16, 16, "GEN_EN" , "RW" ) )
r0.add_bits( RegBits( 17, 17, "GEN_ERROR", "RO_LH" ) )
r0.add_bits( RegBits( 31, 31, "GEN_RESET", "RW_SC" ) )
r1 = Reg( 0x1, "IP_DST" )
# let ip destination in reset will be 178.248.233.33 ( habrahabr.ru )
r1.add_bits( RegBits( 31, 0, "IP_DST", "RW", 0xB2F8E921 ) )
r2 = Reg( 0x2, "FRM_SIZE" )
r2.add_bits( RegBits( 15, 0, "FRM_SIZE", "RW", 64 ) )
r3 = Reg( 0x3, "FRM_CNT" )
r3.add_bits( RegBits( 31, 0, "FRM_CNT", "RO" ) )
reg_l = [r0, r1, r2, r3]
Сам шаблон выглядит вот так:
Скрытый текст
csr_map_template = Template(u"""
{%- macro reg_name( r ) -%}
reg_{{r.num}}_{{r.name_lowcase}}
{%- endmacro %}
{%- macro reg_name_bits( r, b ) -%}
reg_{{r.num}}_{{r.name_lowcase}}___{{b.name_lowcase}}
{%- endmacro %}
{%- macro bit_init_value( b ) -%}
{{b.width}}'h{{b.init_value}}
{%- endmacro %}
{%- macro signal( width ) -%}
[{{width-1}}:0]
{%- endmacro %}
{%- macro print_port_signal( dir, width, name, eol="," ) -%}
{{ " %-12s %-10s %-10s" | format( dir, signal( width ), name+eol ) }}
{%- endmacro %}
{%- macro get_port_name( b ) -%}
{%- if b.port_signal_input -%}
{{b.name_lowcase}}_i
{%- else -%}
{{b.name_lowcase}}_o
{%- endif -%}
{%- endmacro -%}
// Generated using CSR map generator
// https://github.com/johan92/csr-map-generator
module {{module_name}}(
{%- for p in data %}
// Register {{p.name}} signals
{%- for b in p.bits %}
{%- if b.port_signal_input %}
{{print_port_signal( "input", b.width, get_port_name( b ) )}}
{%- elif b.port_signal_output %}
{{print_port_signal( "output", b.width, get_port_name( b ) )}}
{%- endif %}
{%- endfor %}
{% endfor %}
// CSR interface
{{print_port_signal( "input", 1, "reg_clk_i" ) }}
{{print_port_signal( "input", 1, "reg_rst_i" ) }}
{{print_port_signal( "input", reg_d_w, "reg_wr_data_i" ) }}
{{print_port_signal( "input", 1, "reg_wr_en_i" ) }}
{{print_port_signal( "input", 1, "reg_rd_en_i" ) }}
{{print_port_signal( "input", reg_a_w, "reg_addr_i" ) }}
{{print_port_signal( "output", reg_d_w, "reg_rd_data_o", "" ) }}
);
{%- for p in data %}
// ******************************************
// Register {{p.name}}
// ******************************************
logic [{{reg_d_w-1}}:0] {{reg_name( p )}}_read;
{%- for b in p.bits %}
{%- if b.mode != "RO" %}
logic [{{b.width-1}}:0] {{reg_name_bits( p, b )}} = {{bit_init_value( b )}};
{%- endif %}
{%- endfor %}
{% for b in p.bits %}
{%- if b.port_signal_output %}
always_ff @( posedge reg_clk_i or posedge reg_rst_i )
if( reg_rst_i )
{{reg_name_bits( p, b )}} <= {{bit_init_value( b )}};
else
if( reg_wr_en_i && ( reg_addr_i == {{reg_a_w}}'h{{p.num}} ) )
{{reg_name_bits( p, b )}} <= reg_wr_data_i[{{b.bit_msb}}:{{b.bit_lsb}}];
{%-if b.mode == "RW_SC" %}
else
{{reg_name_bits( p, b )}} <= {{bit_init_value( b )}};
{% endif %}
{%- endif %}
{%- if b.mode == "RO_LH" or b.mode == "RO_LL" %}
always_ff @( posedge reg_clk_i or posedge reg_rst_i )
if( reg_rst_i )
{{reg_name_bits( p, b )}} <= {{bit_init_value( b )}};
else
begin
if( reg_rd_en_i && ( reg_addr_i == {{reg_a_w}}'h{{p.num}} ) )
{{reg_name_bits( p, b )}} <= {{bit_init_value( b )}};
{% if b.mode == "RO_LL" %}
if( {{get_port_name( b )}} == 1'b0 )
{{reg_name_bits( p, b )}} <= 1'b0;
{%- elif b.mode == "RO_LH" %}
if( {{get_port_name( b )}} == 1'b1 )
{{reg_name_bits( p, b )}} <= 1'b1;
{%- endif %}
end
{% endif %}
{% endfor %}
// assigning to output
{%- for b in p.bits %}
{%- if b.port_signal_output %}
assign {{get_port_name( b )}} = {{reg_name_bits( p, b )}};
{%- endif %}
{%- endfor %}
{%- macro print_in_always_comb( r, b, _right_value ) -%}
{%- if b == "" -%}
{{ " %s%-7s = %s;" | format( reg_name( r ) + "_read", "", _right_value ) }}
{%- else -%}
{{ " %s%-7s = %s;" | format( reg_name( r ) + "_read", "["+b.bit_msb|string+":"+b.bit_lsb|string+"]" , _right_value ) }}
{%- endif -%}
{%- endmacro %}
// assigning to read data
always_comb
begin
{{print_in_always_comb( p, "", reg_d_w|string+"'h0" ) }}
{%- for b in p.bits %}
{%- if b.mode == "RO" %}
{{print_in_always_comb( p, b, get_port_name( b ) )}}
{%- else %}
{{print_in_always_comb( p, b, reg_name_bits( p, b ) )}}
{%- endif %}
{%- endfor %}
end
{%- endfor %}
// ******************************************
// Reading stuff
// ******************************************
logic [{{reg_d_w-1}}:0] reg_rd_data = {{reg_d_w}}'h0;
always_ff @( posedge reg_clk_i or posedge reg_rst_i )
if( reg_rst_i )
reg_rd_data <= {{reg_d_w}}'h0;
else
if( reg_rd_en_i )
begin
case( reg_addr_i )
{% for p in data %}
{{reg_a_w}}'h{{p.num}}:
begin
reg_rd_data <= {{reg_name( p )}}_read;
end
{% endfor %}
default:
begin
reg_rd_data <= {{reg_d_w}}'h0;
end
endcase
end
assign reg_rd_data_o = reg_rd_data;
endmodule
""")
Дергаем генерацию шаблона:
res = csr_map_template.render(
module_name = MODULE_NAME,
reg_d_w = 32,
reg_a_w = 8,
data = reg_l
)
Получили вот такой модуль:
Скрытый текст
// Generated using CSR map generator
// https://github.com/johan92/csr-map-generator
module trafgen_map_4habr(
// Register MAIN signals
output [0:0] gen_en_o,
input [0:0] gen_error_i,
output [0:0] gen_reset_o,
// Register IP_DST signals
output [31:0] ip_dst_o,
// Register FRM_SIZE signals
output [15:0] frm_size_o,
// Register FRM_CNT signals
input [31:0] frm_cnt_i,
// CSR interface
input [0:0] reg_clk_i,
input [0:0] reg_rst_i,
input [31:0] reg_wr_data_i,
input [0:0] reg_wr_en_i,
input [0:0] reg_rd_en_i,
input [7:0] reg_addr_i,
output [31:0] reg_rd_data_o
);
// ******************************************
// Register MAIN
// ******************************************
logic [31:0] reg_0_main_read;
logic [7:0] reg_0_main___ip_core_version = 8'h7;
logic [0:0] reg_0_main___gen_en = 1'h0;
logic [0:0] reg_0_main___gen_error = 1'h0;
logic [0:0] reg_0_main___gen_reset = 1'h0;
always_ff @( posedge reg_clk_i or posedge reg_rst_i )
if( reg_rst_i )
reg_0_main___gen_en <= 1'h0;
else
if( reg_wr_en_i && ( reg_addr_i == 8'h0 ) )
reg_0_main___gen_en <= reg_wr_data_i[16:16];
always_ff @( posedge reg_clk_i or posedge reg_rst_i )
if( reg_rst_i )
reg_0_main___gen_error <= 1'h0;
else
begin
if( reg_rd_en_i && ( reg_addr_i == 8'h0 ) )
reg_0_main___gen_error <= 1'h0;
if( gen_error_i == 1'b1 )
reg_0_main___gen_error <= 1'b1;
end
always_ff @( posedge reg_clk_i or posedge reg_rst_i )
if( reg_rst_i )
reg_0_main___gen_reset <= 1'h0;
else
if( reg_wr_en_i && ( reg_addr_i == 8'h0 ) )
reg_0_main___gen_reset <= reg_wr_data_i[31:31];
else
reg_0_main___gen_reset <= 1'h0;
// assigning to output
assign gen_en_o = reg_0_main___gen_en;
assign gen_reset_o = reg_0_main___gen_reset;
// assigning to read data
always_comb
begin
reg_0_main_read = 32'h0;
reg_0_main_read[7:0] = reg_0_main___ip_core_version;
reg_0_main_read[16:16] = reg_0_main___gen_en;
reg_0_main_read[17:17] = reg_0_main___gen_error;
reg_0_main_read[31:31] = reg_0_main___gen_reset;
end
// ******************************************
// Register IP_DST
// ******************************************
logic [31:0] reg_1_ip_dst_read;
logic [31:0] reg_1_ip_dst___ip_dst = 32'hB2F8E921;
always_ff @( posedge reg_clk_i or posedge reg_rst_i )
if( reg_rst_i )
reg_1_ip_dst___ip_dst <= 32'hB2F8E921;
else
if( reg_wr_en_i && ( reg_addr_i == 8'h1 ) )
reg_1_ip_dst___ip_dst <= reg_wr_data_i[31:0];
// assigning to output
assign ip_dst_o = reg_1_ip_dst___ip_dst;
// assigning to read data
always_comb
begin
reg_1_ip_dst_read = 32'h0;
reg_1_ip_dst_read[31:0] = reg_1_ip_dst___ip_dst;
end
// ******************************************
// Register FRM_SIZE
// ******************************************
logic [31:0] reg_2_frm_size_read;
logic [15:0] reg_2_frm_size___frm_size = 16'h40;
always_ff @( posedge reg_clk_i or posedge reg_rst_i )
if( reg_rst_i )
reg_2_frm_size___frm_size <= 16'h40;
else
if( reg_wr_en_i && ( reg_addr_i == 8'h2 ) )
reg_2_frm_size___frm_size <= reg_wr_data_i[15:0];
// assigning to output
assign frm_size_o = reg_2_frm_size___frm_size;
// assigning to read data
always_comb
begin
reg_2_frm_size_read = 32'h0;
reg_2_frm_size_read[15:0] = reg_2_frm_size___frm_size;
end
// ******************************************
// Register FRM_CNT
// ******************************************
logic [31:0] reg_3_frm_cnt_read;
// assigning to output
// assigning to read data
always_comb
begin
reg_3_frm_cnt_read = 32'h0;
reg_3_frm_cnt_read[31:0] = frm_cnt_i;
end
// ******************************************
// Reading stuff
// ******************************************
logic [31:0] reg_rd_data = 32'h0;
always_ff @( posedge reg_clk_i or posedge reg_rst_i )
if( reg_rst_i )
reg_rd_data <= 32'h0;
else
if( reg_rd_en_i )
begin
case( reg_addr_i )
8'h0:
begin
reg_rd_data <= reg_0_main_read;
end
8'h1:
begin
reg_rd_data <= reg_1_ip_dst_read;
end
8'h2:
begin
reg_rd_data <= reg_2_frm_size_read;
end
8'h3:
begin
reg_rd_data <= reg_3_frm_cnt_read;
end
default:
begin
reg_rd_data <= 32'h0;
end
endcase
end
assign reg_rd_data_o = reg_rd_data;
endmodule
Как видим идея сработала: из простого текстового описания появился полноценный модуль, который не надо допиливать руками — можно сразу брать в продакшен)
В качестве интерфейса управления использовалось подобие Avalon-MM.
Подведение итогов
С Jinja2 я познакомился буквально пару дней назад, когда смотрел на гитхабе реализацию 1G и 10G MAC-ядер вместе с UDP/IP стеком. Кстати, написано неплохо, но я смотрел довольно-таки поверхностно и в симуляции, а тем более на железе не пробовал.
Автор использует Jinja2 для генерации различных модулей, например, N-портового мультиплексора AXI4-Stream. Этот мультиплексор намного хитрее, чем тот, который я писал в начале статьи.
Скрипт для генерации csr_map я накидал на скорую руку, чтобы прочувствовать возможности Jinja2 (уверен, оценил я её малую часть), но могу рекомендовать всем коллегам, которые занимаются разработкой под FPGA поиграться с этой библиотекой, возможно, вы сможете ускорить свою разработку за счёт автогенерации кода.
Конечно, этот скрипт сырой, и мы его еще не использовали в разработке (и я даже не знаю, будем использовать или нет, т.к. по различным причинам красивая архитектура IP-ядер иногда остается просто красивой архитектурой).
Выложил полностью исходник на гитхаб. Если этот шаблон кому-то пригодится, буду рад: готов по запросам его улучшить, либо принять чьи-то pull-request'ы)
Спасибо за внимание! Если появились вопросы, задавайте без сомнений.
Скрытый текст
Жаль, конечно, что хаб FPGA перенесли на гиктаймс.
