В предыдущей статье мы познакомились с терминологией и основными идеями, лежащими в основе сборщиков мусора Java HotSpot VM и многих других виртуальных машин. Теперь мы, наконец, можем взять в руки лопату и приступить к разгребанию нашей кучи. Сегодня у нас на обзоре
Используемые в этих сборщиках подходы к работе с кучей в том или ином виде применяются в более продвинутых реализациях, поэтому на данном этапе нам будет очень важно разобраться с заложенными в них идеями и возможностями.
Serial GC
Serial GC (он же последовательный сборщик) — младший с точки зрения заложенной в него функциональности, но старший с точки зрения продолжительности присутствия в JVM сборщик мусора. Он медленно, но верно собирал мусор еще тогда, когда многие из нас даже не подозревали о существовании языка Java. И до сих пор продолжает собирать. Так же медленно, но так же верно.
А не отправился на задворки истории он потому, что не у всех программ большие кучи и не все программы работают на компьютерах с мощными многоядерными процессорами. В таких спартанских условиях он оказывается весьма кстати. И даже если это не ваш случай, не стоит пропускать данную главу, так как базовые подходы к реализации сборки мусора в JVM описаны именно здесь, так что давайте приступим.
Использование Serial GC включается опцией
-XX:+UseSerialGC.Принципы работы
При использовании данного сборщика куча разбивается на четыре региона, три из которых относятся к младшему поколению (Eden, Survivor 0 и Survivor 1), а один (Tenured) — к старшему:

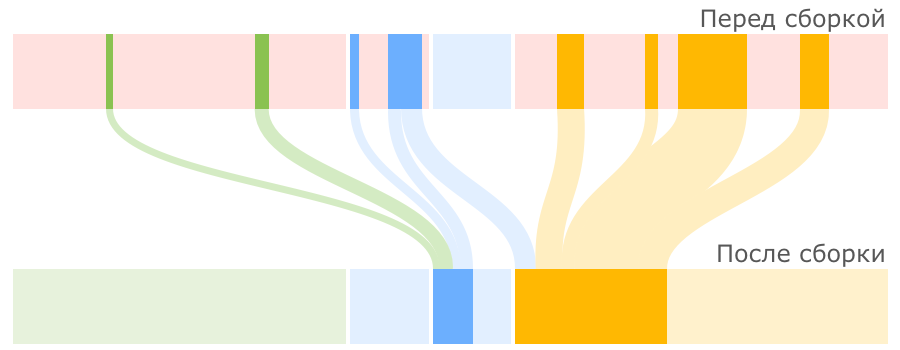
Среднестатистический объект начинает свою жизнь в регионе Eden (переводится как Эдем, что вполне логично). Именно сюда его помещает JVM в момент создания. Но со временем может оказаться так, что места для вновь создаваемого объекта в Eden нет, в таких случаях запускается малая сборка мусора.
Первым делом такая сборка находит и удаляет мертвые объекты из Eden. Оставшиеся живые объекты переносятся в пустой регион Survivor. Один из двух регионов Survivor всегда пустой, именно он выбирается для переноса объектов из Eden:
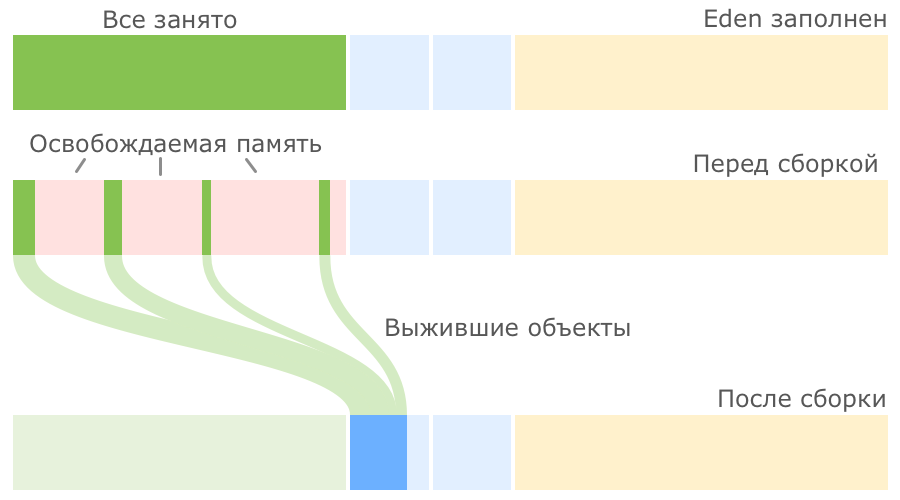
Мы видим, что после малой сборки регион Eden полностью опорожнен и может быть использован для размещения новых объектов. Но рано или поздно наше приложение опять займет всю область Eden и JVM снова попытается провести малую сборку, на этот раз очищая Eden и частично занятый Survivor 0, после чего перенося все выжившие объекты в пустой регион Survivor 1:

В следующий раз в качестве региона назначения опять будет выбран Survivor 0. Пока места в регионах Survivor достаточно, все идет хорошо:
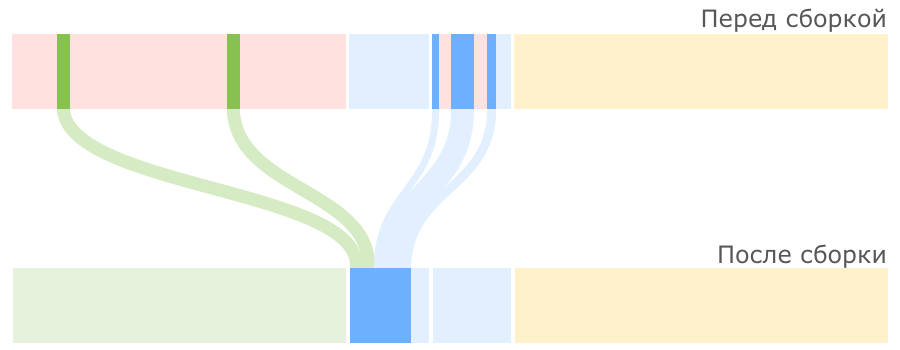
JVM постоянно следит за тем, как долго объекты перемещаются между Survivor 0 и Survivor 1, и выбирает подходящий порог для количества таких перемещений, после которого объекты перемещаются в Tenured, то есть переходят в старшее поколение. Если регион Survivor оказывается заполненным, то объекты из него также отправляются в Tenured:
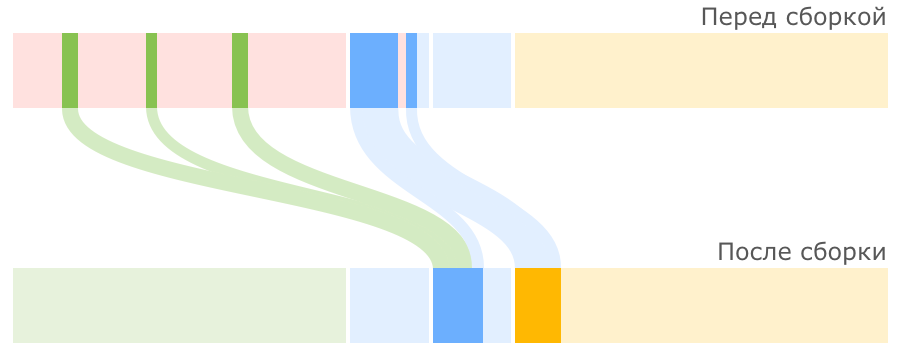
Описанный процесс малой сборки мусора достаточно прост, но причины использования регионов Survivor, причем именно двух, не всегда понятны. Я думаю, детальное объяснение причин мы оставим за рамками данной статьи (разобрали в комментариях), а здесь лишь отметим, что из двух основных способов работы с выжившими объектами — уплотнение и копирование — в Sun при разработке малого сборщика мусора пошли по второму пути, так как он проще в реализации и зачастую оказывается производительнее.
В случае, когда места для новых объектов не хватает уже в Tenured, в дело вступает полная сборка мусора, работающая с объектами из обоих поколений. При этом старшее поколение не делится на подрегионы по аналогии с младшим, а представляет собой один большой кусок памяти, поэтому после удаления мертвых объектов из Tenured производится не перенос данных (переносить уже некуда), а их уплотнение, то есть размещение последовательно, без фрагментации. Такой механизм очистки называется Mark-Sweep-Compact по названию его шагов (пометить выжившие объекты, очистить память от мертвых объектов, уплотнить выжившие объекты).
Акселераты
Самые наблюдательные читатели наверняка заметили, что в начале описания принципов работы говорится о том, что в разделе Eden создается среднестатистический объект, а не любой. Такая оговорка сделана неспроста. Дело в том, что бывают еще объекты-акселераты, размер которых настолько велик, что создавать их в Eden, а потом таскать за собой по Survivor’ам слишком накладно. В этом случае они размещаются сразу в Tenured.
Куча мала?
Важными факторами в описанных процессах являются абсолютный размер кучи и относительные размеры регионов внутри нее.
По мере заполнения кучи данными JVM может не только проводить чистку памяти, но и запрашивать у ОС выделение дополнительной памяти для расширения регионов. Причем в случае, если реально используемый объем памяти падает ниже определенного порога, JVM может вернуть часть памяти операционной системе. Для регулирования аппетита виртуальной машины существуют известные всем опции
Xms и Xmx.И хотя установки граничных значений кучи иногда достаточно, чтобы программа работала и слишком уж явно не тормозила, более тонкая настройка сборщика для достижения требуемой производительности выполняется регулированием размеров различных регионов. Мы рассмотрим примеры такого регулирования и его влияния на работу программы в отдельной статье, а здесь пока просто перечислим параметры, с помощью которых это делается (см. ниже).
Тут также стоит отметить, что по умолчанию младшее поколение занимает одну треть всей кучи, а старшее, соответственно, две трети. При этом каждый регион Survivor занимает одну десятую младшего поколения, то есть Eden занимает восемь десятых. В итоге реальные пропорции регионов по умолчанию выглядят так:

А что же происходит, если даже после выделения максимального объема памяти и ее полной чистки, места для новых объектов так и не находится? В этом случае мы ожидаемо получаем java.lang.OutOfMemoryError: Java heap space и приложение прекращает работу, оставляя нам на память свою кучу в виде файла для анализа. Технически, это происходит в случае, если работа сборщика начинает занимать не менее 98% времени и при этом сборки мусора освобождают не более 2% памяти.
Ситуации STW
С этим сборщиком все достаточно просто, так как вся его работа — это один сплошной STW. В начале каждой сборки мусора работа основных потоков приложения останавливается и возобновляется только после окончания сборки. Причем всю работу по очистке Serial GC выполняет не торопясь, в одном потоке, последовательно, за что и удостоился своего имени.
Настройка
Мы уже коснулись того, что с помощью опций
Xms и Xmx можно настроить начальный и максимально допустимый размер кучи соответственно. Наверняка большинство из вас это уже делали. Теперь давайте попробуем копнуть поглубже.Существуют опции
-XX:MinHeapFreeRatio=? -XX:MaxHeapFreeRatio=? MinHeapFreeRatio=35 MaxHeapFreeRatio=65 Установить желаемое отношение размера старшего поколения к суммарному размеру регионов младшего поколения можно с помощью опции
-XX:NewRatio=? NewRatio=3 При желании можно ограничить размер младшего поколения абсолютными величинами снизу и сверху с помощью опций
-XX:NewSize=? -XX:MaxNewSize=? NewSize и MaxNewSize одинаковые значения, то можно просто использовать опцию -Xmn -Xmn256m -XX:NewSize=256m -XX:MaxNewSize=256m Можно еще залезть внутрь младшего поколения и настроить отношение размера Eden к размерам Survivor. Это делается с помощью опции
-XX:SurvivorRatio=? SurvivorRatio=6 C помощью опции
-XX:-UseGCOverheadLimit Если вам интересно последить за тем, как стареют ваши объекты в регионе Survivor и какие целевые значения для его размера установлены в данный момент, можно использовать опцию
-XX:+PrintTenuringDistribution Достоинства и недостатки
Основное достоинство данного сборщика очевидно — это непритязательность по части ресурсов компьютера. Так как всю работу он выполняет последовательно в одном потоке, никаких заметных оверхедов и негативных побочных эффектов у него нет.
 Главный недостаток тоже понятен — это долгие паузы на сборку мусора при заметных объемах данных. Кроме того, видно, что все настройки Serial GC крутятся вокруг размеров различных регионов кучи. То есть для тонкой настройки требуется самому что-то изучать, настраивать, экспериментировать и прочее. Кому-то это может прийтись не по душе.
Главный недостаток тоже понятен — это долгие паузы на сборку мусора при заметных объемах данных. Кроме того, видно, что все настройки Serial GC крутятся вокруг размеров различных регионов кучи. То есть для тонкой настройки требуется самому что-то изучать, настраивать, экспериментировать и прочее. Кому-то это может прийтись не по душе.Если вашему приложению не требуется большой размер кучи для работы (Oracle указывает условную границу
Parallel GC
Parallel GC (параллельный сборщик) развивает идеи, заложенные последовательным сборщиком, добавляя в них параллелизм и немного интеллекта. Если на вашем компьютере больше одного процессорного ядра и вы явно не указали, какой сборщик хотите использовать в своей программе, то почти наверняка JVM остановит свой выбор на Parallel GC. Он достаточно простой, но в то же время достаточно функциональный, чтобы удовлетворить потребности большинства приложений.
Параллельный сборщик включается опцией
-XX:+UseParallelGC Принципы работы
При подключении параллельного сборщика используются те же самые подходы к организации кучи, что и в случае с Serial GC — она делится на такие же регионы Eden, Survivor 0, Survivor 1 и Old Gen (знакомый нам под именем Tenured), функционирующие по тому же принципу. Но есть два принципиальных отличия в работе с этими регионами: во-первых, сборкой мусора занимаются несколько потоков параллельно; во-вторых, данный сборщик может самостоятельно подстраиваться под требуемые параметры производительности. Давайте разберемся, как это устроено.
Для определения количества потоков, которые будут использоваться при сборке мусора, на компьютере с N ядрами процессора, JVM по умолчанию применяет следующую формулу: если
По умолчанию и малая и полная сборка задействуют многопоточность. Малая пользуется ею при переносе объектов в старшее поколение, а полная — при уплотнении данных в старшем поколении.
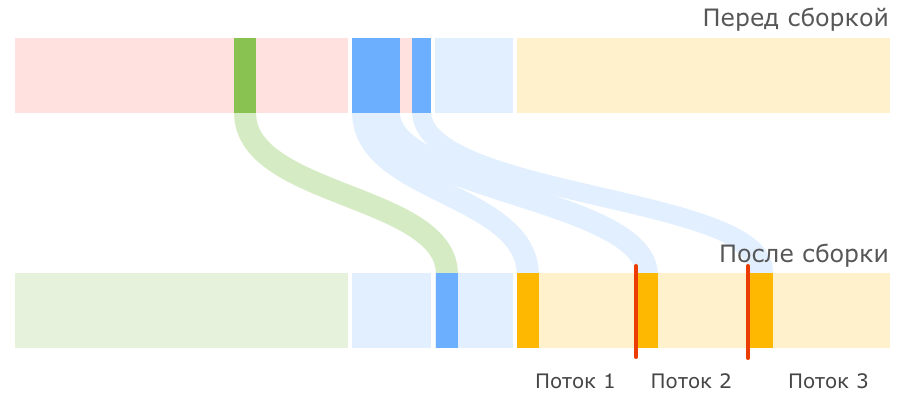
Каждый поток сборщика получает свой участок памяти в регионе Old Gen, так называемый буфер повышения (promotion buffer), куда только он может переносить данные, чтобы не мешать другим потокам. Такой подход ускоряет сборку мусора, но имеет и небольшое негативное последствие в виде возможной фрагментации памяти:
Интеллектуальная составляющая улучшений параллельного сборщика относительно последовательного заключается в том, что у него есть настройки, ориентированные на достижение необходимой вам эффективности сборки мусора. Вы можете указать устраивающие вас параметры производительности — максимальное время сборки и/или пропускную способность — и сборщик будет изо всех сил стараться не превышать заданные пороги. Для этого он будет использовать статистику уже прошедших сборок мусора и исходя из нее планировать параметры дальнейших сборок: варьировать размеры поколений, менять пропорции регионов.
Например, если при малой сборке JVM не удается укладываться в отведенное вами время, размер младшего поколения может быть уменьшен. Если не удается достигнуть заданной пропускной способности, а с задержкой проблем нет, то размер поколения будет увеличен. И так далее.
При этом следует иметь в виду, что в статистике игнорируются сборки мусора, запущенные вами вручную.
Конечно, стопроцентной гарантии достижения желаемых параметров вам никто не даст, но попробовать можно, часто установки нужных опций оказывается достаточно.
В случае, если вы задали слишком жесткие требования, которые сборщик не может выполнить, он будет ориентироваться на следующие приоритеты (в порядке убывания важности):
- Снижение максимальной паузы.
- Повышение пропускной способности.
- Минимизация используемой памяти.
При этом Parallel GC оставляет нам возможность самостоятельно корректировать размеры регионов, как и в последовательном сборщике. Но не рекомендуется делать и то и другое одновременно, чтобы не дезориентировать алгоритмы автоматической подстройки. Либо мы выделяем приложению достаточно памяти, указываем желаемые параметры производительности и наблюдаем со стороны, либо сами залезаем в настройки регионов, но тогда лишаемся права требовать от сборщика автоматической подстройки под нужные нам критерии производительности. Ругаться он на нас в случае нарушения данного правила не будет, но и эффективно выполнять свою работу тоже не сможет.
Ситуации STW
Как и в случае с последовательным сборщиком, на время операций по очистке памяти все основные потоки приложения останавливаются. Разница только в том, что пауза, как правило, короче за счет выполнения части работ в параллельном режиме.
Настройка
Для параллельного сборщика применимы все те же опции, что и для последовательного. Вы можете вручную устанавливать размеры регионов памяти или пропорции между ними. Ниже перечислены те опции, которые добавляются параллельным сборщиком к тому, что мы уже рассматривали выше.
Вы можете вручную указать количество потоков, которое хотели бы выделить для сборки мусора. Это делается с помощью опции
-XX:ParallelGCThreads=? -XX:ParallelGCThreads=9 При желании вы можете полностью отключить параллельные работы по уплотнению объектов в старшем поколении опцией
-XX:-UseParallelOldGC Установка желаемых параметров производительности сборщика выполняется с помощью опций
-XX:MaxGCPauseMillis=? -XX:GCTimeRatio=? MaxGCPauseMillis -XX:MaxGCPauseMillis=400 С помощью опции
GCTimeRatio -XX:GCTimeRatio=49 Опции
-XX:YoungGenerationSizeIncrement=? -XX:TenuredGenerationSizeIncrement=? А вот скорость уменьшения размеров поколений регулируется не процентами, а специальным фактором через опцию
-XX:AdaptiveSizeDecrementScaleFactor -XX:AdaptiveSizeDecrementScaleFactor=2 -XX:GenerationSizeIncrement=20 -XX:TenuredGenerationSizeIncrement=20 Достоинства и недостатки
Бесспорным плюсом данного сборщика на фоне Serial GC является возможность автоматической подстройки под требуемые параметры производительности и меньшие паузы на время cборок. При наличии нескольких процессорных ядер выигрыш в скорости будет практически во всех приложениях.
Определенная фрагментация памяти, конечно, является минусом, но вряд ли она будет существенной для большинства приложений, так как сборщиком используется относительно небольшое количество потоков.
В целом, Parallel GC — это простой, понятный и эффективный сборщик, подходящий для большинства приложений. У него нет скрытых накладных расходов, мы всегда можем поменять его настройки и ясно увидеть результат этих изменений.
Но бывает так, что его оказывается недостаточно и нужно искать что-то более изощренное. О более продвинутых реализациях сборщиков мы поговорим уже в следующей статье.
Часть 3 — Сборщики CMS GC и G1 GC →
Часть 4 — Сборщик ZGC →
Часть 5 — Сборщик Epsilon GC →
Часть 6 — Сборщик Shenandoah GC →
Ранее
← Часть 1 — Введение
