Comments 42
(((x*x)**0.106)**2))
Кажется стоит допилить сокращения таких штук.
Как происходит мутация формул? Она затрагивает один из токенов, содержащихся в формуле, и может пойти тремя путями:
А что если в качестве ещё одного вида мутации константам добавить округление (на рандомное количество знаков)? Кажется это может ускорить сходимость.
Как выбрать из двух претендентов, если они одинаково не отсортировали массив
Если претенденты вообще не трогали массив — выбирать случайного. Если тронули, то это уже лучше чем вообще ничего не делали с массивом. Из двух претендентов, которые что-то изменили в массиве — выбирать того кто привёл его к более сортированному виду чем он был раньше (ввести метрику отсортированности — например, количество элементов в верном порядке, стоящих рядом).
итоги первого эксперимента заставили меня сильно усомниться в шансах на успех с сортировками
Мне кажется что-то вроде bogosort вполне может получится.
Кажется стоит допилить сокращения таких штук
Вообще операция возведения в степень неожиданно много проблем вызвала. Я даже задумывался о том, включать ли её вообще. Отчасти поэтому, когда работал над сокращениями, не учел работу с ней
А что если в качестве ещё одного вида мутации константам добавить округление
Это и происходит в случае shift: константа может поменять свой тип с Float на Int, и, таким образом, отбросить дробную часть.
Касательно сортировок. Да, согласен, оценка степени сортированности массива это первый из наиболее напрашивающихся критериев успеха. Но, повторюсь, неверные шаги сортировок искажают их до неузнаваемости. Тут можно провести аналогию с хеш-функцией, где решение это исходная строка, а результат оценивается по её хешу. Один символ в строке поменялся — хеш радикально преобразился.
В задачах символьной регрессии удобнее представлять геном в виде дерева, например так — images.myshared.ru/10/988544/slide_3.jpg
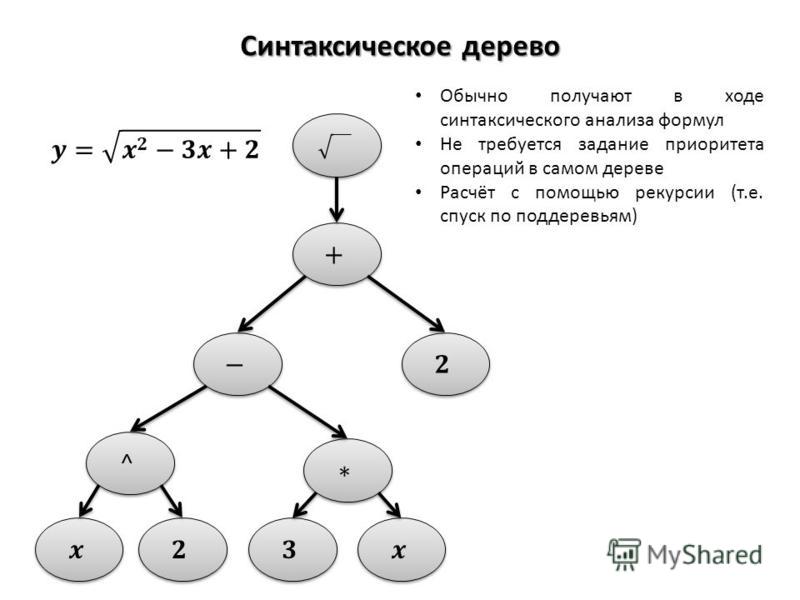{kind=link}
А для сокращения(упрошения выражений) использовать математические пакеты типо матлаба (они сделают все как надо).
Замечательная работа по теме — «distilling free-form natural laws from experimental data». Ребята вывели законы механики с помощью генетических вычислений.
И вот тут предприняты попытки сделать более интелектуальные упрощения, чтобы на корню не губить потенциальные решения — github.com/air-labs/CA
Ваша картинка:

Геном в первом эксперименте и представлен в виде дерева, например:
xp2 = Formula::PowerOperator.new(Formula::Variable.new(:x), Formula::IntConstant.new(2)) # (x**2)
xm3 = Formula::MultiplicationOperator.new(Formula::IntConstant.new(3), Formula::Variable.new(:x)) # (3*x)
xp_xm = Formula::SubtractionOperator.new(xp2, xm3) # ((x**2)-(3*x))
xpx = Formula::AdditionOperator.new(xp_xm, Formula::IntConstant.new(2)) # (((x**2)-(3*x))+2)
f = Formula::PowerOperator.new(xpx, Formula::FloatConstant.new(0.5)) # ((((x**2)-(3*x))+2)**0.500)Да, возможно имело смысл обратиться к готовым решениям по сокращениям.
Спасибо за наводки, ознакомлюсь.
ГА слабы в большинстве задач, это да
И почему важно чтобы " функция приспособленности набора генов с изменением каждого гена менялась бы «вероятно незначительно»"?
2) Так работает натуральная эволюция.
2) Разве из этого вытекает, что подобное правило справедливо для ГА?
Ну и если у меня есть гладкая ф-ия потерь (которая меняется незначительно от вариации аргумента), разве не проще использовать градиентные методы первого/второго порядка, которые имеют намного лучшую сходимость по сравнению с ГА?
Вот тут ребята применили ГА к маршрутизации в TCP: https://www.opennet.ru/opennews/art.shtml?num=37482. Многие торговые роботы, торгующие на биржах, для оптимизации рисков тоже используют ГА.
За пример спасибо — первый раз вижу чтобы ГА применяли к чему-то более-менее полезному (правда компетенции чтобы оценить качество решения у меня нету =( )
На счет того, что ГА единственный вариант для случаев когда мы не можем нормально анализировать целевую ф-ию — не согласен.
Есть же целая куча derivative free оптимизаций — всякие Particle swarm optimization, CMA-ES, etc
В логистике. Ни задача нахождения кратчайшего (читай эффективного, с учетом метрик — пропускная, тоннаж, габариты, разрешения для опасных грузов) пути ни задача упаковки грузов (просто максимальной утилизации контейнера, даже без учета требований такелажа к каждой коробке) не решены. NP-трудные задачи. И решают их в основном генетическими алгоритмами, нейросетки почему то не в ходу, подозреваю что из-за трудности с обучением.
Применение Генетического Алгоритма для упаковки 2D обьектов: https://github.com/Jack000/SVGnest
Вы, как человек, уже прочитавший серьезную литературу, не могли бы чуть более развернуто аргументировать свою позицию и привести доводы из указанного источника?
Теперь давайте посмотрим на суть этой статьи. К предметной области А решили применить метод из совершенно далекой предметной области В. Ну как минимум хотелось бы аргументации — а с чего ради гвозди забивать подушкой? Аргументация в подобных статьях одна — ну Дарвин же, природа, ГА — это круто… И дальше поток терминов, эвристик… Чтобы забивать подушкой гвоздь — нужна сильная аргументация. Если бы автор потратил столько же времени на аргументацию — был бы как минимум предметный разговор. А так — еще один эвристический бесполезный алгоритм.
«это всего лишь алгоритм оптимизации» — так под оптимизацию любую задачу можно подогнать. Что вы и проделали. Только аргументация нулевая. Почему среди кучи методов оптимизации вы решили ГА попробовать? Вообще какой смысл применять «подушку» к забиванию гвоздей когда рядом молоток лежит?
Может быть, оставите свои контакты, чтобы я отправлял к вам всех, кто ещё так же как и я блуждает в неведении? У вас очень убедительная риторика.
в том числе новомодные вроде нейросетей
Но ведь ИНС уже более 50 лет, и они многократно доказывали свою эффективность. Практически всё современные реализации распознавания образов работают на ИНС, и позволяют решать задачи, которые нам и не снились раньше.
В комментариях выше есть замечательные примеры практического применения концепции ГА.
Никто не говорит о данных методах как о панацее, "серебрянной пуле" и т.п. Но они реально небесполезны, и это факт. Непонятно, почему находятся те, кто с этим по-прежнему спорит.
Что касается примера, использованного в статье — что поделать, на прорыв в кибернетике он не тянет :) С другой стороны, на простом примере, "на пальцах", легче доносить мысли и что-то объяснять.
Про полезность попыток применения ГА — не спорю, пробовать надо. Но делать такие эксперименты надо чистыми. Выбирать предметную область максимально ближе к явлениям в ГА…
Точно! Вот о чем я забыл! Ещё в прошлом году, когда идея с генетическими алгоритмами была только в голове, в одном из экспериментов я планировал заново "изобрести" алгоритм быстого InvSqrt Кармака из Quake. Потом я, уже не помню почему, остановился на варианте с сортировками. А ведь InvSqrt действительно кажется более подходящей задачей для ГА.
Заметил в Вашем примере родословной, что нектороые синтксически разные деревья, на самом деле семантически одинаковы:
(((x-0)**2)/1)
((((x-0)**2)-0)/1)
(((x-0)**2)-0)
(((x-0)**2)-0.000)Некоторое время тому я тоже интересовался данной тематикой.
Чтобы уменьшить количество семантически одинаковых деревьев, я разбивал каждую итерацию Генетического Алгоритма на два этапа:
1) операции над синтаксическими деревьями (скрещивание и мутации)
2) оптимизация числовых коэффициентов каждого синтаксическогг дерева (опять же с использованием Генетического Алгоритма)
Дополнительная оптимизация: в случае, если поддерево не содержит переменных — оно заменяется на лист с единственным числовым значением.
Этот подход позволяет увеличить разнообразие синтаксических деревьев, которые различаются семантически.
Более подробоное описание можно найти в моём посте: https://habrahabr.ru/post/163195/ (правда у меня весь код реализован на Java, и в посте можно найти ссылку на GitHub)
Между ними всё же есть разница, на уровне генотипа, хоть и результат они выдают одинаковый. Я решил определять идентичность основываясь только на генотипе, иначе решения типа:
(x - x)
(0 / x)признавались бы дубликатами. Хотя разность между их генотипами достаточно существенна, и разбегание результатов с большой долей вероятности наступит уже в следующем поколении.
Операция оптимизации в моём случае называется сокращением, и вынесена как один из вариантов мутации, по тем же соображениям:
((4 - 2) * 3)
6Первое дерево может прийти ко второму за одну мутацию типа shift, применённую к операции верхнего уровня (умножению). Однако, пока это разные деревья, и у них, соответственно, разные возможные пути мутации.
Как в таких условиях адекватно оценить, насколько хорошо претендент прошел испытание? У меня нет ответа. Как выбрать из двух претендентов, если они одинаково не отсортировали массив, но за разное количество выполненных команд?
Можно не пытаться скармливать сразу большой массив и как-то анализировать пригодность результата. Эволюция же работает с малыми изменениями окружающей среды, при радикальных изменениях она терпит крах (массовые вымирания видов).
Предлагаю выращивать популяцию, способную сортировать короткие массивы, начиная например с 3 элементов.
Имея такую популяцию уже можно вносить изменения в окружение — увеличить размер массива на один элемент.
Те, кто справился, — проходят без изменений. Остальные мутируют/скрещиваются, пытаются адаптироваться.
Увеличение длины массива можно рассматривать как распространение вида на новые территории. Более универсальный вид захватит максимально возможную территорию (как это сделал, к примеру, человек).
Конечно, никто вам не запрещает реализовывать ГА так, как вам захочется, и я не возражал вашей интерпретации, а лишь дополнил деталями.
Генетическое программирование («Yet Another Велосипед» Edition)