Готовился к очередному хакатону, решил обновить свои знания в области компьютерного зрения. В прошлый раз задачу распознавания номеров авто в видеопотоке я так и не смог решить быстро «в лоб». Сейчас, поразмыслив, решил немного упростить задачу. Было много идей, листал фотки в телефоне и наткнулся на привычный кейс для всех, кто бывал в магазине ikea — фотографию с чеком, где указан номер товара и его положение на складе самообслуживания.

Кейс, конечно, с натяжкой. Имея фотки чеков в телефоне совсем не обязательно, чтобы телефон их распознавал, по фотке и так прекрасно видно, где и что тебе надо достать. С другой стороны, нам интересен пример работы такого софта + мы можем упростить себе жизнь, разместив весь нужный нам товар на карте склада. Т.е. имея 4-5 фото чеков, мы можем распознать их и построить карту маршрута беготни по складу самообслуживания. Отлично, одну причину для реализации нашей задумки придумали. Вторая причина — цвета. Лично я не раз сталкивался с тем, что ты фоткаешь чек, например, чёрного комода, не обращая внимания на то, что рядом стоит белый, который тебе и нужен, чей чек ты и хотел сфоткать. При распознании чека мы можем сразу показывать превью пользователю того товара, что на чеке (а значит и на месте на складе самообслуживания). Отлично, вторая причина, притянутая за уши, найдена.
Итого, что нам необходимо сделать?
Определяем инструментарий. Работать с изображением будем с помощью OpenCV
OpenCV Tesseract
Tesseract NodeJS
NodeJS
Выбор OpenCV очевиден. Даже профи, способные переписать большинство алгоритмов обработки изображения руками, чаще всего пользуются именно OpenCV. Не даром эта библиотека расшифровывается как «Open Source Computer Vision Library». Хотя чисто в теории можно придумать решение наших кейсов на gd+imagick. Но это извращение.
OpenCV будет отвечать за поиск чека на камере + за подготовку чека к распознаванию.
В своё время я использовал Tesseract для распознавания капчи яндекса, рамблера, гугла. Нет сомнений, что данная библиотека легко справится с распознаванием обычного текста. Ну и если честно, будучи «профаном» в ocr, я просто не знаю ничего другого настолько мощного с открытым кодом.
NodeJS исключительно личный выбор. В данный момент я делаю много всего на JS и данный язык просто ближе чисто синтаксиально, если такое слово вообще есть.
Я не претендую на быстроту и качество алгоритмов и тем более на чистый код, задачей для меня было исключительно быстро вспомнить компьютерное зрение, обновить свои знания и реализовать какой-либо проект. Поэтому любые правки и критика только приветствуются, но, пожалуйста, без истерии. Ну и повторю, я делюсь практикой для таких же «старикашек» как я сам, дабы не быть полным лохом среди тусовки молодых прогеров (где мои 17 лет…).
Погнали. Я создал репу на гитхабе, весь код, собственно, там. Разберёмся чуть подробней. В репе в /public/images/ вы найдёте 4 фотки икеевских чеков. Так вышло, что у меня оказались фотки под разными углами, разных размеров. То, что нужно для тестов.
репу на гитхабе, весь код, собственно, там. Разберёмся чуть подробней. В репе в /public/images/ вы найдёте 4 фотки икеевских чеков. Так вышло, что у меня оказались фотки под разными углами, разных размеров. То, что нужно для тестов.
Библиотека OpenCV очень мощная и далеко не ограничивается теми возможностями, о которых я расскажу в данной статье. Вначале я не даром оговорился, что нашу задачу могут решить GD+IMagick. В частности, профи скорее всего для обнаружения чека применили бы технику Template Matching, но мы пойдём более простым путём. Благо, ikea нам в этом сильно помогает.
Первое, что нам надо знать, чек с инфой о местонахождении товара всегда красный. Отлично, от этого и будем отталкиваться.
Конвертируем наше изображение (которое в данном случае прочитано в переменную process) в HSV и ищем изображение между заданными каналами. Я слабо себе представляю как это работает, но в поисках возможности выделить из изображения конкретный цвет и его гамму наткнулся на два материала, статью разработчика и официальную документацию. Из кода видно, что я использую матрицу между [0,100,100] и [10,255,255] в палитре HSV. Из официальной документации на тему выделения цвета следует, что общее правило очень простое. Мы берём [h-10, 100, 100] и [h+10, 255,255], где h — нужный нам цвет. Я использовал сервис colorizer.org для получения индексов.
Посмотрим, что получилось.

Отлично, мы вычленили красный и его оттенки. Итого нашли чек, мою руку и красный квадрат на принте ковра. Теперь с помощью метода findContour мы легко можем отделить «мух от котлет», т.е. найти «границы» в нашем изображении.

Обращаю внимание на строки
С помощью метода approxPolyDP мы «сглаживаем углы» найденных контуров, устраняя «шум». Подробнее можно прочитать на страницах официальной документации.
Так же стоит отметить, что findContour отлично справляется со своей задачей, но порядок найденных точек может быть непредсказуемым. Нам же важно сохранить порядок точек в формате top-left, top-right, bottom-right, bottom-left для правильной перспективы.

Казалось бы, задача простая, найти top-left точку итп. На практике это обернулось в кучу форов по массивам. Начал гуглить, наткнулся на отличный блог по компьютерному зрению и opencv, в том числе разработчик предложил хитрость для поиска этих самых «экстремумов» для нужных нам позиций. В частности минимальная сумма x+y координат будет всегда равна top-left точке, тогда как максимальная сумма будет равна bottom-right. Аналогично максимальная разносить x-y будет равна точке top-right и минимальная будет равен точке bottom-left. Получаем метод pointOrder
Очередность нам нужна для перкспективы. Мы заранее знаем точки горизонтали и вертикали (это 0/0, maxWidth/0, maxWidth/maxHeight и 0/maxHeight) и чтобы не перевернуть изображение, нам надо передавать точки нашего контура именно в этом порядке.
Подготовили контуры, следующим шагом выравниваем перспективу.

Находим 2 контура, как видно из изображения. Один нужный нам, второй «шумный».
Первым делом исключаем «левые» контуры от противного, т.е. сразу идентифицируем чек. А что мы знаем про чек? Верно, он прямоугольной формы, в нём текст и 3 прямоугольника с данными. От них и будем отталкиваться. Уже в найденных изображениях по аналогии ищем контуры, однако в этот раз мы выделяем только те найденные области, в которых есть 3 прямоугольных контура.
Ох, ну в общем я предупреждал, что задача была БЫСТРО рассмотреть пример, с дублированием кода я особо не заморачивался. Да и не люблю этим заниматься, когда проект не готовится на про. Да и если уж быть откровенным, для многих продакшен проектов во некоторых местах я оставляю дублирование кода, чтобы новичкам было проще его читать. Обращаем внимание, что контуры могут быть найдены в рандомном порядке, нам же важно знать их порядок, где артикул товара, где ряд, а где место.

На выходе мы нашли чек ikea, убедились, что это он + вычленили данные для распознавания.
Для того, чтобы упростить tesseract жизнь, обрежем наши изображения, вычленим красный (дабы сделать изображение чб) и увеличим. Увеличение немного замедляет tesseract, но на порядок увеличивает % распознавания.
Получаем в консоли
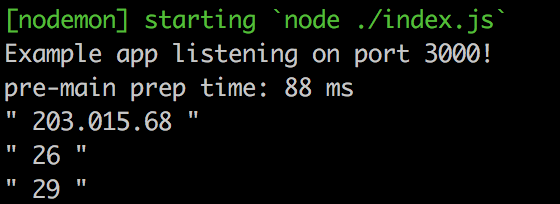
Вполне не плохо.
В следующих частях мы перенесём код на мобильные платформы и сделаем мобильную кроссплатформу. Наполним приложение картами складов, подгрузкой базы ikea ну и, конечно, сделаем, чтобы всё работало offline.
Ну и дублирую ссылку на репу проекта.
Используемый материал:
Полезные материалы:
Кейс, конечно, с натяжкой. Имея фотки чеков в телефоне совсем не обязательно, чтобы телефон их распознавал, по фотке и так прекрасно видно, где и что тебе надо достать. С другой стороны, нам интересен пример работы такого софта + мы можем упростить себе жизнь, разместив весь нужный нам товар на карте склада. Т.е. имея 4-5 фото чеков, мы можем распознать их и построить карту маршрута беготни по складу самообслуживания. Отлично, одну причину для реализации нашей задумки придумали. Вторая причина — цвета. Лично я не раз сталкивался с тем, что ты фоткаешь чек, например, чёрного комода, не обращая внимания на то, что рядом стоит белый, который тебе и нужен, чей чек ты и хотел сфоткать. При распознании чека мы можем сразу показывать превью пользователю того товара, что на чеке (а значит и на месте на складе самообслуживания). Отлично, вторая причина, притянутая за уши, найдена.
Итого, что нам необходимо сделать?
- Найти чек ikea на изображении.
- Идентифицировать чек и подготовить данные с чека для распознавания.
- Распознать данные.
Определяем инструментарий. Работать с изображением будем с помощью
Выбор OpenCV очевиден. Даже профи, способные переписать большинство алгоритмов обработки изображения руками, чаще всего пользуются именно OpenCV. Не даром эта библиотека расшифровывается как «Open Source Computer Vision Library». Хотя чисто в теории можно придумать решение наших кейсов на gd+imagick. Но это извращение.
OpenCV будет отвечать за поиск чека на камере + за подготовку чека к распознаванию.
В своё время я использовал Tesseract для распознавания капчи яндекса, рамблера, гугла. Нет сомнений, что данная библиотека легко справится с распознаванием обычного текста. Ну и если честно, будучи «профаном» в ocr, я просто не знаю ничего другого настолько мощного с открытым кодом.
NodeJS исключительно личный выбор. В данный момент я делаю много всего на JS и данный язык просто ближе чисто синтаксиально, если такое слово вообще есть.
Я не претендую на быстроту и качество алгоритмов и тем более на чистый код, задачей для меня было исключительно быстро вспомнить компьютерное зрение, обновить свои знания и реализовать какой-либо проект. Поэтому любые правки и критика только приветствуются, но, пожалуйста, без истерии. Ну и повторю, я делюсь практикой для таких же «старикашек» как я сам, дабы не быть полным лохом среди тусовки молодых прогеров (где мои 17 лет…).
Погнали. Я создал
1. Обнаружение чека на изображении.
Библиотека OpenCV очень мощная и далеко не ограничивается теми возможностями, о которых я расскажу в данной статье. Вначале я не даром оговорился, что нашу задачу могут решить GD+IMagick. В частности, профи скорее всего для обнаружения чека применили бы технику Template Matching, но мы пойдём более простым путём. Благо, ikea нам в этом сильно помогает.
Первое, что нам надо знать, чек с инфой о местонахождении товара всегда красный. Отлично, от этого и будем отталкиваться.
// convert to HSV
process.convertHSVscale();
// find only red
process.inRange([0,100,100], [10,255,255]);Конвертируем наше изображение (которое в данном случае прочитано в переменную process) в HSV и ищем изображение между заданными каналами. Я слабо себе представляю как это работает, но в поисках возможности выделить из изображения конкретный цвет и его гамму наткнулся на два материала, статью разработчика и официальную документацию. Из кода видно, что я использую матрицу между [0,100,100] и [10,255,255] в палитре HSV. Из официальной документации на тему выделения цвета следует, что общее правило очень простое. Мы берём [h-10, 100, 100] и [h+10, 255,255], где h — нужный нам цвет. Я использовал сервис colorizer.org для получения индексов.
Посмотрим, что получилось.
Отлично, мы вычленили красный и его оттенки. Итого нашли чек, мою руку и красный квадрат на принте ковра. Теперь с помощью метода findContour мы легко можем отделить «мух от котлет», т.е. найти «границы» в нашем изображении.
var possibleContour = []; // готовим массив для найденных контуров по нашим условиям
var contours = process.findContours();
for (var i = 0; i < contours.size(); i++) {
if (contours.area(i) < 20000) continue; // исключаем мелкие зоны
var arcLength = contours.arcLength(i, true);
contours.approxPolyDP(i, 0.05 * arcLength, true); // сглаживаем углы («между нами тает лёд…»)
switch(contours.cornerCount(i)) {
case 4:
contourImg.drawContour(contours, i, [0,255,0]); // в случае нахождения знатных контуров из 4-ёх точек делаем им зелёный бордер
break;
default:
contourImg.drawContour(contours, i, [0,0,255]); // иначе делаем красный бордер
}
if (contours.cornerCount(i) ==4) { // ну и кладём контуры из 4-ёх точек в подготовленный массив. Точнее не контур, а точки, описывающие его.
possibleContour.push(pointOrder(contours.points(i)));
}
}Обращаю внимание на строки
var arcLength = contours.arcLength(i, true);
contours.approxPolyDP(i, 0.05 * arcLength, true); // сглаживаем углы («между нами тает лёд…»)С помощью метода approxPolyDP мы «сглаживаем углы» найденных контуров, устраняя «шум». Подробнее можно прочитать на страницах официальной документации.
Так же стоит отметить, что findContour отлично справляется со своей задачей, но порядок найденных точек может быть непредсказуемым. Нам же важно сохранить порядок точек в формате top-left, top-right, bottom-right, bottom-left для правильной перспективы.
Казалось бы, задача простая, найти top-left точку итп. На практике это обернулось в кучу форов по массивам. Начал гуглить, наткнулся на отличный блог по компьютерному зрению и opencv, в том числе разработчик предложил хитрость для поиска этих самых «экстремумов» для нужных нам позиций. В частности минимальная сумма x+y координат будет всегда равна top-left точке, тогда как максимальная сумма будет равна bottom-right. Аналогично максимальная разносить x-y будет равна точке top-right и минимальная будет равен точке bottom-left. Получаем метод pointOrder
pointOrder: function (point) {
var ordered = [];
var sum = [];
for (var x in point) {
sum[x] = point[x].x+point[x].y;
}
ordered[0] = point[sum.indexOf(_.min(sum))];
ordered[2] = point[sum.indexOf(_.max(sum))];
var diff = [];
for (var x in point) {
diff[x] = point[x].x-point[x].y;
}
ordered[1] = point[diff.indexOf(_.max(diff))];
ordered[3] = point[diff.indexOf(_.min(diff))];
return ordered;
}Очередность нам нужна для перкспективы. Мы заранее знаем точки горизонтали и вертикали (это 0/0, maxWidth/0, maxWidth/maxHeight и 0/maxHeight) и чтобы не перевернуть изображение, нам надо передавать точки нашего контура именно в этом порядке.
Подготовили контуры, следующим шагом выравниваем перспективу.
var warpImg = [];
for (var x in possibleContour) {
var point = possibleContour[x];
var maxWidth = 0;
var maxHeight = 0;
var tmp = 0;
// ищем конечные размеры width/height
if (pointWidth(point[0], point[1]) >pointWidth(point[3], point[2])) {
maxWidth = Math.round(pointWidth(point[0], point[1]));
} else {
maxWidth = Math.round(pointWidth(point[3], point[2]));
}
if (pointWidth(point[0], point[3]) >pointWidth(point[1], point[2])) {
maxHeight = Math.round(pointWidth(point[0], point[3]));
} else {
maxHeight = Math.round(pointWidth(point[1], point[2]));
}
// берём оригинальное изображение без цветовых искажений
var tmpWarpImg = img.copy();
var srcWarp = [point[0].x, point[0].y, point[1].x, point[1].y, point[2].x, point[2].y, point[3].x, point[3].y];
var dstWarp = [0, 0, maxWidth, 0, maxWidth, maxHeight, 0, maxHeight];
var perspective = tmpWarpImg.getPerspectiveTransform(srcWarp, dstWarp);
tmpWarpImg.warpPerspective(perspective, maxWidth, maxHeight, [255, 255, 255]);
warpImg.push(tmpWarpImg);
}Находим 2 контура, как видно из изображения. Один нужный нам, второй «шумный».
2. Идентифицируем чек и готовим данные.
Первым делом исключаем «левые» контуры от противного, т.е. сразу идентифицируем чек. А что мы знаем про чек? Верно, он прямоугольной формы, в нём текст и 3 прямоугольника с данными. От них и будем отталкиваться. Уже в найденных изображениях по аналогии ищем контуры, однако в этот раз мы выделяем только те найденные области, в которых есть 3 прямоугольных контура.
// filter wrapped img
var trueWarpImg = [];
for (var x in warpImg) {
var warpedImg = warpImg[x].copy();
// convert to HSV
warpedImg.convertHSVscale();
// find only red
warpedImg.inRange([0,100,100], imgProc.[10,255,255]);
var possibleContour = [];
var contourImg = warpImg[x].copy();
var contours = warpedImg.findContours();
for (var i = 0; i < contours.size(); i++) {
if (contours.area(i) < 2000 || contours.area(i) > 20000) continue; // в этот раз ищем более мелкие области
var arcLength = contours.arcLength(i, true);
contours.approxPolyDP(i, 0.05 * arcLength, true);
switch(contours.cornerCount(i)) {
case 4:
contourImg.drawContour(contours, i, [0,255,0]);
break;
default:
contourImg.drawContour(contours, i, [0,0,255]);
}
if (contours.cornerCount(i) ==4) {
possibleContour.push(pointOrder(contours.points(i)));
}
}
// лишь в случае, если найдено 3 прямоугольника, мы продолжаем обработку
if (possibleContour.length == 3) {
var trueContour = [];
var width = [];
var tmpContour = _.cloneDeep(possibleContour);
// сортируем найденные контуры. Сначала код товара, потом ряд и место.
for (var x2 in tmpContour) {
width.push(tmpContour[x2][1].x - tmpContour[x2][0].x);
}
var maxIndex = width.indexOf(_.max(width));
trueContour[0] = tmpContour[maxIndex];
var left = [];
for (var x2 in tmpContour) {
if (x2 == maxIndex) continue;
left.push(tmpContour[x2][0].x);
}
trueContour[1] = tmpContour[left.indexOf(_.min(left))];
trueContour[2] = tmpContour[left.indexOf(_.max(left))];
trueWarpImg.push({img: warpImg[x], contour: trueContour});
}
}Ох, ну в общем я предупреждал, что задача была БЫСТРО рассмотреть пример, с дублированием кода я особо не заморачивался. Да и не люблю этим заниматься, когда проект не готовится на про. Да и если уж быть откровенным, для многих продакшен проектов во некоторых местах я оставляю дублирование кода, чтобы новичкам было проще его читать. Обращаем внимание, что контуры могут быть найдены в рандомном порядке, нам же важно знать их порядок, где артикул товара, где ряд, а где место.
На выходе мы нашли чек ikea, убедились, что это он + вычленили данные для распознавания.
3. Распознаём данные.
Для того, чтобы упростить tesseract жизнь, обрежем наши изображения, вычленим красный (дабы сделать изображение чб) и увеличим. Увеличение немного замедляет tesseract, но на порядок увеличивает % распознавания.
// ocr img
for (var x in labelImg) {
var label = labelImg[x];
for (var x2 in label) {
var labelLine = label[x2];
// convert to HSV
labelLine.convertHSVscale();
// find only red
labelLine.inRange([0,100,100], [10,255,255]);
// labelLine.gaussianBlur([5,5]); // была идея блюрить для пущего страха, но на практике пока не потребовалось.
labelLine.resize(labelLine.width()*3,labelLine.height()*3);
Tesseract.recognize(labelLine.toBuffer(), {
lang: 'eng',
tessedit_char_whitelist: '0123456789.'
})
.progress(function(msg){/*console.log('tesseract', msg)*/})
.catch(function(msg){/*console.log('tesseract', msg)*/})
.then(function(result){console.log('"', result.text.trim(), '"')});
}
}Получаем в консоли
Вполне не плохо.
В следующих частях мы перенесём код на мобильные платформы и сделаем мобильную кроссплатформу. Наполним приложение картами складов, подгрузкой базы ikea ну и, конечно, сделаем, чтобы всё работало offline.
Ну и дублирую ссылку
Используемый материал:
- Отличный материал о детекте цвета на изображении
- Официальная документация относительно поиска определённого цвета на изображении
- Удобный сервис манипуляции с цветом, в том числе для работы с HSV
- Поиск контуров в OpenCV
- Сглаживаем углы найденных контуров, убирая шум
- Поиск top-left, top-right, bottom-right, bottom-left точек из заданных
Полезные материалы:
