Задача планировщика в Go — распределять запущенные горутины между потоками ОС, которые могут исполняться одним или большим количеством процессоров. В многопоточных вычислениях, возникли две парадигмы в планировании: делиться задачами (work sharing) и красть задачи (work stealing).
- Work-sharing: Когда процессор генерирует новые потоки, он пытается мигрировать их на другие процессоры, в надежде, что они попадут к простаивающему или недостаточно нагруженному процессору.
- Work-stealing: Недостаточно нагруженный процессор активно ищет потоки других процессоров и "крадет" некоторые из них.
Миграция потоков происходит реже при work stealing подходе, чем при work sharing. Когда все процессоры заняты, потоки не мигрируют. Как только появляется простаивающий процессор, рассматривается вариант миграции.
В Go начиная с версии 1.1 планировщик реализован по схеме work stealing и был написан Дмитрием Вьюковым. Эта статья подробно объясняет устройство work stealing планировщиков и как он устроен в Go.
Основы планирования
Планировщик Go выполнен по M:N схеме и может использовать несколько процессоров. В любой момент M горутин должны быть распределены между N потоками ОС, которые бегут на максимум GOMAXPROCS процессорах. В Go планировщике используется следующая терминология для горутин, потоков и процессоров:
- G: горутина
- M: поток ОС (M от Machine)
- P: процессор
Далее у нас есть две очереди, специфичные для P. Каждый M должен быть назначен к своему P. P-ы могут не иметь M, если они заблокированы или ожидают окончания системного вызова. В любой момент может быть максимум GOMAXPROCS процессоров — P. В любой момент только один M может исполняться на каждый P. Больше M может создаваться планировщиком, если это требуется.
Каждый цикл планирования заключается в поиске горутины, которая готова к тому, чтобы быть запущенной и её исполнения. При каждом цикле поиск присходит в следующем порядке:
runtime.schedule() {
// только 1/61 от всего времени, проверить глобальную очередь G
// если не найдено, проверить локальную очередь
// если не найдено, то:
// попытаться украсть у других P
// если не вышло, проверить глобальную очередь
// если всё равно не вышло, поллить (poll) сеть
}Как только готовая к исполнению G найдена, она исполняется, пока не будет заблокирована.
Заметка: Может показаться, что глобальная очередь имеет преимущество перед локальной, но регулярная проверка глобальной очереди критична для избежания M использования только горутин из локальной очереди.
"Кража" (Stealing)
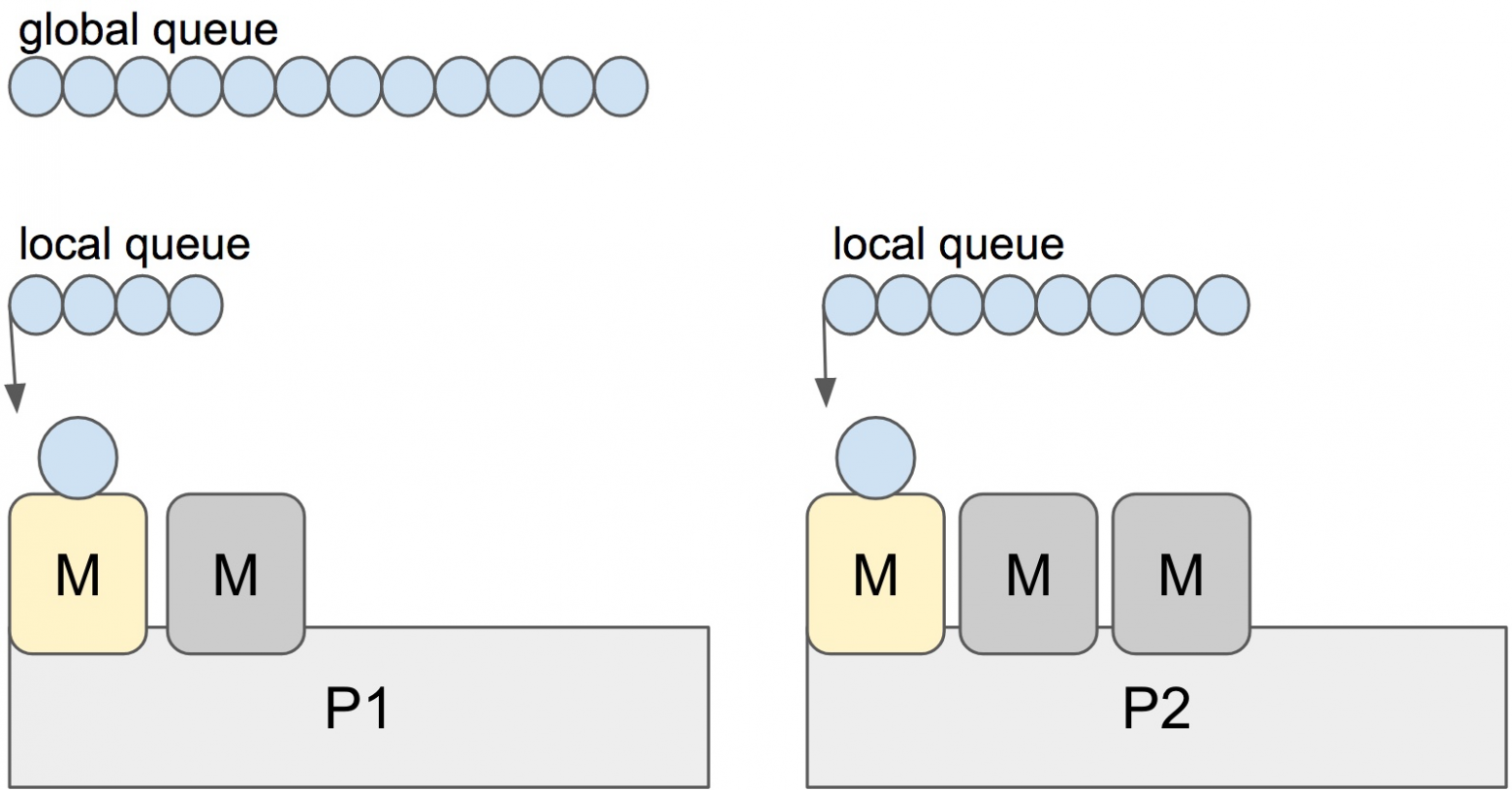
Когда новая G создается или существующая G становится готовой к исполнению, она помещается в локальную очередь готовых к исполнению горутин текущего P. Когда P заканчивается исполнение G, он пытается вытащить (pop) G из своей очереди. Если список пуст, P выбирает случайным образом другой процессор (P) и пытается украсть половину горутин из его очереди.

В примере выше, P2 не может найти готовых к исполнению горутин. Поэтому он случайно выбирает другой процессор (P1) и крадёт три горутины в свою очередь. P2 теперь сможет их запустить и работа будет более равномерно распределена между процессорами.
Spinning потоки
Планировщик всегда хочет распределить как можно больше готовых к исполнению горутин на много M, чтобы использовать все процессоры, но, в тоже время, мы должны уметь приостанавливать (park) сильно прожорливые процессы, чтобы сохранять ресурсы CPU и энергию. И при этом, планировщик должен также уметь масштабироваться для задач, которые действительно требуют много вычислительной мощности процессора и большую производительность.
Постоянное вытеснение (preemption) одновременно и дорогое и проблематичное для высоко-производительных программ, где производительность критичней всего. Горутины не должны постоянно прыгать между потоками ОС, поэтому это приводит к повышенной задержки (latency). В добавок ко всему, когда вызываются системные вызовы, поток должен быть постоянно блокироваться и разблокироваться. Это дорого и приводит к большим накладным расходам.
Чтобы уменьшить эти прыжки горутин туда-сюда, планировщик Go реализует так называемые зацикленные потоки (spinning threads). Эти поток используют чуть больше процессорной мощности, но уменьшают вытеснение потоков. Поток считается зациклен, если:
- M назначенный на P ищет горутину, которую бы можно было запустить
- M не назначенный на P, ищет доступные P.
- планировщик также запускает дополнительный поток и зацикливает его, когда готовит новую горутину и есть простаивающий P и нет других зацикленных потоков
В любой момент времени может быть максимум GOMAXPROCS зацикленных M. Когда зацикленный поток находит работу, он выходит из зацикленного состояния.
Простаивающие поток, назначенные на какой-либо P не блокируются, если есть другие M, не назначенные на P. Если создается новая горутина или блокируется M, планировщик проверяет и гарантирует, что есть хотя бы один зацикленный M. Это гарантирует, что все горутины могут быть запущены, если есть возможность и позволяет избежать излишних блокировок/разблокировок M.
Выводы
Планировщик Go делает много всего для избежания избыточного вытеснения потоков, распределяя их по недоиспользованным процессорам методом "кражи", и также реализацией "зацикленных" потоков, чтобы избежать частых переходов из блокирующего в неблокирующее состояние и обратно.
События планирования можно отслеживать с помощью execution tracer-а. Вы можете детально докопаться до всего, что происходит внутри планировщика, особенно если считаете, что в вашем случае происходит не эффективное использование процессоров.
Ссылки
- The Go runtime scheduler source
- Scalable Go Scheduler design document
- The Go scheduler by Daniel Morsing
Если у вас есть предложения или комментарии, пишите @rakyll.
