
Пару месяцев назад мы переехали из Амазон на свои выделенные сервера(Hetzner), одна из причин тому была высокая стоимость RDS. Встала задача настроить и запустить master-slave кластер на выделенных серверах. После гугления и прочтения официальной документации, было принято решение собрать свое собственное решение высокодоступного асинхронного кластера Postgres.
Цели
- Использовать как можно меньше инструментов и зависимостей.
- Стремится к прозрачности, никакой магии!
- Не использовать комбайны all-included типа pg-pool, stolon etc.
- Использовать докер и его плюшки.
Итак, начнём. Собственно нам понадобится сам Postgres и такой замечательный инструмент как repmgr, который занимается управлением репликаций и мониторингом кластера.
Проект называется pg-dock, состоит из 3 частей, каждая часть лежит на гитхабе, их можно брать и видоизменять как заблагорассудится.
- pg-dock-config готовый набор файлов конфигурации, сейчас там прописано 2 нода, мастер-слейв.
- pg-dock занимается упаковкой конфигов и доставкой их на ноды, в нужном виде и в нужное место.
- pg-dock-base это базовый докер образ который и будет запускаться на нодах.
Давайте детально разберем каждую часть:
pg-dock-config
Конфигурация кластера, имеет следующую структуру
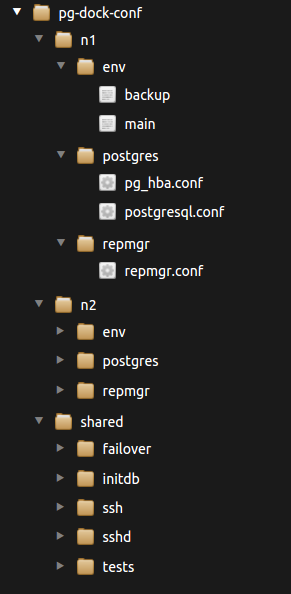 |
В репозитории уже прописаны два нода (n1, n2), если нод у Вас больше, то просто создаем еще одну папку с названием новой ноды. Для каждый ноды свои файлы конфигурации. Мне кажется тут всё довольно просто, например папка env это переменные окружения которые будут подхватываться docker-compose'ом, папка postgres соответственно конфиги постгреса и.т.д. Например файл pg-dock-conf/n1/env/main Говорит нам о том что при первичной инициализации постгреса будет создан юзер postgres и база testdb. Так же тут прописаны переменные для failover-ip скрипта который меняет ip на новую мастер ноду в случае если старая стала не доступной. pg-dock-conf/n1/env/backup Переменные окружения для интервального бекапа базы на s3, подхватывается docker-compose'ом при старте сервиса. |
Если у нас есть общие файлы конфигурации, то что бы не дублировать их по нодам, будем класть их в папку shared.
Пройдемся по ее структуре:
- failover
В моем случае там скрипт для Hetzner failover-ip, который меняет ip на новый мастер. В Вашем случае это может быть скрипт keepalived или еще что то подобное. - initdb
Все инициализирующие sql запросы надо положить в эту папку. - ssh
Тут лежат ключи подключения к другому ноду, в нашем примере, ключи на всех нодах одни и те же, поэтому они лежат в папке shared. ּּSsh нужен repmgr что бы делать такие манипуляции как switchover и.т.п - sshd
Файл конфигурации ssh сервера, ssh у нас будет работать на порту 2222 что бы не пересекаться с дефолтным портом на хосте (22)
pg-dock
Тут собственно происходит упаковка конфигурации для каждой ноды.
Суть заключается в том что бы запаковать конфигурацию ноды в докер образ, запушить его в хаб или свой registry, и потом на ноде сделать обновление.
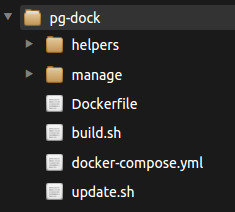 |
Для работы есть базовые операции, создать билд конфига (build.sh), обновить конфиг на ноде (update.sh) и запустить сам кластер (docker-compose.yml)
|
При запуске:
PG_DOCK_NODE=n1 PG_DOCK_CONF_IMAGE=n1v1 ./build.sh
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
n1v1 latest 712e6b2ace1a 6 minutes ago 1.17MB
Конфигурация pg-dock-conf/n1 скопируется в папку pg-dock/pg-dock-conf-n1, затем запустится docker build со всеми зависимостями, на выходе получаем образ с именем n1v1 в котором хранится наша конфигурация для нода n1.
При запуске:
PG_DOCK_CONF_IMAGE=n1v1 ./update.shЗапустится контейнер, который обновит все файлы конфигурации на хосте. Таким образом мы можем иметь несколько образов конфигурации, делать rollback на разные версии и.т.п
pg-docker-base
Базовый docker образ в котором установлены все пакеты для работы кластера: repmgr, rsync, openssh-server, supervisor (Dockerfile). Сам образ базируется на последней версии postgres 9.6.3, но можно использовать любой другой билд. Компоненты запускаются supervisor'ом из под юзера postgres. Этот образ мы и будем запускать на наших серверах (rsync, openssh-server требуются для работы repmgr).
Давайте запустим кластер!
Для удобства, в этой статье все манипуляции будут происходит при помощи docker-machine.
Клонируем проекты pg-dock и pg-dock-conf в рабочую папку (для примера lab)
mkdir ~/lab && cd ~/lab
git clone https://github.com/xcrezd/pg-dock
git clone https://github.com/xcrezd/pg-dock-confСоздаем ноды, группу и пользователя postgres (uid, gid должен быть 5432 на хосте и в контейнере)
docker-machine create n1
docker-machine ssh n1 sudo addgroup postgres --gid 5432
docker-machine ssh n1 sudo adduser -u 5432 -h /home/postgres --shell /bin/sh -D -G postgres postgres
#для debian/ubuntu
#sudo adduser --uid 5432 --home /home/postgres --shell /bin/bash --ingroup postgres --disabled-password postgres
docker-machine create n2
docker-machine ssh n2 sudo addgroup postgres -g 5432
docker-machine ssh n2 sudo adduser -u 5432 -h /home/postgres --shell /bin/sh -D -G postgres postgresДобавляем ip нод в /etc/hosts
docker-machine ip n1
#192.168.99.100
docker-machine ip n2
#192.168.99.101
# в ноду n1
docker-machine ssh n1 "sudo sh -c 'echo 192.168.99.100 n1 >> /etc/hosts'"
docker-machine ssh n1 "sudo sh -c 'echo 192.168.99.101 n2 >> /etc/hosts'"
# в ноду n2
docker-machine ssh n2 "sudo sh -c 'echo 192.168.99.100 n1 >> /etc/hosts'"
docker-machine ssh n2 "sudo sh -c 'echo 192.168.99.101 n2 >> /etc/hosts'"Если IP ваших машин отличаются от IP в статье, то дополнительно надо добавить их в
- pg-dock-config/n1/postgres/pg_hba.conf
- pg-dock-config/n2/postgres/pg_hba.conf
Создаем образы конфигураций и сразу обновляем их на нодах
cd pg-dock
docker-machine use n1
PG_DOCK_NODE=n1 PG_DOCK_CONF_IMAGE=n1v1 ./build.sh
PG_DOCK_CONF_IMAGE=n1v1 ./update.sh
docker-machine use n2
PG_DOCK_NODE=n2 PG_DOCK_CONF_IMAGE=n2v1 ./build.sh
PG_DOCK_CONF_IMAGE=n2v1 ./update.shОбратите внимание на команду docker-machine use (как сделать), при каждом ее применении, мы меняем контекст докер клиента, то есть в первом случае все манипуляции с докером будут на ноде n1 а потом на n2.
Запускаем контейнеры
docker-machine use n1
PG_DOCK_NODE=n1 docker-compose up -d
docker-machine use n2
PG_DOCK_NODE=n2 docker-compose up -ddocker-compose так же запустит контейнер pg-dock-backup, который будет делать переодический бекап на s3.
Теперь посмотрим, где хранятся нужные нам файлы:
| Файлы |
Хост |
Контейнер |
| БД |
/opt/pg-dock/data |
/var/lib/postgresql/data |
| Логи |
/opt/pg-dock/logs |
/var/log/supervisor |
| Конфигурация и скрипты |
/opt/pg-dock/scripts |
** изучите docker-compose.yml |
Идем дальше, настраиваем кластер
docker-machine use n1
#Регестрируем как мастер ноду
docker exec -it -u postgres pg-dock repmgr master register
docker-machine use n2
#Клонируем данные из нода n1
docker exec -it -u postgres -e PG_DOCK_FROM=n1 pg-dock manage/repmgr_clone_standby.sh
#Регестрируем ноду как слейв
docker exec -it -u postgres pg-dock repmgr standby registerВот и все, кластер готов
docker exec -it -u postgres pg-dock repmgr cluster show
Role | Name | Upstream | Connection String
----------+------|----------|--------------------------------------------
* master | n1 | | host=n1 port=5432 user=repmgr dbname=repmgr
standby | n2 | n1 | host=n2 port=5432 user=repmgr dbname=repmgrДавайте проверим его роботоспособность. В папке pg-dock-config/shared/tests у нас есть такие вот заготовки для тестирования нашего кластера:
#Создает тестовую таблицу
cat tests/prepare.sh
CREATE TABLE IF NOT EXISTS testtable (id serial, data text);
GRANT ALL PRIVILEGES ON TABLE testtable TO postgres;
#Добавляет 100000 записей
cat tests/insert.sh
insert into testtable select nextval('testtable_id_seq'::regclass), md5(generate_series(1,1000000)::text);
#Считает сколько записей в таблице
cat tests/select.sh
select count(*) from testtable;
Cоздаем тестовую таблицу, набиваем ее данными и проверяем если они есть на слейве:
docker-machine use n1
#Создаем тестовую таблицу для проверки репликации
docker exec -it -u postgres pg-dock config/tests/prepare.sh
#Добавляем записи для проверки
docker exec -it -u postgres pg-dock config/tests/insert.sh
INSERT 0 1000000
docker-machine use n2
#Проверяем что записи находятся на n2 (репликация)
docker exec -it -u postgres pg-dock config/tests/select.sh
count
---------
1000000
(1 row)
Профит!
Теперь давайте рассмотрим сценарий падения мастера:
#Останавливаем мастер ноду
docker-machine use n1
docker stop pg-dock
#Смотрим логи repmgr у слейва
docker-machine use n2
docker exec -it pg-dock tailf /var/log/supervisor/repmgr-stderr.log
#NOTICE: STANDBY PROMOTE successfulПолный лог
[2017-07-12 12:51:49] [ERROR] unable to connect to upstream node: could not connect to server: Connection refused
Is the server running on host «n1» (192.168.99.100) and accepting
TCP/IP connections on port 5432?
[2017-07-12 12:51:49] [ERROR] connection to database failed: could not connect to server: Connection refused
Is the server running on host «n1» (192.168.99.100) and accepting
TCP/IP connections on port 5432?
[2017-07-12 12:51:49] [WARNING] connection to master has been lost, trying to recover… 60 seconds before failover decision
[2017-07-12 12:51:59] [WARNING] connection to master has been lost, trying to recover… 50 seconds before failover decision
[2017-07-12 12:52:09] [WARNING] connection to master has been lost, trying to recover… 40 seconds before failover decision
[2017-07-12 12:52:19] [WARNING] connection to master has been lost, trying to recover… 30 seconds before failover decision
[2017-07-12 12:52:29] [WARNING] connection to master has been lost, trying to recover… 20 seconds before failover decision
[2017-07-12 12:52:39] [WARNING] connection to master has been lost, trying to recover… 10 seconds before failover decision
[2017-07-12 12:52:49] [ERROR] unable to reconnect to master (timeout 60 seconds)…
[2017-07-12 12:52:54] [NOTICE] this node is the best candidate to be the new master, promoting…
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 171 100 143 0 28 3 0 0:00:47 0:00:39 0:00:08 31
ERROR: connection to database failed: could not connect to server: Connection refused
Is the server running on host «n1» (192.168.99.100) and accepting
TCP/IP connections on port 5432?
NOTICE: promoting standby
NOTICE: promoting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/data promote'
NOTICE: STANDBY PROMOTE successful
Is the server running on host «n1» (192.168.99.100) and accepting
TCP/IP connections on port 5432?
[2017-07-12 12:51:49] [ERROR] connection to database failed: could not connect to server: Connection refused
Is the server running on host «n1» (192.168.99.100) and accepting
TCP/IP connections on port 5432?
[2017-07-12 12:51:49] [WARNING] connection to master has been lost, trying to recover… 60 seconds before failover decision
[2017-07-12 12:51:59] [WARNING] connection to master has been lost, trying to recover… 50 seconds before failover decision
[2017-07-12 12:52:09] [WARNING] connection to master has been lost, trying to recover… 40 seconds before failover decision
[2017-07-12 12:52:19] [WARNING] connection to master has been lost, trying to recover… 30 seconds before failover decision
[2017-07-12 12:52:29] [WARNING] connection to master has been lost, trying to recover… 20 seconds before failover decision
[2017-07-12 12:52:39] [WARNING] connection to master has been lost, trying to recover… 10 seconds before failover decision
[2017-07-12 12:52:49] [ERROR] unable to reconnect to master (timeout 60 seconds)…
[2017-07-12 12:52:54] [NOTICE] this node is the best candidate to be the new master, promoting…
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 171 100 143 0 28 3 0 0:00:47 0:00:39 0:00:08 31
ERROR: connection to database failed: could not connect to server: Connection refused
Is the server running on host «n1» (192.168.99.100) and accepting
TCP/IP connections on port 5432?
NOTICE: promoting standby
NOTICE: promoting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/data promote'
NOTICE: STANDBY PROMOTE successful
Смотрим статус кластера:
docker exec -it -u postgres pg-dock repmgr cluster show
Role | Name | Upstream | Connection String
---------+------|----------|--------------------------------------------
FAILED | n1 | | host=n1 port=5432 user=repmgr dbname=repmgr
* master | n2 | | host=n2 port=5432 user=repmgr dbname=repmgrТеперь новый мастер у нас n2, failover ip тоже указывает на него.
Теперь давайте вернем старый мастер уже как новый слейв
docker-machine use n1
#Поднимаем контейнеры
PG_DOCK_NODE=n1 docker-compose up -d #как демон
#Клонируем данные из ноды n2
docker exec -it -u postgres -e PG_DOCK_FROM=n2 pg-dock manage/repmgr_clone_standby.sh
#Регестрируем ноду как слейв
docker exec -it -u postgres pg-dock repmgr standby register -FСмотрим статус кластера:
docker exec -it -u postgres pg-dock repmgr cluster show
Role | Name | Upstream | Connection String
---------+------|-----------|--------------------------------------------
* master | n2 | | host=n2 port=5432 user=repmgr dbname=repmgr
standby| n1 | n2 | host=n1 port=5432 user=repmgr dbname=repmgrГотово! И вот, что у нас получилось сделать; Мы уронили мастер, сработало автоматическое назначение слейва новым мастером, поменялся failover IP. Система продолжает функционировать. Потом мы реанимировали ноду n1, сделали ее новым слейвом. Теперь уже ради интереса, мы сделаем swithover — то есть вручную сделаем n1 мастером а n2 слейвом, как было раньше. Вот как раз для этого repmgr и нужен ssh, слейв подключается по ssh к мастеру и скриптами делает нужные манипуляции.
switchover:
docker-machine use n1
docker exec -it -u postgres pg-dock repmgr standby switchover
#NOTICE: switchover was successfulПолный лог
NOTICE: switching current node 1 to master server and demoting current master to standby…
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
NOTICE: 1 files copied to /tmp/repmgr-n2-archive
NOTICE: current master has been stopped
ERROR: connection to database failed: could not connect to server: Connection refused
Is the server running on host «n2» (192.168.99.101) and accepting
TCP/IP connections on port 5432?
NOTICE: promoting standby
NOTICE: promoting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/data promote'
server promoting
NOTICE: STANDBY PROMOTE successful
NOTICE: Executing pg_rewind on old master server
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
NOTICE: 1 files copied to /var/lib/postgresql/data
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
NOTICE: restarting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -w -D /var/lib/postgresql/data -m fast restart'
pg_ctl: PID file "/var/lib/postgresql/data/postmaster.pid" does not exist
Is server running?
starting server anyway
NOTICE: replication slot «repmgr_slot_1» deleted on node 2
NOTICE: switchover was successful
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
NOTICE: 1 files copied to /tmp/repmgr-n2-archive
NOTICE: current master has been stopped
ERROR: connection to database failed: could not connect to server: Connection refused
Is the server running on host «n2» (192.168.99.101) and accepting
TCP/IP connections on port 5432?
NOTICE: promoting standby
NOTICE: promoting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/data promote'
server promoting
NOTICE: STANDBY PROMOTE successful
NOTICE: Executing pg_rewind on old master server
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
NOTICE: 1 files copied to /var/lib/postgresql/data
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
Warning: Permanently added '[n2]:2222,[192.168.99.101]:2222' (ECDSA) to the list of known hosts.
NOTICE: restarting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -w -D /var/lib/postgresql/data -m fast restart'
pg_ctl: PID file "/var/lib/postgresql/data/postmaster.pid" does not exist
Is server running?
starting server anyway
NOTICE: replication slot «repmgr_slot_1» deleted on node 2
NOTICE: switchover was successful
Смотрим статус кластера:
docker exec -it -u postgres pg-dock repmgr cluster show
Role | Name | Upstream | Connection String
----------+------|----------|--------------------------------------------
standby | n2 | | host=n2 port=5432 user=repmgr dbname=repmgr
* master | n1 | | host=n1 port=5432 user=repmgr dbname=repmgrВот и все, в следующий раз когда нам надо обновить конфигурацию ноды, будь то конфиг postgres, repmgr или supervisor'a, мы просто пакуем ее и обновляем:
PG_DOCK_NODE=n1 PG_DOCK_CONF_IMAGE=n1v1 ./build.sh
PG_DOCK_CONF_IMAGE=n1v1 ./update.shПосле обновления новой конфигурации:
#Обновляем конфигурацию postgres
docker exec -it -u postgres pg-dock psql -c "SELECT pg_reload_conf();"
#Обновляем конфигурацию supervisor
docker exec -it -u postgres pg-dock supervisorctl reread
#перезапускаем отдельный процесс
docker exec -it -u postgres pg-dock supervisorctl restart foo:sshd* Приятный бонус, supervisor имеет функцию ротацию логов, так что и за это нам не надо переживать.
* Контейнеры работают напрямую через сеть хоста, тем самым избегая задержек виртуализации сети.
* Рекомендую добавить уже существующие продакшен ноды в docker-machine, это сильно упростит Вам жизнь.
Теперь давайте коснемся темы балансировки запросов. Не хотелось усложнять (то есть использовать pg-pool, haproxy, stolon) поэтому балансировку мы будем делать на стороне приложения, тем самым снимая с себя обязанности по организации высокодоступности уже самого балансировщика. Наши бекенды написаны на руби, поэтому выбор пал на гем makara. Гем умеет разделять запросы на выборку и модификацию данных (insert/update/delete/alter), запросы на выборку можно балансировать между несколькими нодами (слейвами). В случае отказа одного из нод, гем умеет временно исключать его из пула.
Пример файла конфигурации database.yml:
production:
adapter: 'postgresql_makara'
makara:
# the following are default values
blacklist_duration: 5
master_ttl: 5
master_strategy: failover
sticky: true
connections:
- role: master
database: mydb
host: 123.123.123.123
port: 6543
weight: 3
username: <%= ENV['DATABASE_USERNAME'] %>
password: <%= ENV['DATABASE_PASSWORD'] %>
- role: slave
database: mydb
host: 123.123.123.124
port: 6543
weight: 7
username: <%= ENV['DATABASE_USERNAME'] %>
password: <%= ENV['DATABASE_PASSWORD'] %>
Библиотеки на других языках/фреймворках:
→ laravel
→ Yii2
→ Node.js
Заключение
Итак, что мы получили в итоге:
- Самодостаточный кластер master-standby готовый к бою.
- Прозрачность всех компонент, легкая заменимость.
- Автоматический failover в случае отказа мастера (repmgr)
- Балансировка нагрузки на клиенте, тем самым снимая ответственность за доступность самого балансировщика
- Отсутствие единой точки отказа, repmgr запустит скрипт который перенесет IP адрес на новую ноду, которая была повышена до мастера в случае отказа. В темплейте есть скрипт для hetzner, но ничего не мешает добавить keepalived, aws elasticIp, drdb, pacemaker, corosync.
- Контроль версий, возможность делать rollback в случае неполадок / ab testing.
- Возможность настроить систему под себя, добавлять ноды, repmgr witness, например, гибкость конфигурации и ее изменений.
- Периодический бекап на S3
В следующей статье я расскажу, как на одной ноде разместить pg-dock и PgBouncer не теряя при этом в высокодоступности, всем спасибо за внимание!
Рекомендации к ознакомлению:
