В этой статье мы приводим значения задержек, измеренных для двух типов окружений — устройство на основе FPGA CEPappliance (“железка”) и компьютер с сетевой платой Solarflare в режиме TCPDirect, рассказываем как мы эти замеры получили — описываем методику измерения и ее техническую реализацию. В конце статьи есть ссылка на GitHub с полученными результатами и некоторыми исходниками.
Как нам кажется, полученные нами результаты могут быть интересны высокочастотным трейдерам, алготрейдерам и всем неравнодушным к обработке данных с малыми задержками.
Схема измерительного стенда выглядит так:

SUT (System Under Test) — либо CEPappliance, либо сервер с Solarflare (характеристики тестируемых систем см. ниже).
У CEPappliance и Solarflare есть общая сфера применения — высокочастотный и алгоритмический трейдинг. Поэтому мы взяли за основу сценарий из этой сферы, измеряя величину задержки от момента отправки тестовым драйвером последнего байта пакета с рыночными данными (tick) до момента получения им первого байта пакета с заявкой (trade) на биржу (задержка MAC и PHY уровней драйвера одинакова для обоих тестовых сред и вычтена из результирующих значений, приведенных ниже) — так называемая задержка tick-to-trade. Замеряя время от момента отправки драйвером последнего байта, мы исключаем влияние скорости приема/передачи данных, завясящую от физического уровня.
Измерять задержку можно и по другой методике — как время от момента отправки драйвером первого байта до момента получения им первого байта от измеряемой системы. Такая задержка будет больше и может быть расчитана на основе наших измерений по формуле:
latency1-1 = latencyN-1 + 6.4 * int((N + 7) / 8),
где latencyN-1 — измеренная нами задержка (от момента отправки драйвером последнего байта до момента получения им первого байта), N — длина Ethernet фрейма в байтах, int(x) — преобразование к целому, отбрасываением дробной части вещественного числа.
Вот схема обработки, время выполнения которой составляет интересующую нас задержку:

Что из себя представляют стадии тестирования?
Подготовка:
Тестирование:
Обработка результатов тестирования:
В качестве SUT выступает сервер с материнской платой Asus P9X79 WS, процессором Intel Core i7-3930K CPU @ 3.20GHz и сетевой картой SFN8522-R2 Flareon Ultra 8000 Series 10G Adapter, поддерживающей TCPDirect.
Для этого стенда была написана С-программа, которая получает UDP пакеты через Solarflare TCPDirect API, разбирает их, строит книгу заявок, формирует и отправляет сообщение на покупку по протоколу FIX.
Разбор сообщения, построение стакана формирование сообщения с заявкой закодированы “жестко” без поддержки каких-либо вариаций и проверок, чтобы обеспечить минимальную задержку. С кодом можно ознакомиться на GitHub.
В качестве SUT выступает CEPappliance или “железка”, как мы ее называем, — это плата DE5-Net с FPGA чипом Altera Stratix V, вставленная в PCIe слот сервера, через который она получает питание и больше ничего. Управление и обмен данными с платой осуществляется через 10G Ethernet подключение.
Мы уже рассказывали, что наша прошивка для FPGA чипа содержит много разных компонентов, в том числе все необходимое для реализации сценария тестирования, описанного здесь.
Программа сценария для CEPappliance содержится в двух файлах. В одном файле программа логики обработки данных, которую мы называем схемой. В другом файле описание адаптеров, через которые схема (или “железка” ее выполняющая) взаимодействует с внешним миром. Вот так просто!
Для CEPappliance мы реализовали две версии схемы и для каждой версии сделали замеры. В одной версии (CEPappliance ALU) логика реализована на встроенном языке высокого уровня (см. строки 47-67). В другой (CEPappliance WIRE) — на Verilog’е (см. строки 47-54).
Измеренные значения tick-to-trade задержки в наносекундах:
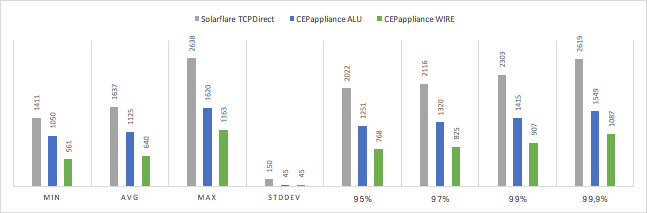
Чуда не произошло и “железка”, реализованная на основе FPGA, оказалась быстрее, чем решение на основе сервера с Solarflare TCPDirect. Чем выше перцентиль, тем заметнее разница в скорости. Одновременно с этим скорость работы решения на CEPappliance имеет дисперсию на порядок ниже.
Вариант для CEPappliance, когда логика обработки данных реализована на Verilog, быстрее на 60-70%, чем реализация того же алгоритма на встроенном языке CEPappliance.
Мы разместили почти весь исходный код, участвовавший в тестировании, открытым на GitHub в этом репозитории.
Закрытым оставили только код тестового драйвера, так как есть надежда его монетизировать. Ведь он позволяет очень точно измерить скорость реакции системы. А без этой информации сделать качественное HFT-решение почти невозможно.
Было бы логично выяснить имеет ли значение выявленная разница в задержках различных решений, например, при торговле на Московской бирже. Про это будет в следующей статье. Но забегая вперед, скажем, что даже полмикросекунды имеет значение!
Как нам кажется, полученные нами результаты могут быть интересны высокочастотным трейдерам, алготрейдерам и всем неравнодушным к обработке данных с малыми задержками.
Методика измерения: что и как мы измеряли
Схема измерительного стенда выглядит так:
SUT (System Under Test) — либо CEPappliance, либо сервер с Solarflare (характеристики тестируемых систем см. ниже).
У CEPappliance и Solarflare есть общая сфера применения — высокочастотный и алгоритмический трейдинг. Поэтому мы взяли за основу сценарий из этой сферы, измеряя величину задержки от момента отправки тестовым драйвером последнего байта пакета с рыночными данными (tick) до момента получения им первого байта пакета с заявкой (trade) на биржу (задержка MAC и PHY уровней драйвера одинакова для обоих тестовых сред и вычтена из результирующих значений, приведенных ниже) — так называемая задержка tick-to-trade. Замеряя время от момента отправки драйвером последнего байта, мы исключаем влияние скорости приема/передачи данных, завясящую от физического уровня.
Измерять задержку можно и по другой методике — как время от момента отправки драйвером первого байта до момента получения им первого байта от измеряемой системы. Такая задержка будет больше и может быть расчитана на основе наших измерений по формуле:
latency1-1 = latencyN-1 + 6.4 * int((N + 7) / 8),
где latencyN-1 — измеренная нами задержка (от момента отправки драйвером последнего байта до момента получения им первого байта), N — длина Ethernet фрейма в байтах, int(x) — преобразование к целому, отбрасываением дробной части вещественного числа.
Вот схема обработки, время выполнения которой составляет интересующую нас задержку:
Что из себя представляют стадии тестирования?
Подготовка:
- Входные данные — записанный дамп потока заявок с торговой системы АСТС Московской биржи в виде сообщений, упакованных по протоколу FAST и передаваемых по UDP
- Данные загружаются в память тестового драйвера с помощью утилиты
Тестирование:
- Тестовый драйвер
- отправляет записанные UDP пакеты (проигрывает дамп) с рыночными данными — информацией о заявках (orders) на покупку или продажу, принятых биржей; информация включает действие с заявкой — добавление новой заявки, изменение или удаление ранее добавленной заявки, идентификатор торгуемого финансового инструмента, цена покупки/продажи, количество лотов и т.п.;
- в одном пакете может содержаться информация об одной или нескольких заявках (после изменений в правилах упаковки данных, выпущенных биржей в марте 2017 года, мы встречали пакеты с информацией по 128-и заявкам!);
- запоминает время отправки пакета T1.
- Тестируемая система
- принимает пакет с информацией о заявках;
- распаковывает ее согласно заданным биржей правилам упаковки (сообщение X-OLR-CURR потока Orders с валютного рынка Московской биржи);
- обновляет свою внутреннюю книгу заявок (“стакан”), применяя все данные из полученного пакета;
- если лучшая (самая низкая) цена на продажу в книге изменилась, отправляет заявку на покупку с этой ценой по протоколу FIX.
- Тестовый драйвер
- получает TCP пакет с заявкой;
- фиксирует время получения T2;
- вычисляет задержку (T2 -T1) и запоминает ее.
- Тестирование выполняется на наборе из 90 000 пакетов с рыночными данными, на полученном наборе значений задержки вычисляются статистические величины (среднее, дисперсия, перцентили). Пакеты отправляются строго по очереди. После отправки пакета ждем ответа, либо истечение таймаута (если алгоритм не должен реагировать на этот пакет с рыночными данными). После этого отправляем следующий пакет и т.д.
Обработка результатов тестирования:
- Полученные средние значения задержки выгружаются из памяти тестового драйвера
- Каждое значение задержки сохраняется вместе со значением размера пакета входных данных, для которого оно было измерено
Стенд для Solarflare
В качестве SUT выступает сервер с материнской платой Asus P9X79 WS, процессором Intel Core i7-3930K CPU @ 3.20GHz и сетевой картой SFN8522-R2 Flareon Ultra 8000 Series 10G Adapter, поддерживающей TCPDirect.
Для этого стенда была написана С-программа, которая получает UDP пакеты через Solarflare TCPDirect API, разбирает их, строит книгу заявок, формирует и отправляет сообщение на покупку по протоколу FIX.
Разбор сообщения, построение стакана формирование сообщения с заявкой закодированы “жестко” без поддержки каких-либо вариаций и проверок, чтобы обеспечить минимальную задержку. С кодом можно ознакомиться на GitHub.
Стенд для “железки” CEPappliance
В качестве SUT выступает CEPappliance или “железка”, как мы ее называем, — это плата DE5-Net с FPGA чипом Altera Stratix V, вставленная в PCIe слот сервера, через который она получает питание и больше ничего. Управление и обмен данными с платой осуществляется через 10G Ethernet подключение.
Мы уже рассказывали, что наша прошивка для FPGA чипа содержит много разных компонентов, в том числе все необходимое для реализации сценария тестирования, описанного здесь.
Программа сценария для CEPappliance содержится в двух файлах. В одном файле программа логики обработки данных, которую мы называем схемой. В другом файле описание адаптеров, через которые схема (или “железка” ее выполняющая) взаимодействует с внешним миром. Вот так просто!
Для CEPappliance мы реализовали две версии схемы и для каждой версии сделали замеры. В одной версии (CEPappliance ALU) логика реализована на встроенном языке высокого уровня (см. строки 47-67). В другой (CEPappliance WIRE) — на Verilog’е (см. строки 47-54).
Результаты
Измеренные значения tick-to-trade задержки в наносекундах:
| SUT | min | avg | max | stddev | 95% | 97% | 99% | 99,9% |
|---|---|---|---|---|---|---|---|---|
| Solarflare TCPDirect | 1411 | 1637 | 2638 | 150 | 2022 | 2116 | 2303 | 2619 |
| CEPappliance ALU | 1050 | 1125 | 1620 | 45 | 1251 | 1320 | 1415 | 1549 |
| CEPappliance WIRE | 561 | 640 | 1163 | 45 | 768 | 825 | 907 | 1087 |
Выводы
Чуда не произошло и “железка”, реализованная на основе FPGA, оказалась быстрее, чем решение на основе сервера с Solarflare TCPDirect. Чем выше перцентиль, тем заметнее разница в скорости. Одновременно с этим скорость работы решения на CEPappliance имеет дисперсию на порядок ниже.
Вариант для CEPappliance, когда логика обработки данных реализована на Verilog, быстрее на 60-70%, чем реализация того же алгоритма на встроенном языке CEPappliance.
Исходный код
Мы разместили почти весь исходный код, участвовавший в тестировании, открытым на GitHub в этом репозитории.
Закрытым оставили только код тестового драйвера, так как есть надежда его монетизировать. Ведь он позволяет очень точно измерить скорость реакции системы. А без этой информации сделать качественное HFT-решение почти невозможно.
Что дальше?
Было бы логично выяснить имеет ли значение выявленная разница в задержках различных решений, например, при торговле на Московской бирже. Про это будет в следующей статье. Но забегая вперед, скажем, что даже полмикросекунды имеет значение!
