И снова здравствуйте, друзья!
Не так давно я поделился с вами своим опытом применения нейронной сети для для решения задачи выбора действия ботом. Чтобы подробнее узнать о сути задачи, пожалуйста, ознакомьтесь с первой частью статьи.
А я перейду к рассказу о следующем этапе работы!
После неудачного (но весьма полезного) опыта работы с нейронной сетью я стал изучать деревья решений и теорию игр. По ходу изучения вопроса у меня возникало множество идей и концепций, но я остановился на следующей:
Ниже приведена рекурсивная функция описывающая данный алгоритм:
Это только схематичное представление рекурсивной функции, на самом деле в построении дерева есть нюансы, о которых я расскажу чуть позже. Также я реализовал функцию для записи данных о дереве решений в файл, чтобы потом можно было наглядно посмотреть на то, как оно выглядит.

Дерево решений (размер JSON-файла: 4kb)
Это дерево построено для хода, где персонаж уже потратил немного энергии и на выбор ему предоставляется только 5 вариантов действий: 3 перемещения на соседние клетки, использование способности «Hit The Lights» и завершение хода. В каждом узле можно увидеть название действия, score — цифра сверху и selfScore — цифра снизу. Можно легко проследить, как формируется score на корневом уровне. Из-за того, что все массивы сортируются по score, оптимальное решение всегда сверху. Рассмотрим ещё одно дерево:

Дерево с раскрытым оптимальным вариантом решения (размер JSON-файла: 169kb)
К сожалению, показать вам полное дерево для этого случая я не смогу ввиду того, что оно займёт в высоту примерно 80000 пикселей. Пройдёмся по раскрытой ветке справа налево:
377 (endTurn) + 378 (move) + 373 (cast Defender Of The Faith) + 312 (cast Punishment Due) + 218 (move) = 1658
Для действия move значение score равно 1660. Разница в 2 очка из-за округления цифр до целых значений при выводе на экран. Посмотрим на значения selfScore для первого уровня дерева: действие move с selfScore равным 218 является не самым большим среди соседних узлов. Лучшим действием на этом уровне является использование «Defender Of The Faith» (selfScore = 244). Однако суммарный score (1660 против 1652) всё же больше у действия move. Получается, что без продумывания действий на весь ход использование способности в данной ситуации было бы не так оптимально.
Теперь давайте подробнее рассмотрим различные аспекты этого алгоритма.
Для оценки ситуации используется следующая функция:
Этот метод пробегается по всем персонажам, участвующим в битве и начисляет определённое количество очков за различные параметры:
Для того, чтобы оценить результат выполнения действия бот:
К копированию мы вернёмся чуть позже, а пока рассмотрим подробнее, что же из себя представляет симуляция на примере одной из самых простых по механике способностей в игре — «Die By The Sword».

У каждой способности в игре есть функция cast, которая наносит урон, исцеляет, применяет эффекты и т.д. Давайте посмотрим на функцию cast для «Die By The Sword»:
Из функции видно, что внутри этой функции есть как минимум 3 операции случайного характера (определение урона, определение попадания, определение критического удара), а также утилитарные методы вроде добавления звуков для воспроизведения на клиенте. Естественно, когда речь идёт о предсказании последствий, мы не можем воспользоваться этой функцией. Поэтому у каждой способности помимо функции cast есть ещё и castSimulation:
Для симуляции действий передвижения используется тот же метод — просто отрезаем ненужное и заменяем случайные методы на математическое ожидание.
После того, как базовый алгоритм был построен, я впервые увидел, что боты обдумывают ход и совершают действия. Было очень классно наблюдать, как они сами решают, как им поступить в той или иной ситуации. Но тут неожиданно всплыла следующая проблема — иногда они думают оооооочень долго. Настолько долго, что Socket.io падает, потому что событие ping'а не происходит из-за занятости Node.js расчётом дерева. Пришло время заняться оптимизацией.
Первое, что пришло мне в голову — это сделать построение дерева асинхронным. При помощи библиотеки async и метода eachOf я преобразовал все проходы по спискам действий в асинхронные, а все возвраты значений в callback'и. Но стало только хуже :( Дерево строилось медленнее раза в полтора, а отлаживать асинхронное построение глубокого дерева — это тот ещё квест…
Затем я стал экспериментировать с process.nextTick, я пробовал оборачивать в него разные куски кода, но никакого эффекта так и не заметил.
В итоге я пришёл к следующей схеме:
Данное решение оказалось оптимальным из рассмотренных мной, однако всё равно является блокирующим. Сокет продолжает падать при долгом «обдумывании» хода. Если у кого-то есть идеи касательно изменения архитектуры построения дерева и использования process.nextTick, я буду рад помощи)
Другая проблема заключалась в том, что иногда бот думал настолько долго, что я получал ошибку вида JavaScript heap out of memory. Ясно, что происходит переполнение оперативной памяти, так как дерево решений просто не умещается в отведённые по умолчанию 512 Мб места в памяти. Можно, конечно, расширить отведённое место, но это всё равно неправильно, лучше постараться уложиться в минимум. Слабым местом моей архитектуры было то, что мне приходилось хранить состояния всех боевых ситуаций по мере построения дерева. А так как объекты перед симуляцией полностью копируются, память просто захлёбывается. Первое, что я сделал — это уменьшил вес объектов перед построением дерева. Так, например есть ряд свойств у объекта Character, которые совершенно не участвуют в симуляции: инвентарь, массив сообщений в лог, массив звуков для проигрывания, цвета рамок для персонажей и т.д. Теперь перед построением дерева происходит облегчение объектов персонажей следующим образом:
Таким образом мне удалось снизить размер объекта каждого персонажа более чем на 40%. Но даже это не спасло меня от переполнения памяти. Я обсудил проблему с коллегой по работе и мы выяснили, что хранить ветку в памяти не имеет смысла после того, как она вернёт нам список действий. Ведь нас интересует лишь самое удачное решение, а остальные без надобности. Теперь сразу после возвращения результата, ветка просто удаляется:
После этого о переполнении памяти я забыл навсегда.
Несмотря на все предыдущие оптимизации обдумывание хода всё равно порой занимало порядка 30 секунд :( Следующим шагом стало добавление дополнительной функции usageLogic для каждой способности, которая описывала приемлемость её использования в зависимости от ситуации. Например, нет смысла кидать исцеление на персонажа с максимальным здоровьем, поэтому перед построением списка действий с участием такой способности выполним следующую проверку:
Таким образом и боты стали умнее и количество действий для выбора сократилось в разы. Но тем не менее, была одна способность, которая плодила большое количество действий:

Способность «Speed Of Light» позволяет тепепортировать персонажа на позицию в радиусе 6 клеток вокруг него.
Получается, что в худшем случае эта способность генерирует 35 действий. Дерево решений здесь получается очень широким. Решение пришло само собой после того, как я закончил реализацию функций usageLogic для способностей. Ведь исключить неудачные точки для перемещения тоже можно. Выше я уже упоминал о весах позиций и функции calculatePositionWeight. Так вот, на этапе построения списка клеток, доступных для перемещения можно оценить выгодность каждой и исключить самые слабые позиции:
Такой подход я применил как к обычному перемещению, так и к способностям, которые перемещают персонажа («Speed Of Light»).
Даже с такой оптимизацией бывают случаи, когда обдумывание затягивается.

Способность «I don't wanna Stop» восстанавливает 850 единиц энергии.
Возможность применения такой способности увеличивает время обдумывания в 2, а то и в 3 раза, т.к. после любого действия можно почти полностью восстановить энергию и начать думать над ходом заново.
Во избежание подобных «долгих» раздумий я ввёл пороговое время построения дерева. В данный момент оно составляет 3 секунды. Перед построением новой ветки с вариантами действий я сверяюсь с этим временем. Если оно превышено, значит строить дерево дальше нельзя и бот просто выбирает действие с учётом того, что он уже насчитал. Таким образом я решил ещё и проблему производительности на разных платформах. Скорость построения дерева на локальной машине составляет примерно 2000 действий в секунду, а на облаке Heroku с подпиской «FREE» около 700 действий в секунду. Чем больше вычислительных ресурсов предоставляет платформа, тем больше действий боты смогут решить за отведённые им 3 секунды. Но даже если не смогут, для игрока это останется незаметно, так как бот всё равно сделает ход, просто, возможно, не самый лучший.
Итак, я смог решить поставленную задачу с помощью дерева решений. Давайте попробуем разобраться в преимуществах и недостатках такого подхода.
Преимущества:
Недостатки:
Конечно, отсутствие обучаемости весьма меня огорчает. Однако у меня есть идея по улучшению ИИ с использованием дерева решений в совокупности с нейронной сетью. В данный момент в функции оценки ситуации присутствуют некие константные значения, определяющие количество очков за те или иные свойства игровой ситуации. Например, начисление очков за количество единиц здоровья игрока:
Число 110, честно говоря, взялось «с потолка», оно примерно сбалансировано с другими константами, но никто не запрещает нам поменять его и посмотреть, как изменится поведение бота. Собрав все константы из функции принятия решений мы получим её «геном». Далее можно провести ряд экспериментов над различными «геномами» и найти тот, который выигрывает в большинстве боёв или вообще автоматизировать отбор лучших «геномов» по итогам боёв с реальными игроками. Но это будет уже совсем другая история.
Огромное спасибо за то, что осилили эти статьи. Надеюсь мой опыт окажется полезен для начинающих разработчиков игр, которые хотят привнести искусственный интеллект в свои проекты.
P.S. Буду рад всем комментариям и разъяснениям по статье. Заранее извиняюсь, если я неправильно оперирую терминами машинного обучения и вообще несу ересь. Я только учусь, будьте снисходительны.
Не так давно я поделился с вами своим опытом применения нейронной сети для для решения задачи выбора действия ботом. Чтобы подробнее узнать о сути задачи, пожалуйста, ознакомьтесь с первой частью статьи.
А я перейду к рассказу о следующем этапе работы!
Дерево решений
После неудачного (но весьма полезного) опыта работы с нейронной сетью я стал изучать деревья решений и теорию игр. По ходу изучения вопроса у меня возникало множество идей и концепций, но я остановился на следующей:
- У бота есть уже известный набор действий (узлов) на самом первом уровне дерева. Это те действия, среди которых бот в дальнейшем выберет самое наилучшее для текущей игровой ситуации.
- Бот делает «симуляцию» каждого действия, т.е. пытается совершить его «в уме». Результатом такого действия будет изменение игровой ситуации, иными словами переход среды в другое состояние.
- Новое состояние передаётся в функцию оценки ситуации, результатом которой является некое значение — score действия.
- После подсчёта score бот формирует список действий, которые можно совершить уже из новой виртуальной ситуации. Далее мы рекурсивно повторяем пункты 2 и 3 до тех пор, пока бот может сделать что-то кроме завершения хода.
- Когда подсчитаны очки (score) для всех действий на одном уровне дерева, максимальный score возвращается на родительский уровень дерева и складывается со значением score того действия, которое и породило дочерний список действий. Таким образом значения score как бы «всплывают» от крайних ветвей дерева к корням.
- Когда проход по дереву будет закончен, каждое действие, которое бот может сделать в данный момент будет иметь показатель score. Теперь нам остаётся только выбрать действие с максимальным значением score и применить его.
Ниже приведена рекурсивная функция описывающая данный алгоритм:
Много кода
function buildActionBranch (situation) {
var actionList = createActionList(situation);
/* функция createActionList находит все действия,
которые можно совершить в данной ситуации
и делает для них симуляцию с подсчётом очков.
Каждый элемент массива actionList будет
содержать информацию о той ситуации к которой
приведёт его применение (newSituation). */
for(var i = 0; i < actionList.length; i++){
if(actionList[i].type !== "endTurn") {
/* Если действие может привести к новой ситуации,
тогда нужно строить дерево дальше */
actionList[i].branch = buildActionBranch(actionList[i].newSituation);
/* Значение selfScore - это очки непосредственно
от применения данного действия,
а поле score содержит не только своё значение,
но и суммы очков всех лучших действий
от дочерних уровней дерева */
actionList[i].score = actionList[i].selfScore + actionList[i].branch[0].score;
/* actionList[i].branch[0] - это действие с максимальным
показателем score на дочернем уровне */
}
else {
actionList[i].score = actionList[i].selfScore;
}
}
/* сортируем действия по значению score с убыванием */
actionList.sort(function (a, b) {
if (a.score <= b.score) {
return 1;
}
else if (a.score > b.score) {
return -1;
}
});
/* массив actionList станет значением поля branch
для родительского действия, которое привело к этой ситуации */
return actionList;
}
Это только схематичное представление рекурсивной функции, на самом деле в построении дерева есть нюансы, о которых я расскажу чуть позже. Также я реализовал функцию для записи данных о дереве решений в файл, чтобы потом можно было наглядно посмотреть на то, как оно выглядит.
Дерево решений (размер JSON-файла: 4kb)
Это дерево построено для хода, где персонаж уже потратил немного энергии и на выбор ему предоставляется только 5 вариантов действий: 3 перемещения на соседние клетки, использование способности «Hit The Lights» и завершение хода. В каждом узле можно увидеть название действия, score — цифра сверху и selfScore — цифра снизу. Можно легко проследить, как формируется score на корневом уровне. Из-за того, что все массивы сортируются по score, оптимальное решение всегда сверху. Рассмотрим ещё одно дерево:
Дерево с раскрытым оптимальным вариантом решения (размер JSON-файла: 169kb)
К сожалению, показать вам полное дерево для этого случая я не смогу ввиду того, что оно займёт в высоту примерно 80000 пикселей. Пройдёмся по раскрытой ветке справа налево:
377 (endTurn) + 378 (move) + 373 (cast Defender Of The Faith) + 312 (cast Punishment Due) + 218 (move) = 1658
Для действия move значение score равно 1660. Разница в 2 очка из-за округления цифр до целых значений при выводе на экран. Посмотрим на значения selfScore для первого уровня дерева: действие move с selfScore равным 218 является не самым большим среди соседних узлов. Лучшим действием на этом уровне является использование «Defender Of The Faith» (selfScore = 244). Однако суммарный score (1660 против 1652) всё же больше у действия move. Получается, что без продумывания действий на весь ход использование способности в данной ситуации было бы не так оптимально.
Теперь давайте подробнее рассмотрим различные аспекты этого алгоритма.
Оценка ситуации
Для оценки ситуации используется следующая функция:
Много кода
function situationCost (activeChar, myTeam, enemyTeam, wallPositions){
var score = 0;
var effectScores = 0;
//Подсчёт очков для активного персонажа
score += activeChar.curHealth / activeChar.maxHealth * 110;
score += activeChar.curMana / activeChar.maxMana * 55;
var positionWeights = arenaService.calculatePositionWeight(activeChar.position, activeChar, myTeam.characters, enemyTeam.characters, arenaService.getOptimalRange(activeChar), wallPositions);
score += positionWeights[0] * 250 + Math.random();
score += positionWeights[1] * 125 + Math.random();
for(var j = 0; j < activeChar.buffs.length; j++){
if(activeChar.buffs[j].score) {
effectScores = activeChar.buffs[j].score(activeChar, myTeam.characters, enemyTeam.characters, wallPositions);
score += this.calculateEffectScore(effectScores, activeChar.buffs[j].name);
}
}
for(j = 0; j < activeChar.debuffs.length; j++){
if(activeChar.debuffs[j].score) {
effectScores = activeChar.debuffs[j].score(activeChar, myTeam.characters, enemyTeam.characters, wallPositions);
score -= this.calculateEffectScore(effectScores, activeChar.debuffs[j].name);
}
}
//myTeam - союзники активного персонажа
for(var i = 0; i < myTeam.characters.length; i++){
if(myTeam.characters[i].id !== activeChar.id) {
var ally = myTeam.characters[i];
score += ally.curHealth / ally.maxHealth * 100;
score += ally.curMana / ally.maxMana * 50;
for(j = 0; j < ally.buffs.length; j++){
if(ally.buffs[j].score) {
effectScores = ally.buffs[j].score(ally, myTeam.characters, enemyTeam.characters, wallPositions);
score += this.calculateEffectScore(effectScores, ally.buffs[j].name);
}
}
for(j = 0; j < ally.debuffs.length; j++){
if(ally.debuffs[j].score) {
effectScores = ally.debuffs[j].score(ally, myTeam.characters, enemyTeam.characters, wallPositions);
score -= this.calculateEffectScore(effectScores, ally.debuffs[j].name);
}
}
}
}
//enemyTeam - противники
for(i = 0; i < enemyTeam.characters.length; i++){
var enemy = enemyTeam.characters[i];
score -= Math.exp(enemy.curHealth / enemy.maxHealth * 3) * 15 - 200;
score -= enemy.curMana / enemy.maxMana * 50;
for(j = 0; j < enemy.buffs.length; j++){
if(enemy.buffs[j].score) {
effectScores = enemy.buffs[j].score(enemy, enemyTeam.characters, myTeam.characters, wallPositions);
score -= this.calculateEffectScore(effectScores, enemy.buffs[j].name);
}
}
for(j = 0; j < enemy.debuffs.length; j++){
if(enemy.debuffs[j].score) {
effectScores = enemy.debuffs[j].score(enemy, enemyTeam.characters, myTeam.characters, wallPositions);
score += this.calculateEffectScore(effectScores, enemy.debuffs[j].name);
}
}
}
return score;
}
Этот метод пробегается по всем персонажам, участвующим в битве и начисляет определённое количество очков за различные параметры:
- Здоровье. Чем больше процентный показатель здоровья союзников, тем больше очков. Причём зависимость линейная:
score += activeChar.curHealth / activeChar.maxHealth * 110;
А вот при оценке здоровья персонажей противника начисление очков ведётся по такой формуле:
score -= Math.exp(enemy.curHealth / enemy.maxHealth * 3) * 15 - 200;
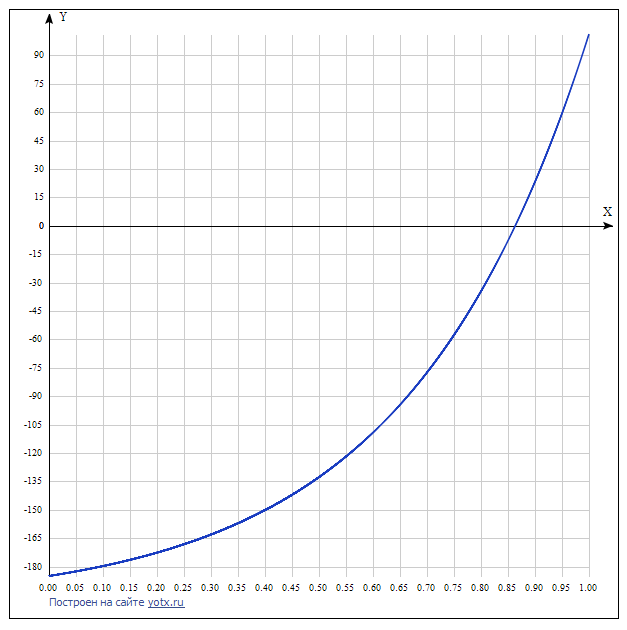
График вышепредставленной функции в интервале от 0 до 1 по оси текущего здоровья
При полном здоровье противников из общего числа очков вычитаются примерно такие же значения, какие прибавляются для союзников. Однако чем ниже здоровье конкретного персонажа, тем больше очков наберёт эта ситуация. При низком здоровье очки будут уже не вычитаться, а прибавляться. Это сделано для того, чтобы боты сосредотачивали усилия на уничтожении одной цели, вместо «размазывания» урона по вражеской команде. - Мана (ресурс для применения способностей). Тут уже без сложных функций, всё линейно как для союзников, так и для противников.
- Позиция. Я уже вскользь упоминал об оценке позиции персонажа на поле боя.
Она состоит из двух частей: наступающая и оборонительная. Лучшая наступающая позиция — это 3 персонажа противника в пределах видимости и на оптимальной дистанции для атаки. Лучшая оборонительная позиция — это 2 союзника в пределах видимости и на оптимальной дистанции для применения способностей поддержки. Очки за позиционирование начисляются только для активного персонажа, так как изменение позиций других персонажей всё равно повлияет на значение соответствующих показателей для активного. - Эффекты.Самая сложная часть функции оценки. Боту необходимо определить,
насколько один эффект, наложенный на персонажа важнее другого. Для этого у каждого эффекта существует функция score. Например, положительный эффект (бафф)
«Cauterization» постепенно восстанавливает здоровье персонажу, но сжигает его ману. Для данного эффекта функция score выглядит следующим образом:
Много кодаscore: function(owner, myTeam, enemyTeam, walls) { var buffer = {}; /* buffer - персонаж, который применил данный эффект */ for (var i = 0; i < myTeam.length; i++) { if (myTeam[i].id === this.casterId) buffer = myTeam[i]; } /* Вычисляем количество восстанавливаемого здоровья */ var heal = (this.variant * 80) * (1 + buffer.spellPower); /* Корректируем размер исцеления с учётом характеристик того, кто его применил */ heal = arenaService.calculateExpectedHeal(heal, buffer); /* определяем ценность позиции обладателя эффекта */ var positionWeights = arenaService.calculatePositionWeight(owner.position, owner, myTeam, enemyTeam, arenaService.getOptimalRange(owner), walls); return { effectScore: heal / 10, leftScore: this.left * 5, offensivePositionScore: 0, defensivePositionScore: - positionWeights[1] * 25, healthScore: - owner.curHealth / owner.maxHealth * 25, manaScore: owner.curMana / owner.maxMana * 15 }; }
Итак, функция score для эффекта возвращает объект с 6 свойствами:
- effectScore. Модификатор численных показателей самого эффекта: размер нанесённого урона, полученного исцеления, увеличение или уменьшение характеристик и т.д.
- leftScore. Модификатор времени действия эффекта.
- offensivePositionScore. Модификатор атакующей позиции.
- defensivePositionScore. Модификатор оборонительной позиции.
- healthScore. Модификатор количества здоровья обладателя эффекта.
- manaScore. Модификатор количества маны обладателя эффекта.
В функции оценки ситуации все эти модификаторы суммируются. Эта сумма и будет показателем «качества» данного эффекта.
По всем этим модификаторам об эффекте «Cauterization» можно сделать следующие выводы:
- Чем больше здоровья он восстановит, тем выше сумма.
- Чем больше он будет держаться на персонаже, тем выше сумма.
- Расположение противников никак не влияет на сумму.
- Чем дальше мы от союзников, тем выше сумма. Т.к. рассчитывать не на кого и лучше перестраховаться.
- Чем меньше здоровья осталось у персонажа, тем выше сумма.
- Чем больше маны осталось у персонажа, тем выше сумма. Ведь мы не хотим, чтобы этот эффект совсем оставил нас без маны, если её и так мало.
Симуляция действий
Для того, чтобы оценить результат выполнения действия бот:
- Полностью копирует состояние среды, чтобы все его дальнейшие действия не привели к изменению оригинального состояния
- Совершает симуляцию действия (перемещения или использования способности)
- Оценивает новое состояние среды с помощью функции оценки
К копированию мы вернёмся чуть позже, а пока рассмотрим подробнее, что же из себя представляет симуляция на примере одной из самых простых по механике способностей в игре — «Die By The Sword».
У каждой способности в игре есть функция cast, которая наносит урон, исцеляет, применяет эффекты и т.д. Давайте посмотрим на функцию cast для «Die By The Sword»:
Много кода
cast : function (caster, target, myTeam, enemyTeam, walls) {
/* Сперва потратим ресурсы на применение способности */
caster.spendEnergy(this.energyCost());
caster.spendMana(this.manaCost());
/* Установим, что теперь способность использована
и нужно время на её восстановление */
this.cd = this.cooldown();
/* Проверка попадания по противнику */
if(caster.checkHit()){
/* Урон от способности определяется случайным образом
в интервале от минимального до максимального */
var physDamage = randomService.randomInt(caster.minDamage *
(1 + this.variant * 0.35), caster.maxDamage * (1 + this.variant * 0.35));
/* Проверка критического попадания по противнику */
var critical = caster.checkCrit();
if(critical){
physDamage = caster.applyCrit(physDamage);
}
/* Снижаем урон от способности с учётом защиты цели */
physDamage = target.applyResistance(physDamage, false);
/* Записываем в специальное свойство название звука,
который потом проиграется на клиенте */
caster.soundBuffer.push(this.name);
/* Цель получает рассчитанное количество повреждений physDamage */
target.takeDamage(physDamage, caster, {name: this.name, icon: this.icon(), role: this.role()}, true, true, critical, myTeam, enemyTeam);
}
else {
/* Некоторые эффекты могут спадать после промаха,
поэтому выполним эту функцию */
caster.afterMiss(target.charName, {name: this.name, icon: this.icon(), role: this.role()}, myTeam, enemyTeam);
}
/* Некоторые эффекты могут спадать после применения способностей,
поэтому выполним эту функцию */
caster.afterCast(this.name, myTeam, enemyTeam);
}
Из функции видно, что внутри этой функции есть как минимум 3 операции случайного характера (определение урона, определение попадания, определение критического удара), а также утилитарные методы вроде добавления звуков для воспроизведения на клиенте. Естественно, когда речь идёт о предсказании последствий, мы не можем воспользоваться этой функцией. Поэтому у каждой способности помимо функции cast есть ещё и castSimulation:
/* Сперва потратим ресурсы на применение способности */
caster.spendEnergy(this.energyCost());
caster.spendMana(this.manaCost());
/* Установим, что теперь способность использована
и нужно время на её восстановление */
this.cd = this.cooldown();
/* Теперь наносимый урон - это среднее арифметическое
между минимальным и максимальным значениями */
var physDamage = (caster.minDamage * (1 + this.variant * 0.35) + caster.maxDamage * (1 + this.variant * 0.35)) / 2;
/* Расчёт математического ожидания для шанса
попадания и шанса нанести критический урон */
physDamage = caster.hitChance * ((1 - caster.critChance) * physDamage + caster.critChance * (1.5 + caster.critChance) * physDamage);
physDamage = target.applyResistance(physDamage, false);
/* Следующие две функции также были "облегчены" для симуляции */
target.takeDamageSimulation(physDamage, caster, true, true, myTeam, enemyTeam);
caster.afterCastSimulation(this.name);
Для симуляции действий передвижения используется тот же метод — просто отрезаем ненужное и заменяем случайные методы на математическое ожидание.
Оптимизация
После того, как базовый алгоритм был построен, я впервые увидел, что боты обдумывают ход и совершают действия. Было очень классно наблюдать, как они сами решают, как им поступить в той или иной ситуации. Но тут неожиданно всплыла следующая проблема — иногда они думают оооооочень долго. Настолько долго, что Socket.io падает, потому что событие ping'а не происходит из-за занятости Node.js расчётом дерева. Пришло время заняться оптимизацией.
1) Освобождение потока
Первое, что пришло мне в голову — это сделать построение дерева асинхронным. При помощи библиотеки async и метода eachOf я преобразовал все проходы по спискам действий в асинхронные, а все возвраты значений в callback'и. Но стало только хуже :( Дерево строилось медленнее раза в полтора, а отлаживать асинхронное построение глубокого дерева — это тот ещё квест…
Затем я стал экспериментировать с process.nextTick, я пробовал оборачивать в него разные куски кода, но никакого эффекта так и не заметил.
В итоге я пришёл к следующей схеме:
- Для самого первого списка действий мы асинхронно запускаем построение веток.
- Для всех вложенных веток построение дерева будет синхронным.
Много кода
/* Данная функция - это "точка входа" в построение дерева решений */
function buildActionBranchAsync(myTeam, enemyTeam, activeCharId, wallPositions, cb){
var self = this;
/* Реальный список действий, доступных персонажу */
var actionList = self.createActionList(myTeam, enemyTeam, activeCharId, wallPositions);
async.eachOf(actionList, function(actionInList, index, cb){
/* Обёртка для освобождения потока до следующей итерации */
process.nextTick(function() {
if(actionInList.type != "endTurn" ) {
/* Ветви строятся уже рекурсивно и синхронно */
actionInList.branch = self.buildActionBranchSync(actionInList.myTeamState, actionInList.enemyTeamState, actionInList.activeCharId, wallPositions);
if(actionInList.branch && actionInList.branch[0]) {
actionInList.score = actionInList.selfScore + actionInList.branch[0].score;
}
else {
actionInList.score = actionInList.selfScore;
}
}
else {
actionInList.score = actionInList.selfScore;
}
cb(null, null);
});
}, function(err, temp){
if(err){
return console.error(err);
}
actionList.sort(function (a, b) {
if (a.score <= b.score) {
return 1;
}
else if (a.score > b.score) {
return -1;
}
});
cb(actionList);
})
}
Данное решение оказалось оптимальным из рассмотренных мной, однако всё равно является блокирующим. Сокет продолжает падать при долгом «обдумывании» хода. Если у кого-то есть идеи касательно изменения архитектуры построения дерева и использования process.nextTick, я буду рад помощи)
2) Освобождение памяти
Другая проблема заключалась в том, что иногда бот думал настолько долго, что я получал ошибку вида JavaScript heap out of memory. Ясно, что происходит переполнение оперативной памяти, так как дерево решений просто не умещается в отведённые по умолчанию 512 Мб места в памяти. Можно, конечно, расширить отведённое место, но это всё равно неправильно, лучше постараться уложиться в минимум. Слабым местом моей архитектуры было то, что мне приходилось хранить состояния всех боевых ситуаций по мере построения дерева. А так как объекты перед симуляцией полностью копируются, память просто захлёбывается. Первое, что я сделал — это уменьшил вес объектов перед построением дерева. Так, например есть ряд свойств у объекта Character, которые совершенно не участвуют в симуляции: инвентарь, массив сообщений в лог, массив звуков для проигрывания, цвета рамок для персонажей и т.д. Теперь перед построением дерева происходит облегчение объектов персонажей следующим образом:
Много кода
function lightWeightTeamBeforeSimulation(team){
delete team.teamName;
delete team.lead;
for(var i = 0; i < team.characters.length; i++){
var char = team.characters[i];
delete char.battleTextBuffer;
delete char.logBuffer;
delete char.soundBuffer;
delete char.battleColor;
delete char.charName;
delete char.gender;
delete char.isBot;
delete char.portrait;
delete char.race;
delete char.role;
delete char.state;
delete char.calcParamsByPoint;
delete char.calcItem;
delete char.updateMods;
delete char.removeRandomBuff;
delete char.removeRandomDebuff;
delete char.removeAllDebuffs;
delete char.removeRandomDOT;
delete char.stealRandomBuff;
delete char.afterDealingDamage;
delete char.afterDamageTaken;
delete char.afterMiss;
delete char.removeImmobilization;
delete char.afterCast;
delete char.getSize;
for(var j = 0; j < char.abilities.length; j++){
var ability = char.abilities[j];
delete ability.cast;
delete ability.icon;
delete ability.role;
}
for(j = 0; j < char.buffs.length; j++){
var effect = char.buffs[j];
delete effect.icon;
delete effect.role;
delete effect.apply;
}
for(j = 0; j < char.debuffs.length; j++){
var effect = char.debuffs[j];
delete effect.icon;
delete effect.role;
delete effect.apply;
}
}
return team;
}
Таким образом мне удалось снизить размер объекта каждого персонажа более чем на 40%. Но даже это не спасло меня от переполнения памяти. Я обсудил проблему с коллегой по работе и мы выяснили, что хранить ветку в памяти не имеет смысла после того, как она вернёт нам список действий. Ведь нас интересует лишь самое удачное решение, а остальные без надобности. Теперь сразу после возвращения результата, ветка просто удаляется:
Много кода
function buildActionBranchSync: function(myTeam, enemyTeam, activeCharId, wallPositions){
var actionList = this.createActionList(myTeam, enemyTeam, activeCharId, wallPositions);
for(var z = 0; z < actionList.length; z++){
/* ... */
actionList[z].branch = this.buildActionBranchSync(actionList[z].myTeamState, actionList[z].enemyTeamState, actionList[z].activeCharId, wallPositions);
actionList[z].score = actionList[z].selfScore + actionList[z].branch[0].score;
delete actionList[z].branch; /* Ветка больше не нужна */
/* ... */
}
/* sort actionList */
return actionList;
}
После этого о переполнении памяти я забыл навсегда.
3) Сокращение списка действий
Несмотря на все предыдущие оптимизации обдумывание хода всё равно порой занимало порядка 30 секунд :( Следующим шагом стало добавление дополнительной функции usageLogic для каждой способности, которая описывала приемлемость её использования в зависимости от ситуации. Например, нет смысла кидать исцеление на персонажа с максимальным здоровьем, поэтому перед построением списка действий с участием такой способности выполним следующую проверку:
usageLogic: function(target) {
/* Текущее здоровье цели ниже 60% */
return target.curHealth < target.maxHealth * 0.6;
}
Таким образом и боты стали умнее и количество действий для выбора сократилось в разы. Но тем не менее, была одна способность, которая плодила большое количество действий:
Способность «Speed Of Light» позволяет тепепортировать персонажа на позицию в радиусе 6 клеток вокруг него.
Получается, что в худшем случае эта способность генерирует 35 действий. Дерево решений здесь получается очень широким. Решение пришло само собой после того, как я закончил реализацию функций usageLogic для способностей. Ведь исключить неудачные точки для перемещения тоже можно. Выше я уже упоминал о весах позиций и функции calculatePositionWeight. Так вот, на этапе построения списка клеток, доступных для перемещения можно оценить выгодность каждой и исключить самые слабые позиции:
Много кода
/* ... */
var bestMovePoints = [];
/* находим массив всех точек, доступных для перемещения */
var movePoints = arenaService.findMovePoints(myTeam, enemyTeam, activeChar, false, wallPositions);
/* Для каждой точки посчитаем вес и составим новый массив */
for(var i = 0; i < movePoints.length; i++){
var weights = arenaService.calculatePositionWeight(movePoints[i], activeChar, myTeam.characters, enemyTeam.characters, arenaService.getOptimalRange(activeChar), wallPositions);
/* вес позиции с точки зрения нападения (weights[0]) считается
выгоднее, чем вес позиции с точки зрения защиты (weights[1]) */
bestMovePoints.push({
point: movePoints[i],
weightScore: weights[0] * 6 + weights[1] * 4
})
}
/* Сортируем массив по убыванию весов */
bestMovePoints.sort(function (a, b) {
if (a.weightScore <= b.weightScore) {
return 1;
}
else if (a.weightScore > b.weightScore) {
return -1;
}
});
/* И используем только 3 наилучших */
bestMovePoints = bestMovePoints.slice(0, 3);
for(j = 0; j < bestMovePoints.length; j++){
/* Симуляция */
}
Такой подход я применил как к обычному перемещению, так и к способностям, которые перемещают персонажа («Speed Of Light»).
4) Порог обдумывания
Даже с такой оптимизацией бывают случаи, когда обдумывание затягивается.
Способность «I don't wanna Stop» восстанавливает 850 единиц энергии.
Возможность применения такой способности увеличивает время обдумывания в 2, а то и в 3 раза, т.к. после любого действия можно почти полностью восстановить энергию и начать думать над ходом заново.
Во избежание подобных «долгих» раздумий я ввёл пороговое время построения дерева. В данный момент оно составляет 3 секунды. Перед построением новой ветки с вариантами действий я сверяюсь с этим временем. Если оно превышено, значит строить дерево дальше нельзя и бот просто выбирает действие с учётом того, что он уже насчитал. Таким образом я решил ещё и проблему производительности на разных платформах. Скорость построения дерева на локальной машине составляет примерно 2000 действий в секунду, а на облаке Heroku с подпиской «FREE» около 700 действий в секунду. Чем больше вычислительных ресурсов предоставляет платформа, тем больше действий боты смогут решить за отведённые им 3 секунды. Но даже если не смогут, для игрока это останется незаметно, так как бот всё равно сделает ход, просто, возможно, не самый лучший.
Заключение
Итак, я смог решить поставленную задачу с помощью дерева решений. Давайте попробуем разобраться в преимуществах и недостатках такого подхода.
Преимущества:
- Можно отследить весь «ход мыслей» бота и найти ошибки
- Тонкая настройка каждой способности, эффекта и очков оценки ситуации позволяют контролировать баланс боя
- Не нужно осуществлять сбор данных для тренировочной выборки, а также сохранять выборку в базе данных
- Не нужно хранить модель нейронной сети в базе
- Легко добавлять новые способности без необходимости адаптации ИИ к ним
Недостатки:
- Для каждого действия дерево нужно строить с нуля, что весьма затратно для ресурсов сервера
- Боты не обучаются, они будут раз за разом повторять одни и те же ошибки
- Нужно заниматься отладкой и настройкой внутреннего алгоритма принятия решений
Конечно, отсутствие обучаемости весьма меня огорчает. Однако у меня есть идея по улучшению ИИ с использованием дерева решений в совокупности с нейронной сетью. В данный момент в функции оценки ситуации присутствуют некие константные значения, определяющие количество очков за те или иные свойства игровой ситуации. Например, начисление очков за количество единиц здоровья игрока:
score += activeChar.curHealth / activeChar.maxHealth * 110;
Число 110, честно говоря, взялось «с потолка», оно примерно сбалансировано с другими константами, но никто не запрещает нам поменять его и посмотреть, как изменится поведение бота. Собрав все константы из функции принятия решений мы получим её «геном». Далее можно провести ряд экспериментов над различными «геномами» и найти тот, который выигрывает в большинстве боёв или вообще автоматизировать отбор лучших «геномов» по итогам боёв с реальными игроками. Но это будет уже совсем другая история.
Огромное спасибо за то, что осилили эти статьи. Надеюсь мой опыт окажется полезен для начинающих разработчиков игр, которые хотят привнести искусственный интеллект в свои проекты.
P.S. Буду рад всем комментариям и разъяснениям по статье. Заранее извиняюсь, если я неправильно оперирую терминами машинного обучения и вообще несу ересь. Я только учусь, будьте снисходительны.
