Что такое CI
Continuous Integration — это практика разработки программного обеспечения, которая заключается в слиянии рабочих копий в общую основную ветвь разработки несколько раз в день и выполнении частых автоматизированных сборок проекта для скорейшего выявления потенциальных дефектов и решения интеграционных проблем. В обычном проекте, где над разными частями системы разработчики трудятся независимо, стадия интеграции является заключительной. Она может непредсказуемо задержать окончание работ. Переход к непрерывной интеграции позволяет снизить трудоёмкость интеграции и сделать её более предсказуемой за счет раннего обнаружения и устранения ошибок и противоречий. Основным преимуществом является сокращение стоимости исправления дефекта, за счёт раннего его выявления.
Если вы не знаете как настроить CI в своем проекте, я приглашаю вас "под кат"
Всем любителям стилей и нотаций, я не всегда соблюдаю нотации и требования в силу личных обстоятельств и причин, которые я не хочу обсуждать. Я знаю, что я отступаю от канонов React и JS сообществ, поэтому сразу прошу меня за это извинить и считать данные вольности придурью автора. Моя цель поделиться опытом и рассказать людям насколько просто сегодня настроить CI, я не имею никакого отношения к Тревису или Хероку, более того, мне не нравится Heroku, я использовал его только из-за простоты настройки для новичков. Дальше TLDR.
Зачем нам это нужно
В процессе работы мне часто приходится обновлять сервисы и разворачивать их на конечные сервера. Когда проектов было мало, это не составляло особых проблем, т.к. релизы были редкими, развертывания выполнялись довольно редко. Тесты выполнялись вручную. Со временем, проектов и задач становилось больше, и выполнение однотипных задач стало занимать больше времени. Рассмотрим классический процесс решения задачи, подходящий для большинства компаний:
- Берем задачу из списка/Получаем от начальства
- Создаем новую ветку в git и открываем пул реквест
- Пишем код
- Лично или с помощью коллеги выполняем код-ревью (code review — обзор/проверку кода)
- Запускаем тесты
- Сливаем ветку в мастер
- Выполняем сборку проекта
- Публикуем новую сборку
Этот процесс повторяется для каждой задачи, если вы 10 дней писали код и на сборку/развертывание потратили 1 час, то это выглядит разумно и не трудозатратно. Но что если вы поправили мелкий баг за 1 минуту, но на развертывание потратите тот же час? В этой ситуации это выглядит довольно расточительно. А если вам нужно выполнять в день 10 — 20 багфиксов (bugfix, исправление ошибки)?
Первый путь, укрупнять пул реквесты и делать объединение в мастер как можно реже. Второй путь настроить CI чтобы процесс тестирования/построения/развертывания выполнялся автоматически. Делать ревью больших пул реквестов неудобно, поэтому мы пойдем вторым путем.
Что мы будем использовать для решения задачи
Когда я столкнулся с этой проблемой еще в далеком 2008м году, на рынке было очень мало решений, тогда для автоматизации этих процессов приходилось разворачивать свои сервера, следить за правильностью версий библиотек, писать скрипты для сборки проекта, писать скрипты для выгрузки проекта на сервера и много других трудоемких операций. Сейчас все проще, большая часть задач элементарно поддается автоматизации, на рынке множество облачных сервисов для их решения. После продолжительных поисков, я решил остановиться на open source проекте travis-ci.org. "Трэвис" бесплатен для open source проектов, имеет платный вариант для коммерческого использования. Он понравился мне за простоту настройки и использования. Тем не менее, чтобы это не выглядело рекламой, я хочу отметить, что на рынке появляется все больше достойных сервисов, например: CircleCI, Codeship.
Мы создадим React приложение, для тестирования будем использовать Jest, для развертывания Heroku. Предполагается, что читатель обладает базовыми знаниями в программировании, базовым английским, базовым интеллектом, имеет настроенную среду node.js, установленный yarn, имеет учетные записи на github.com, heroku.com, travis-ci.org или в состоянии создать их в процессе прохождения данного туториала.
Создаем приложение
Т.к. статья ориентирована на молодых разработчиков, мы будем использовать генератор
React приложений — create-react-app. Установим его глобально:
$ yarn global add create-react-appПосле установки создадим наше приложение, к примеру мы будем писать веб-интерфейс для управления производственной линией.
$ create-react-app factory_line_managerПосле создания проекта и скачивания всех библиотек, зайдем в папку проекта и запустим его.
cd factory_line_manager
$ yarn startВ браузере должна открыться страница нашего приложения. По умолчанию, если порт 3000 свободен — localhost:3000
По умолчанию create-react-app создает нам проект with no build configuration, что означает — без конфигураций. Генератор создаст для нас стандартный файл конфигурации и нам не нужно будет настраивать webpack, jest, babel и прочие библиотеки. В 95% случаев эти настройки будут выдавать более качественный и чистый код, чем новичок сможет сконфигурировать самостоятельно. Поэтому, я настоятельно рекомендую оставлять конфигурацию как есть, до тех пор пока вы не поймете, как это работает.
Сделайте копию проекта и выполните следующую команду в консоли
$ yarn ejectПодтвердите операцию. Генератор извлечет конфигурационные файлы в папку проекта, где вы сможете изучить их детально.
Подключаем GIT
Для тех кто знаком с гитом — создайте новый репозиторий, подключите к нему наш проект и переходите к следующей главе. Для остальных — пройдем пошагово. У Вас должен быть настроен доступ по ssh ключу, если Вы не сделали этого ранее, сейчас самое время — линк.
Зайдите на github и создайте новый репозиторий. Я создал следующий репозиторий habrahabr_topic_352282.
Находясь в папке проекта. Инициализируем гит:
$ git initДобавляем все файлы нашего проекта в гит
$ git add .Создаем первый комит:
$ git commit -m "First commit"Подключаем локальную папку к Вашему репозиторию на гите. Будьте внимательны, замените evilosa — на свой профиль и habrahabr_topic_352282 — на имя созданного вами репозитория:
$ git remote add origin git@github.com:evilosa/habrahabr_topic_352282.gitЗаливаем наш проект на удаленный сервер гит:
$ git push -u origin masterПосле последней команды должна произойти магия и код выгрузится в наш репозиторий на гите.
Настраиваем CI
Заходим на сайт travis-ci.org и входим с учетной записью гитхаба (Sign in with Github). В появившемся окне авторизуем приложение через OAuth:

Нажимаем Authorize-CI и ждем пока тревис выполнит синхронизацию данных с нашей учетной записью на гитхабе. После завершения этого процесса вы должны увидеть что-то вроде этого:

Выбираем в списке нужный репозиторий, в моем случае это habrahabr_topic_352282, включаем для него тумблер и кликаем по наименования для перехода на страницу проекта.
Мы выполнили большую часть работы, теперь нам нужно создать конфигурационный файл для тревиса. Создадим в папке нашего проекта файл .travis.yml со следующим содержимым:
sudo: false
language: node_js
node_js:
- 9
branches:
only:
- masterДобавляем изменения в гит и выгружаем на сервер:
$ git add .
$ git commit -m "Add travis config"
$ git push -u origin masterНастройка первого этапа CI завершена. После выгрузки изменений в гит, тревис должен увидеть настройки и выполнить тестирование и сборку проекта:

В конце логов тревиса, вы должны увидеть статус успешного прохождения тестов:
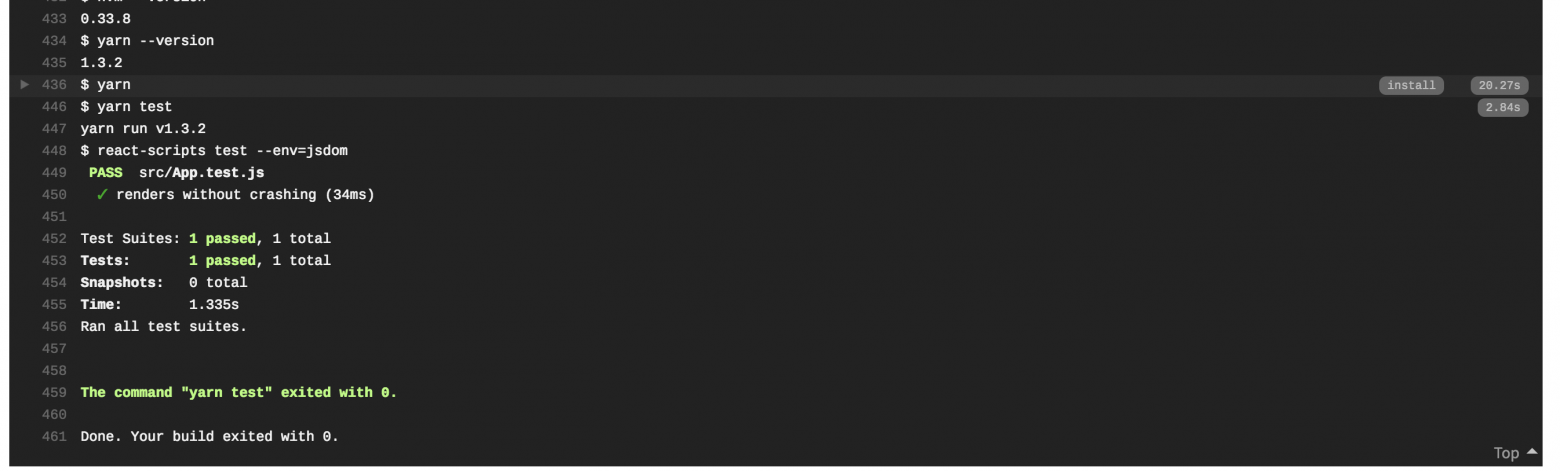
Теперь при каждом комите в мастер ветку у нас будет запускаться автоматическое построение и запуск тестов на тревисе. Уже неплохо. Двигаемся дальше. Следующий шаг — автоматическая публикация нашего проекта на Heroku.
Зайдите на Heroku, создайте учетную запись и авторизуйтесь. Обратите внимание, что почта из домена mail.ru у них заблокирована, используйте сторонние сервисы.
Если Вы новый пользователь то увидите примерно следующее:

Создайте новое приложение нажав кнопку Create New App. Введите имя Вашего приложения и регион размещения:

Обратите внимание имя моего приложения на Heroku, не соответствует имени репозитория.
Вернемся в наш файл конфигурации тревиса .travis.yml. Добавьте в него следующий код подставив свои значения:
deploy:
provider: heroku
app: "Имя вашего приложения в Heroku"
api_key:
secure: "Ваш ключ API Heroku"Перейдите в настройки профиля, для этого кликните по иконке профиля и выберите пункт "Account settings". Найдите пункт API key:

После нажатия на кнопку Reveal у Вас появится возможность скопировать ключ.
Добавляем изменения в гит и выгружаем на сервер:
$ git add .
$ git commit -m "Add Heroku deploy to travis"
$ git push -u origin masterПроверяем логи тревиса. Если все сделано правильно, то мы должны увидеть следующее сообщение:

Переходим по ссылке вида https://<Имя вашего приложения на Heroku>.herokuapp.com/ и видим наше React приложение.
Если при построении вы увидели вот такую ошибку:

Значит произошло обновление какого-либо пакета входящего в состав генератора create-react-app.
Обновите список пакетов локально и выгрузите изменения в мастер следующими командами:
$ yarn install
$ git add .
$ git commit -m "Update yarn.lock"
$ git push -u origin masterНаш CI готов, можно испытывать его боем.
Что делать дальше
Эта статья призвана ознакомить пользователя с основами CI и служит отправной точкой для дальнейших экспериментов. Из явных минусов представленного подхода — Ваш API ключ Heroku будет лежать в открытом репозитории. После прохождения туториала, я настоятельно рекомендую Вам его обновить. Для реальных проектов ключи определяются через encrypted variables, подробнее Вы можете ознакомиться с этим здесь.
Если Вам нужно публиковать несколько версий приложения, к примеру — production, staging. То вы можете сделать несколько веток в гите и управляя этим процессом, публиковать разные ветки на разные приложения в Heroku, пример:
deploy:
provider: heroku
app:
master: my-staging-application
production: my-production-application
api_key:
secure: "Ваш ключ API для Heroku"Теперь вы можете меняя конфигурацию, модернизируя тесты — экспериментировать с проектом и смотреть к чему все это приводит. Попробуйте написать тест который завалит приложение. Все функции и нюансы настройки сервисов подробно описаны в документации.
Бонус
Давайте еще, чтобы показать, что мы крутые прогеры, сделаем для нашего репозитория два баджа с указанием статуса сборки и процента покрытия нашего кода тестами — 

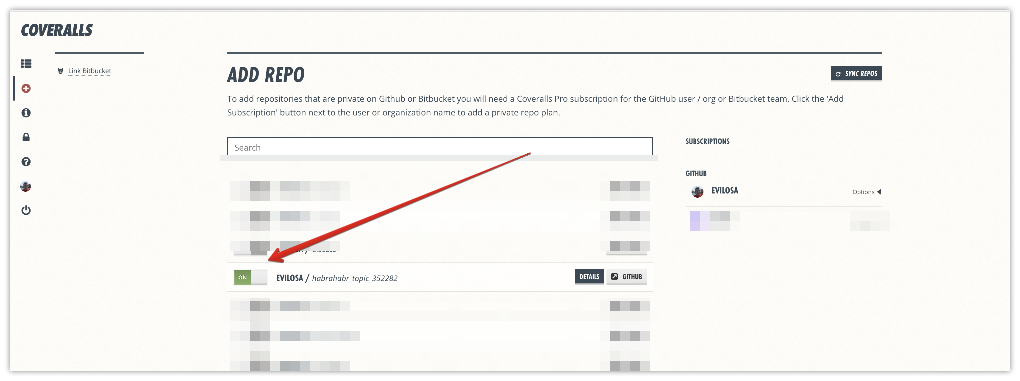
Зайдите и зарегистрируйтесь на coveralls.io с учетной записью github. После успешной OAuth авторизации, в меню слева нажмите Add repos. В появившемся списке переключите тумблер для нужного проекта:
В файл .travis.yml добавим следующий код:
after_success:
- cat ./coverage/lcov.info | ./node_modules/codecov.io/bin/codecov.io.js
- cat ./coverage/lcov.info | ./node_modules/coveralls/bin/coveralls.jsЗамените содержимое файла readme.md подставив свои значения в ссылки:
# Factory line manager
[![Travis][build-badge]][build]
[![Coveralls][coveralls-badge]][coveralls]
Awesome factory line manager!
[build-badge]: https://img.shields.io/travis/<Ваше имя на гите>/<Имя вашего проекта>/master.png?style=flat-square
[build]: https://travis-ci.org/<Ваше имя на гите>/<Имя вашего проекта>
[coveralls-badge]: https://img.shields.io/coveralls/<Ваше имя на гите>/<Имя вашего проекта>/master.png?style=flat-square
[coveralls]: https://coveralls.io/github/<Ваше имя на гитхабе>/<Имя вашего проекта>Добавьте каталог coverage в .gitignore
В проекте для тестов, по умолчанию добавим проверку покрытия кода тестами. Для этого в файле package.json поправьте код до следующего вида:
...
"scripts": {
"start": "react-scripts start",
"build": "react-scripts build",
"test": "react-scripts test --env=jsdom --coverage --collectCoverageFrom=src/**/*js --collectCoverageFrom=!src/registerServiceWorker.js",
...В данном конфиге мы добавляем запуск проверки покрытия нашего кода тестами. Это нужно для генерации файлов, необходимых для создания баджа. Мы исключаем файл src/registerServiceWorker из проверки, т.к. этот файл нами не обслуживается.
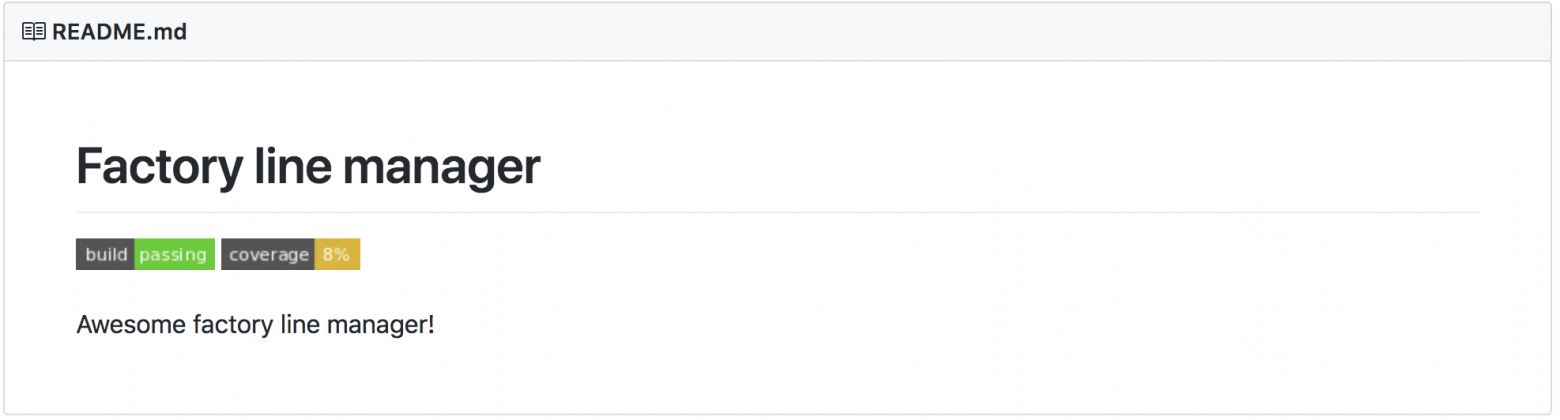
Установим нужные dev зависимости для проекта и выгрузим все на github:
$ yarn add codecov.io coveralls --dev
$ git add .
$ git commit -m "Add coverage"
$ git push -u origin masterРезультат после сборки проекта тревисом:
Заключение
Как видите, настроить полноценный CI при наличии знаний займет не более 10 минут, в сложных конфигах вы можете потратить часы, возможно дни и недели. Но сколько своего времени вы сэкономите автоматизировав этот процесс? Я думаю тут каждый решит для себя сам, нужно ему это или нет.
Надеюсь пост был Вам полезен, исходный код можно взять тут, если понравилось плюсуйте, если нет — люто минусуйте. Желаю успешного кодерства. Мир всем!
P.S. Я специально использовал разные имена в папке проекта, имени репозитория и имени приложения в Heroku. API ключ перегенерировал. Если кому интересно, в своем проде я добавляю в CI пайплайн промежуточный сервис для сборки Docker контейнеров и публикую готовые контейнеры в swarm кластер.
