Spot-инстансы — это по сути продажа свободных в данный момент ресурсов со отличной скидкой. При этом инстанс могут в любой момент выключить и забрать обратно. В статье я расскажу о особенностях и практике работы с этим предложением от AWS.
Стоимость использования spot-инстанса может меняться время от времени. Во время заказа вы делаете ставку(bid) — указываете максимальную цену, которую готовы платить за использование. Именно баланс ставок и свободных ресурсов формирует итоговую стоимость, которая при этом отличается в разных регионах и даже в availability zones региона.
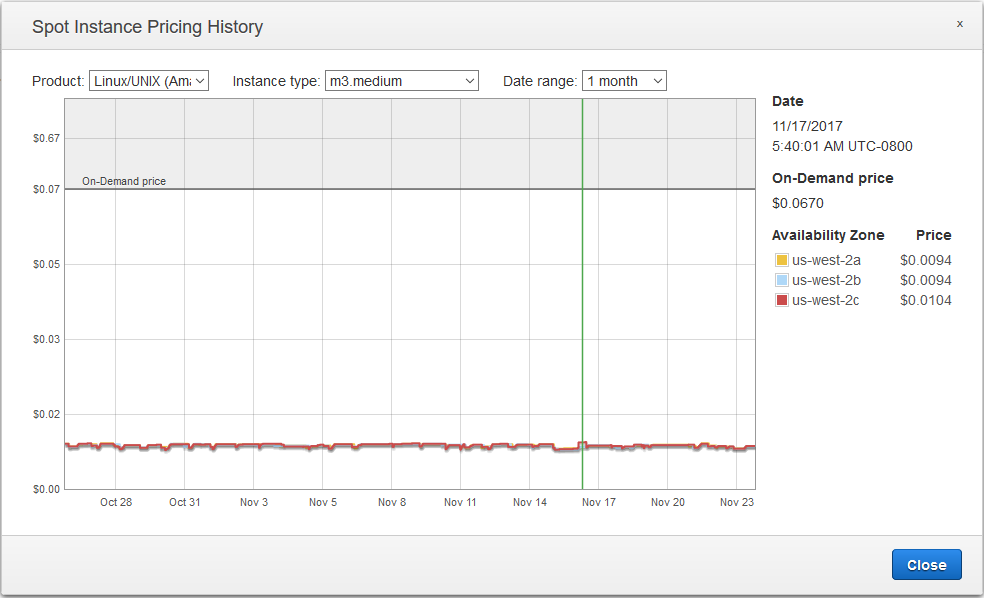
В определенный момент взвешенная цена может превысить цену обычного on-demand инстанса. Именно поэтому не стоит делать избыточные ставки — вам действительно могут продать инстанс по 1000$ за час. Не знаете, какую ставку сделать — указывайте цену on-demand инстанса (именно она используется по-умолчанию).
Жизненный цикл spot-инстанса
Итак, мы формируем запрос, а AWS выделяет нам инстансы. Как только Амазону понадобились выданные инстансы или цена превысила указанный нами лимит, запрос закрывается. Это значит, что наши инстансы будут terminated/hibernated.
Также запрос может быть закрыть из-за ошибки в запросе. И тут надо быть аккуратнее. Например, вы создали запрос и получили инстансы. А потом удалили ассоциированную IAM-роль. Ваш запрос закроется со статусом “error”. При этом инстансы будут остановлены.
И конечно же вы в любой момент можете отменить запрос, что так же приведет к остановке инстансов.
Сам запрос может быть:
- Одноразовым — как только у нас забрали инстансы, запрос закрывается
- Постоянным — инстансы нам возвращают после повторного включения.
- С гарантированным обслуживанием на 1-6 часов.
В итоге у нас есть две основные задачи для сервиса с желаемым 100% аптаймом:
- Формировать оптимальные spot-requests
- Обрабатывать события отключения инстанса
Средства
Одним из самых мощных средств работы со spot-запросами является spot fleet. Он позволяет динамически формировать запросы таким образом, чтобы удовлетворить заданные условия. Например, если инстансы подорожали в одной AvailabilityZone, то можно быстренько запустить такие же в другой. Также появляется такой замечательный фактор, как “вес” инстанса. Например, для выполнения задачи нам требуется 100 одноядерных ноды. Или 50 двухядерных. И это значит, на примере инстансов T2-типа, что мы можем использовать 100 small или 50 large или 25 xlarge. Именно оптимальное распределение и перераспределение минимизирует и стоимость, и вероятность того, что запрос будет неудовлетворен. Новсе же сохраняется вероятность того, что во всех AvailabilityZones не найдется нужного количества инстансов с нашими параметрами.
К счастью, AWS оставляет нам 2 мин между принятием решения об остановке и самим выключением. Именно а этот момент по ссылке начнет возвращаться таймер отключения:
http://169.254.169.254/latest/meta-data/spot/termination-timeПримерно так будет выглядеть простейший обработчик, который мы можем запускать в виде демона:
#!/usr/bin/env bash
while true
do
if [ -z $(curl -Is http://169.254.169.254/latest/meta-data/spot/termination-time | head -1 | grep 404 | cut -d \ -f 2) ]
then
echo “Instanсe is going to be terminated soon”
# Execute pre-shutdown stuff
break
else
# Spot instance is fine.
sleep 5
fi
doneНемного усложним задачу — наши инстансы подключены к Elastic Load Balancer (ELB). Можно воспользоваться демоном из сниппета выше и через API сообщать балансеру статус. Но есть более элегантный способ — проект SeeSpot. Вкратце, демон смотрит одновременно и в /spot/termination-time и, опционально, в healthcheck url вашего сервиса. Как только AWS соберется изъять инстанс, он отмечается как OutOfService в ELB и может опционально выполнить финальный CleanUP task.
Итак, мы разобрались, как правильно обрабатывать отключение. Осталось только научиться сохранять требуемую производительность системы, если у нас вдруг решили забрать инстансы. Здесь нам поможет проект autospotting. Идея следующая: мы создаем обычную autoscaling-группу, содержащую on-demand инстансы. Скрипт autospotting находит эти инстансы и по-одному подменяет их полностью соответствующими spot-инстансами(поиск происходит по тэгу). У autoscaling групп есть собственны Healthcheck’и. Как только один из ee членов не проходит проверку, группа пытается вернуть свой объем и создает “здоровый” инстанс исходного типа(а это был on-demand). Таким образом мы сможем переждать, например, скачек цены. Как только spot-requests снова начнут удовлетворяться, autospotting начнет постепенную замену. От себя добавлю, что проект сделан достаточно качественно, и имеет, в том числе, подходы для конфигурации с помощью terraform или cloudformation.
В заключении хотел бы порекомендовать по-возможности использовать spot-инстансы для stateless сервисов. Или же применять S3/EFS. Для конфигураций ECS необходимо подумать про tasks re-balancing.
