В этой статье я хочу поделиться своим личным опытом, связанным с правильной организацией кода (архитектурой). Правильная архитектура существенно упрощает долгосрочную поддержку.
Это очень философская тема, поэтому я не могу предложить ничего более, чем мой субъективный анализ и опыт.
Мой начальный опыт программиста был весьма безоблачным – я без лишних проблем клепал вебсайты-визитки. Писал код, как я это сейчас называю “в строчку” или “полотном”. На маленьких объемах и простых задачах все было хорошо.
Но я сменил работу, и пришлось разрабатывать один единственный вебсайт в течение 4-х лет. Естественно, сложность этого кода была несопоставима с визитками из моей прошлой работы. В какой-то момент проблемы просто посыпались на меня – количество регрессии зашкаливало. Было ощущение, что я просто хожу по кругу – пока чинил “здесь”, сломал что-то “там”. И поэтом это “здесь” и “там” банально менялось местами и круг повторялся.
У меня исчезла уверенность в том, что я контролирую ситуацию – при всем моем желании недопустить баги, они проскакивали. Все эти 4 года проект активно разрабатывался – мы улучшали уже существующий функционал, расширяли, достраивали его. Я видел и чувствовал, как удельная стоимость каждого нового рефакторинга/доработки растет – увеличивался общий объем кода, и соответственно увеличивались затраты на любую его правку. Банально, я вышел на порог, через который уже не мог переступить, продолжая писать код “в строчку”, без использования архитектуры. Но в тот момент, я этого еще не понимал.
Другим важным симптомом оказались книги и видео-уроки, которые я в то время читал/смотрел. Код с этих источников выглядел “глянцево” красивым, естественным и интуитивно понятным. Видя такую разницу между учебниками и реальной жизнью, моей первой реакцией была мысль, что это нормально – в жизни всегда сложнее, чем в теории, больше рутины и конкретики.
Тем не менее, продукт на работе нужно было расширять, улучшать, в общем, двигаться дальше. В тот же самый момент я начал активно участвовать в одном open source проекте. И в совокупности эти факторы вытолкнули меня на путь архитектурного мышления.
Один мой преподаватель в университете употребил фразу “нужно проектировать так, чтобы максимизировать количество объектов и минимизировать количество связей между ними”. Чем дольше я живу, тем больше с ним соглашаюсь. Если присмотреться к этой цитате, то видно, что эти 2 условия в какой-то мере взаимоисключающие – чем больше мы дробим какую-то систему на подсистемы, тем больше связей придется вводить между ними, чтобы “соединить” каждую из подсистем с остальными актерами. Найти оптимальный баланс между первым и вторым – это своего рода искусство, которым, как и прочими искусствами, можно овладеть через практику.
Сложная система дробится на подсистемы за счет интерфейсов. Для того, чтобы выделить из сложной системы какую-то подсистему, нужно определить интерфейс, который будет декларировать границы между первым и вторым. Представьте, у нас была сложная система, и вроде бы внутри нее осязаются некоторые подсистемы, но они “размазаны” по разным местам основной системы и четкий формат (интерфейс) взаимодействия между ними отсутствует:

Посчитаем, де факто, у нас 1 система и 0 связей. С минимизацией связей все отлично :) Но вот количество систем очень маленькое.
А теперь, кто-то проделал анализ кода, и четко выделил 2 подсистемы, определил интерфейсы, по которым ведется коммуникация. Это значит, что границы подсистем определены и схема стала следующей:
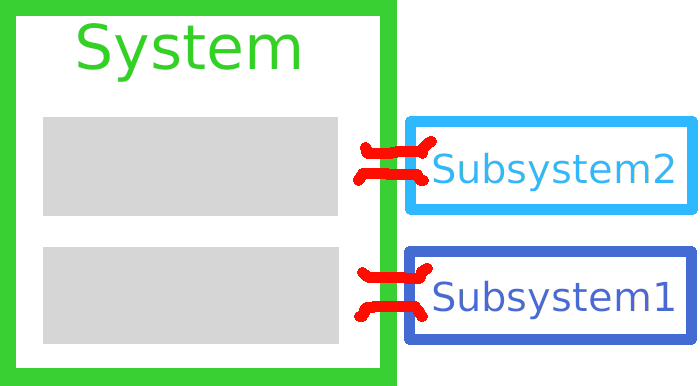
Здесь у нас: 3 системы и 2 связи между ними. Обратите внимание, что количество функционала осталось тем же самым – архитектура ни увеличивает, ни уменьшает функционал, это просто способ организовать код.
Какое различие можно разглядеть между этими двумя альтернативами? При рефакторинге в первом случае нам нужно “прочесать” 100% кода (весь зеленый квадрат), чтобы убедиться, что мы не внесли никакой регрессии. При том же самом рефакторинге во втором случае, нам сначала нужно определить, к какой системе он относится. И потом весь наш рефакторинг сведется к прочесыванию лишь одной из 3х систем. Задача упростилась во втором случае! За счет успешного дробления архитектурой, нам достаточно сконцентрироваться лишь на части кода, а не на всех 100% кода.
На этом примере видно, почему дробить на максимальное количество объектов выгодно. Но существует еще и вторая часть цитаты – минимизация связей между ними. А что, если новая доработка, которая пришла к нам от начальства затрагивает сам интерфейс (красненький мост между 2мя системами)? Тогда дела плохи – изменения в интерфейсе подразумевают изменения по оба конца этого моста. И как раз чем меньше у нас связей между системами, тем меньше вероятность того, что наш рефакторинг вообще затронет какой-либо интерфейс. А чем проще каждый из интерфейсов, тем проще будет внести необходимые изменения по обе стороны интерфейса.
Ключом к правильному применению архитектуры я считаю именно интерфейс, ведь он определяет формат взаимодействия и, соответственно, границы каждой из систем. Другими словами, от выбраных интерфейсов зависит и количество подсистем и их связанность (количество связей). Рассмотрим его поближе.
Прежде всего, он должен быть честным. Не должно быть коммуникаций между системами за пределами интерфейса. Иначе мы скатимся к исходному варианту – диффузия (да, она в программировании тоже есть!) объединит 2 системы обратно в одну общую систему.
Интерфейс должен быть полным. Актер по одну из сторон интерфейса не должен иметь никакого понятия о внутреннем устройстве актера по другую сторону моста – не больше чем то, что подразумевает интерфейс, по которому они взаимодействуют, т.е. интерфейс должен полным (достаточным для наших нужд) образом описывать партнера по “ту сторону моста”. Делая интерфейс полным изначально, мы значительно уменьшаем шансы того, что в будущем придется править интерфейс – вспомните, внесение изменений в интерфейс – это самая дорогая операция, т.к. она подразумевает изменения в более, чем одной подсистеме.
Интерфейс не обязательно должен быть задекларированным как интерфейс из ООП. Я считаю, что достаточно честности, полноты интерфейса и вашего ясного понимания этого интерфейса. Более того, интерфейс такой, как я его подразумеваю в рамках этой статьи – это нечто шире чем интерфейс из ООП. Важна не форма, а суть.
Здесь будет уместным упомянуть архитектуру микросервисов. Границы между каждым из сервисов – это ни что иное, как интерфейс, о котором я повествую в этой статье.
В качестве примера я хочу привести счетчик использования файла в inode на *nix (file reference count): есть интерфейс – если ты используешь файл, то увеличь его счетчик на 1. Когда закончил им пользоваться, уменьши его счетчик на 1. Когда счетчик равняется нулю, значит этим файлом уже никто не пользуется, и его нужно удалить. Такой интерфейс неописуемо гибкий, т.к. он не накладывает абсолютно никаких ограничений на внутреннее устройство актера, который им может пользоваться. В этот интерфейс органично вписывается как использование файлов в рамках файловой системы, так и файл декскриптор из исполняемых программ.
Очевидно, что умение выбрать правильный интерфейс – очень важный навык. Мой опыт мне подсказывает, что очень часто удачный интерфейс приходит в голову, когда ты пытаешься решить задачу на абстрактном (общем) уровне, а не текущем (конкретном) ее проявлении. Альберт Эйнштейн однажды сказал, что правильная постановка задачи важнее, чем ее решение. В этом свете я с ним полностью согласен.
Какое решение задачи “открыть входную дверь” вам кажется более правильным?
Или:
Абстрактность второго алгоритма в разы выше, чем первого, и как следствие, его полнота тоже выше. Банально у второго алгоритма куда больше шансов остаться актуальным даже 50 лет спустя, когда понятие “ключей” и “дверей” будет отличаться от сегодняшнего :)
Смотря на проблему с абстрактной точки зрения, нам в голову естественным образом приходят полные интерфейсы. Ведь решая частное проявление проблемы, максимум, что мы можем придумать в плане интерфейса – это всего лишь его частная проекция на нашу частную проблему. Смотря на абстрактную проблему у нас больше шансов увидеть полный интерфейс, а не его проявление под какую-то конкретику.
В какой-то момент вы начинаете видеть эти абстрактные операции за их конкретными проявлениями (реализациями). Это уже отлично! Но не забывайте, что вам нужно минимизировать количество связей – это значит, что существует риск забраться слишком далеко в дебри абстракции. Абсолютно необязательно включать в вашу архитектуру все абстракции, которые вы видите при анализе. Включайте только те, которые оправдывают свое присутствие за счет дополнительной вносимой гибкости либо за счет дробления чрезмерно сложной системы на подсистемы.
Есть такая наука, и я ее люблю наравне с программированием. В физике многие явления можно рассматривать на разных уровнях абстракции. Столкновение двух объектов можно рассматривать как динамику Ньютона, а можно рассматривать как квантовую механику. Давление воздуха в воздушном шарике можно рассматривать как микро- и макро-термодинамику. Наверное, физики пришли к такой модели не зря.
Дело в том, что использование разных уровней детализации в архитектуре кода тоже очень выгодно. Любую подсистему можно рекурсивно дробить дальше на под-подсистемы. Подсистема станет выступать системой, и мы будем в ней искать подсистемы. Это divide and conquer (разделяй и властвуй) подход. Таким образом программу любой сложности можно объяснить на удобном собеседнику уровне детализации за 5 минут за кружкой пива другу программисту или начальнику нетехнарю на корпоративном собрании.
Как пример, что происходит в нашем ноутбуке, когда мы включаем фильм? Все можно рассматривать на уровне медиапроигрывателя (читаем содержимое фильма, декодируем в видео, показываем на мониторе). Можно рассматривать на уровне операционной системы (читаем с блочного устройства, копируем в нужные страницы памяти, “просыпаем” процесс плеера и запускаем его на одном из ядер), а можно же и на уровне драйвера диска (соптимизировать i/o очередь на устройство, прокрутить до нужного сектора, считать данные). Кстати, в случае SSD диска последний список шагов был бы другим – и в этом вся прелесть, т.к. в операционных системах есть интерфейс блочного устройства хранения данных, мы можем вытыкнуть магнитный диск, втыкнуть флешку и не заметим особой разницы. Более того, интерфейс блочного устройства был придуман задолго до появления CD дисков, флешек и многих других современных носителей информации – что это как не пример успешного абстрактного интерфейса, который прожил и остался актуальным на протяжении ни одного поколения устройств? Конечно, кто-то может возразить, что процесс был обратным – новые устройства вынужденно адаптировались под уже существующий интерфейс. Но если бы интерфейс блочного устройства был откровенно плохим и неудобным, он бы не выстоял на рынке и был бы поглощен какой-то другой альтернативой.
Человеческий мозг не может удерживать в голове много концепций/объектов одновременно, вне зависимости от того, говорим ли мы о физике или о программировании либо еще о чем-либо. Соответственно, старайтесь организовать вертикальную иерархию вашей архитектуры так, чтобы у вас было не больше дюжины актеров на любом уровне абстракции. Сравните два описания одной и той же системы:
Правильно! Они сначала проектируют ракету (ракету, как единое целое, и отдельно каждую из ее компонент). Затем они строят завод по производству каждой из компонент и завод по финальной сборке ракеты из произведенных компонент. А потом они летят на луну на собранной ракете. Чувствуется какая-то параллель?
На выходе получается огромное количество компонент, которые можно переиспользовать в других смежных целях. А еще есть заводы, которые эти компоненты массово производят. И успех всего предприятия в наибольшей степени зависит от успешной проектировки (когда в проект забыли внести модуль по регенерации кислорода, а ракета уже стоит на стартовой площадке – дела плохи), чуть меньше от качества построенных заводов (заводы еще можно как-то калибровать и тестировать) и меньше всего от конкретного экземпляра ракеты, которая стоит на пусковой установке – если с ней что-то случится, ее будет легко пересоздать на базе уже имеющейся инфраструктуры. Скоро научимся клонировать людей, и тогда даже при неудачных пусках о человеческих потерях не будет речи :)
В программировании все точно так же. На плечи железа выпадает роль заводов – исполнять наш код. Но вот роль проектировки (создания архитектуры) и конкретных имплементаций (постройка заводов) ложится на плечи программиста. Очень редко эти 2 этапа как-то явно выделяются из общего клубка. А мыслить об этих 2-х этапах раздельно очень полезно, более того, в других областях это даже выглядит нелогично. Ведь кто будет сразу строить завод, предварительно не решив, что же этот завод будет производить?
Я здесь только резюмирую концепции, которые пытался описать выше. При успешном использовании архитектуры, мы имеем:
Успешность архитектуры невозможно оценить однозначно “да” либо “нет”. Более того, одна и та же архитектура может быть успешной в рамках одного проекта (спецификации) и провальной в рамках другого проекта, даже если оба проекта номинально оперируют в одной и той же предметной области. В момент проектирования от вас требуется максимально глубокое и исчерпывающее понимание процесса, который вы автоматизируете/моделируете кодом.
Тем не менее, некоторые общие черты успешных архитектур я вам осмелюсь предложить:
Попытайтесь задать 3 вопроса, когда анализируете задачу на архитектуру: Что мы делаем? Зачем мы это делаем? Как мы это делаем? За “что?” отвечает интерфейс, к примеру “мы уведомляем пользователя о событии”. За “зачем?” отвечает потребитель – код, который вызывает подсистему, и на вопрос “как” отвечает конкретная реализация интерфейса (поставщик услуги).
Постарайтесь любую самодостаточную операцию оформить в виде подпрограммы (функции, метода либо еще чего-то в зависимости от доступного вам инструментария). Даже если это всего лишь одна строчка кода, и используется она один раз в вашей программе. Так вы отделяете архитектурный код (список абстрактный действий) от имплементаций. В таком контексте эта функция выступает в роли интерфейса, и тут же получаем потребителя (вызывает функцию) и поставщика (реализация функции). Пример:
или
Используйте побольше уровней детализации в вашей архитектуре. При интенсивном “вертикальном” дроблении у вас будет широкий выбор из компонент разного калибра. Когда вы начнете решать очередную задачу в рамках такого проекта, у вас будет выбор либо использовать какую-то высокоуровневую систему (быстро, возможно в ущерб гибкости решения), либо “дособрать” из низкоуровневых компонент решение, которое точнее ложится под бизнес потребности. Естественно, по возможности вы будете предпочитать высокоуровневые компоненты, но у вас всегда будет свобода собрать какой-то критический участок из более низкоуровневых компонент. К примеру, у вас может быть высокоуровневая компонента “уведомить пользователя о событии”. Она, исходя из настроек в профиле пользователя выбирает длинный либо короткий вариант уведомления и отсылает его либо смской либо на почту. Такая высокоуровневая компонента использует 2 более низкоуровневые: “отправить смску на номер X с содержанием Y” и “отправить имейл по адресу X с содержанием Y”. Когда вам в следующий раз нужно уведомить пользователя о каком-либо событии вероятнее всего вы воспользуетесь высокоуровневой компонентой. Но у вас остается опция слать смски и письма в обход высокоуровневой компоненты используя низкоуровневый слой напрямую – допустим, это вам может пригодиться при критически важном уведомлении – такое лучше бы слать прямо на телефон смской в обход настроек пользователя в силу критичности ситуации. Чем больше уровней детализации вы выделите, тем больше у вас будет такой свободы. Это как атомная бомба и точечный авиаудар – иногда удобнее разбомбить к чертям полматерика, а иногда удобнее нанести 10 точечных ударов по стратегическим объектам. С бомбой проще (более высокий уровень абстракции – просто ткнуть пальцем в нужный материк), с авиаударом больше мороки (нужно выделить эти 10 стратегических объектов), однако иметь выбор из двух альтернатив всегда лучше, чем одна единственная опция.
Ваше воображение работает в разы быстрее, чем ваши пальцы – валидируйте и “примеряйте” архитектуру на бумажке, прежде чем начать ее реализовывать в коде. Будет обидно понять через 5 часов кодирования, что придуманные вами интерфейсы не покрывают нужды предметной области, и эту проблему вы могли бы предвидеть, потратив 20 минут на анализ архитектуры и “проверку” архитектуры на бумаге. В некоторые моменты я провожу полный рабочий день сидя и смотря в небо – придумывая и обкатывая архитектуру на бумаге.
Не перегружайте ваши интерфейсы. В погоне за полнотой интерфейса, мы можем включить в него избыточные элементы, но здесь можно ненароком кашу испортить маслом. Чем больше элементов включает интерфейс, тем меньше свободы он оставляет тому, кто его будет реализовывать. Так же не забывайте, что возможно, в какой-то момент вам нужно будет изменить этот интерфейс в свете каких-то новых бизнес задач. Чем интерфейс проще, тем проще изменять его и актеров по обе стороны этого интерфейса.
Может звучать парадоксально, но перегруженный интерфейс будет менее полным чем идеально сбалансированный по нагрузке интерфейс. Излишние подробности сужают интерфейс, а не расширяют его, т.к. некоторые подробности теряют свой физический смысл в каком-то другом контексте. К примеру, мы могли бы “перестараться” и в наш интерфейс системы уведомления пользователя о каком-либо событии ввести понятие часового пояса: “уведомить пользователя о событии с учетом (или без) его часового пояса”. В некотором контексте это будет правильным интерфейсом, а в каком-то неправильным. Допустим пользователи нашей системы начнут жить на луне и там нет понятия “часового пояса” в таком смысле, в котором к нему привыкли земляне. Тогда это дополнительная нагрузка в интерфейсе окажется избыточной и будет действовать в ущерб всей архитектуре.
Не забывайте о вопросах производительности и масштабируемости в момент проектирования архитектуры. В идеале интерфейсы должны быть максимально простыми – допустим пару функций, которые позволяют изменять и удалять какую-то сущность из хранилища. Упаковывая в интерфейс лишь 2 функции мы получаем высокий уровень абстракции – мы можем использовать реляционную БД и NoSQL для физического хранения данных. Но если таких сущностей будут тысячи, то становится очевидным, что ими нужно манипулировать на уровне СУБД, а не приложения. Тогда нужно сознательно включить в интерфейс структуру БД, где эти сущности хранятся. В противном случае интерфейс будет красивым, но неполным, ибо с учетом требований производительности, полный интерфейс должен предоставлять быстрый и эффективный инструментарий для массового взаимодействия с сущностями.
Способность правильно понять предметную область, идентифицировать успешные интерфейсы я отношу к искусству. В моем личном случае, я учился этому ремеслу через практику и созерцание архитектур других авторов, всегда пропуская исследуемую архитектуру через призму собственного критического мышления.
В следующий раз, когда вам нужно решить относительно большую задачу, отойдите от компьютера и посидите с листком бумаги час. В начале, возможно, никакие мысли не будут лезть в голову, но вы честно продолжайте размышлять над проблемой и абстракциями/интерфейсами, которые могут быть спрятаны внутри этой проблемы. Не отвлекайтесь – очень важна глубина погружения и концентрация, чтобы вы смогли максимально детально продумать и скомпоновать всех актеров и их связи у себя в воображении.
Когда вы видите чужую (либо свою, но какое-то время ранее реализованную) архитектуру, и вам нужно внести правки в код, попытайтесь проанализировать, удобно ли вносить эти правки при текщей архитектуре, достаточно ли она гибка. Что в ней можно улучшить?
Upd.: я эту статью написал, когда готовился к выступлению на одной конференции. Видеозапись можно просмотреть здесь — meduza.carnet.hr/index.php/media/watch/12326
Это очень философская тема, поэтому я не могу предложить ничего более, чем мой субъективный анализ и опыт.
Проблемы, симптомы
Мой начальный опыт программиста был весьма безоблачным – я без лишних проблем клепал вебсайты-визитки. Писал код, как я это сейчас называю “в строчку” или “полотном”. На маленьких объемах и простых задачах все было хорошо.
Но я сменил работу, и пришлось разрабатывать один единственный вебсайт в течение 4-х лет. Естественно, сложность этого кода была несопоставима с визитками из моей прошлой работы. В какой-то момент проблемы просто посыпались на меня – количество регрессии зашкаливало. Было ощущение, что я просто хожу по кругу – пока чинил “здесь”, сломал что-то “там”. И поэтом это “здесь” и “там” банально менялось местами и круг повторялся.
У меня исчезла уверенность в том, что я контролирую ситуацию – при всем моем желании недопустить баги, они проскакивали. Все эти 4 года проект активно разрабатывался – мы улучшали уже существующий функционал, расширяли, достраивали его. Я видел и чувствовал, как удельная стоимость каждого нового рефакторинга/доработки растет – увеличивался общий объем кода, и соответственно увеличивались затраты на любую его правку. Банально, я вышел на порог, через который уже не мог переступить, продолжая писать код “в строчку”, без использования архитектуры. Но в тот момент, я этого еще не понимал.
Другим важным симптомом оказались книги и видео-уроки, которые я в то время читал/смотрел. Код с этих источников выглядел “глянцево” красивым, естественным и интуитивно понятным. Видя такую разницу между учебниками и реальной жизнью, моей первой реакцией была мысль, что это нормально – в жизни всегда сложнее, чем в теории, больше рутины и конкретики.
Тем не менее, продукт на работе нужно было расширять, улучшать, в общем, двигаться дальше. В тот же самый момент я начал активно участвовать в одном open source проекте. И в совокупности эти факторы вытолкнули меня на путь архитектурного мышления.
Что такое архитектура?
Один мой преподаватель в университете употребил фразу “нужно проектировать так, чтобы максимизировать количество объектов и минимизировать количество связей между ними”. Чем дольше я живу, тем больше с ним соглашаюсь. Если присмотреться к этой цитате, то видно, что эти 2 условия в какой-то мере взаимоисключающие – чем больше мы дробим какую-то систему на подсистемы, тем больше связей придется вводить между ними, чтобы “соединить” каждую из подсистем с остальными актерами. Найти оптимальный баланс между первым и вторым – это своего рода искусство, которым, как и прочими искусствами, можно овладеть через практику.
Сложная система дробится на подсистемы за счет интерфейсов. Для того, чтобы выделить из сложной системы какую-то подсистему, нужно определить интерфейс, который будет декларировать границы между первым и вторым. Представьте, у нас была сложная система, и вроде бы внутри нее осязаются некоторые подсистемы, но они “размазаны” по разным местам основной системы и четкий формат (интерфейс) взаимодействия между ними отсутствует:
Посчитаем, де факто, у нас 1 система и 0 связей. С минимизацией связей все отлично :) Но вот количество систем очень маленькое.
А теперь, кто-то проделал анализ кода, и четко выделил 2 подсистемы, определил интерфейсы, по которым ведется коммуникация. Это значит, что границы подсистем определены и схема стала следующей:
Здесь у нас: 3 системы и 2 связи между ними. Обратите внимание, что количество функционала осталось тем же самым – архитектура ни увеличивает, ни уменьшает функционал, это просто способ организовать код.
Какое различие можно разглядеть между этими двумя альтернативами? При рефакторинге в первом случае нам нужно “прочесать” 100% кода (весь зеленый квадрат), чтобы убедиться, что мы не внесли никакой регрессии. При том же самом рефакторинге во втором случае, нам сначала нужно определить, к какой системе он относится. И потом весь наш рефакторинг сведется к прочесыванию лишь одной из 3х систем. Задача упростилась во втором случае! За счет успешного дробления архитектурой, нам достаточно сконцентрироваться лишь на части кода, а не на всех 100% кода.
На этом примере видно, почему дробить на максимальное количество объектов выгодно. Но существует еще и вторая часть цитаты – минимизация связей между ними. А что, если новая доработка, которая пришла к нам от начальства затрагивает сам интерфейс (красненький мост между 2мя системами)? Тогда дела плохи – изменения в интерфейсе подразумевают изменения по оба конца этого моста. И как раз чем меньше у нас связей между системами, тем меньше вероятность того, что наш рефакторинг вообще затронет какой-либо интерфейс. А чем проще каждый из интерфейсов, тем проще будет внести необходимые изменения по обе стороны интерфейса.
Интерфейс в самом широком смысле
Ключом к правильному применению архитектуры я считаю именно интерфейс, ведь он определяет формат взаимодействия и, соответственно, границы каждой из систем. Другими словами, от выбраных интерфейсов зависит и количество подсистем и их связанность (количество связей). Рассмотрим его поближе.
Прежде всего, он должен быть честным. Не должно быть коммуникаций между системами за пределами интерфейса. Иначе мы скатимся к исходному варианту – диффузия (да, она в программировании тоже есть!) объединит 2 системы обратно в одну общую систему.
Интерфейс должен быть полным. Актер по одну из сторон интерфейса не должен иметь никакого понятия о внутреннем устройстве актера по другую сторону моста – не больше чем то, что подразумевает интерфейс, по которому они взаимодействуют, т.е. интерфейс должен полным (достаточным для наших нужд) образом описывать партнера по “ту сторону моста”. Делая интерфейс полным изначально, мы значительно уменьшаем шансы того, что в будущем придется править интерфейс – вспомните, внесение изменений в интерфейс – это самая дорогая операция, т.к. она подразумевает изменения в более, чем одной подсистеме.
Интерфейс не обязательно должен быть задекларированным как интерфейс из ООП. Я считаю, что достаточно честности, полноты интерфейса и вашего ясного понимания этого интерфейса. Более того, интерфейс такой, как я его подразумеваю в рамках этой статьи – это нечто шире чем интерфейс из ООП. Важна не форма, а суть.
Здесь будет уместным упомянуть архитектуру микросервисов. Границы между каждым из сервисов – это ни что иное, как интерфейс, о котором я повествую в этой статье.
В качестве примера я хочу привести счетчик использования файла в inode на *nix (file reference count): есть интерфейс – если ты используешь файл, то увеличь его счетчик на 1. Когда закончил им пользоваться, уменьши его счетчик на 1. Когда счетчик равняется нулю, значит этим файлом уже никто не пользуется, и его нужно удалить. Такой интерфейс неописуемо гибкий, т.к. он не накладывает абсолютно никаких ограничений на внутреннее устройство актера, который им может пользоваться. В этот интерфейс органично вписывается как использование файлов в рамках файловой системы, так и файл декскриптор из исполняемых программ.
Решайте задачу на абстрактном, а не конкретном уровне
Очевидно, что умение выбрать правильный интерфейс – очень важный навык. Мой опыт мне подсказывает, что очень часто удачный интерфейс приходит в голову, когда ты пытаешься решить задачу на абстрактном (общем) уровне, а не текущем (конкретном) ее проявлении. Альберт Эйнштейн однажды сказал, что правильная постановка задачи важнее, чем ее решение. В этом свете я с ним полностью согласен.
Какое решение задачи “открыть входную дверь” вам кажется более правильным?
- Подойти к двери;
- Достать из кармана связку ключей;
- Выбрать нужный ключ;
- Открыть им дверь.
Или:
- Подойти к двери;
- Вызвать подсистему “хранилище ключей” и получить из нее доступную связку ключей;
- Вызвать подсистему “поиск правильного ключа” и запросить у нее наиболее подходящий ключ к текущей двери из связки доступных ключей;
- Открыть дверь ключем, предложенным подсистемой поиска правильного ключа.
Абстрактность второго алгоритма в разы выше, чем первого, и как следствие, его полнота тоже выше. Банально у второго алгоритма куда больше шансов остаться актуальным даже 50 лет спустя, когда понятие “ключей” и “дверей” будет отличаться от сегодняшнего :)
Смотря на проблему с абстрактной точки зрения, нам в голову естественным образом приходят полные интерфейсы. Ведь решая частное проявление проблемы, максимум, что мы можем придумать в плане интерфейса – это всего лишь его частная проекция на нашу частную проблему. Смотря на абстрактную проблему у нас больше шансов увидеть полный интерфейс, а не его проявление под какую-то конкретику.
В какой-то момент вы начинаете видеть эти абстрактные операции за их конкретными проявлениями (реализациями). Это уже отлично! Но не забывайте, что вам нужно минимизировать количество связей – это значит, что существует риск забраться слишком далеко в дебри абстракции. Абсолютно необязательно включать в вашу архитектуру все абстракции, которые вы видите при анализе. Включайте только те, которые оправдывают свое присутствие за счет дополнительной вносимой гибкости либо за счет дробления чрезмерно сложной системы на подсистемы.
Физика
Есть такая наука, и я ее люблю наравне с программированием. В физике многие явления можно рассматривать на разных уровнях абстракции. Столкновение двух объектов можно рассматривать как динамику Ньютона, а можно рассматривать как квантовую механику. Давление воздуха в воздушном шарике можно рассматривать как микро- и макро-термодинамику. Наверное, физики пришли к такой модели не зря.
Дело в том, что использование разных уровней детализации в архитектуре кода тоже очень выгодно. Любую подсистему можно рекурсивно дробить дальше на под-подсистемы. Подсистема станет выступать системой, и мы будем в ней искать подсистемы. Это divide and conquer (разделяй и властвуй) подход. Таким образом программу любой сложности можно объяснить на удобном собеседнику уровне детализации за 5 минут за кружкой пива другу программисту или начальнику нетехнарю на корпоративном собрании.
Как пример, что происходит в нашем ноутбуке, когда мы включаем фильм? Все можно рассматривать на уровне медиапроигрывателя (читаем содержимое фильма, декодируем в видео, показываем на мониторе). Можно рассматривать на уровне операционной системы (читаем с блочного устройства, копируем в нужные страницы памяти, “просыпаем” процесс плеера и запускаем его на одном из ядер), а можно же и на уровне драйвера диска (соптимизировать i/o очередь на устройство, прокрутить до нужного сектора, считать данные). Кстати, в случае SSD диска последний список шагов был бы другим – и в этом вся прелесть, т.к. в операционных системах есть интерфейс блочного устройства хранения данных, мы можем вытыкнуть магнитный диск, втыкнуть флешку и не заметим особой разницы. Более того, интерфейс блочного устройства был придуман задолго до появления CD дисков, флешек и многих других современных носителей информации – что это как не пример успешного абстрактного интерфейса, который прожил и остался актуальным на протяжении ни одного поколения устройств? Конечно, кто-то может возразить, что процесс был обратным – новые устройства вынужденно адаптировались под уже существующий интерфейс. Но если бы интерфейс блочного устройства был откровенно плохим и неудобным, он бы не выстоял на рынке и был бы поглощен какой-то другой альтернативой.
Человеческий мозг не может удерживать в голове много концепций/объектов одновременно, вне зависимости от того, говорим ли мы о физике или о программировании либо еще о чем-либо. Соответственно, старайтесь организовать вертикальную иерархию вашей архитектуры так, чтобы у вас было не больше дюжины актеров на любом уровне абстракции. Сравните два описания одной и той же системы:
Мы здесь обрабатываем входящие заказы. Сначала идет процесс валидации – проверяем наличие заказанных товаров на складе, проверяем правильность адреса доставки, успешность платежа. Потом запускается процесс уведомления – оператору приходит смс-ка с информацией о новом заказе. Начальник отдела получает имейл со сводной информацией.Или:
Мы здесь обрабатываем входящие заказы. Сначала отрабатывает система валидации – проверяем точность и правильность всех данных. Ну в принципе, если тебе интересно, у нас там есть внутренняя валидация (наличие на складе и тп.) и внешняя (правильность информации, указанной в заказе). При успешной отработке валидации запускается система уведомлений – вот по этой ссылке найдешь полную информацию об уведомлениях.Чувствуете, вертикальную ориентацию второго описания по сравнению с первым? Дополнительно, второе описание ярче выделяет абстракции “валидация” и “уведомление”, чем первое.
Как люди обычно летают на Луну?
Правильно! Они сначала проектируют ракету (ракету, как единое целое, и отдельно каждую из ее компонент). Затем они строят завод по производству каждой из компонент и завод по финальной сборке ракеты из произведенных компонент. А потом они летят на луну на собранной ракете. Чувствуется какая-то параллель?
На выходе получается огромное количество компонент, которые можно переиспользовать в других смежных целях. А еще есть заводы, которые эти компоненты массово производят. И успех всего предприятия в наибольшей степени зависит от успешной проектировки (когда в проект забыли внести модуль по регенерации кислорода, а ракета уже стоит на стартовой площадке – дела плохи), чуть меньше от качества построенных заводов (заводы еще можно как-то калибровать и тестировать) и меньше всего от конкретного экземпляра ракеты, которая стоит на пусковой установке – если с ней что-то случится, ее будет легко пересоздать на базе уже имеющейся инфраструктуры. Скоро научимся клонировать людей, и тогда даже при неудачных пусках о человеческих потерях не будет речи :)
В программировании все точно так же. На плечи железа выпадает роль заводов – исполнять наш код. Но вот роль проектировки (создания архитектуры) и конкретных имплементаций (постройка заводов) ложится на плечи программиста. Очень редко эти 2 этапа как-то явно выделяются из общего клубка. А мыслить об этих 2-х этапах раздельно очень полезно, более того, в других областях это даже выглядит нелогично. Ведь кто будет сразу строить завод, предварительно не решив, что же этот завод будет производить?
Преимущества архитектуры
Я здесь только резюмирую концепции, которые пытался описать выше. При успешном использовании архитектуры, мы имеем:
- Простота изолированого тестирования каждой из систем. Так как каждая система общается с внешним миром через строгий интерфейс, ее очень легко протестировать отдельно
- Упрощение поддержки кода: за счет дробления на подсистемы внесение изменений в существующий код упрощается
- Расширяемость системы увеличивается, т.к. благодаря интерфейсам мы во многих местах можем легко подключить какой-либо новый функционал (либо заменить уже существующий на альтернативную реализацию)
- Повышается переиспользование кода: интерфейсы вводят слабое связывание в код. Значит какую-либо систему будет просто применить в какой-нибудь другой задаче. Здесь снова важную роль играет полнота интерфейса. Если интерфейс был действительно полным, его будет достаточно и для новой задачи. Вспомним парадигму Юникса “Делайте что-то одно, но делайте это хорошо” — переиспользовать хорошо написаную программу с полным интерфейсом одно удовольствие!
Признаки успешной архитектуры
Успешность архитектуры невозможно оценить однозначно “да” либо “нет”. Более того, одна и та же архитектура может быть успешной в рамках одного проекта (спецификации) и провальной в рамках другого проекта, даже если оба проекта номинально оперируют в одной и той же предметной области. В момент проектирования от вас требуется максимально глубокое и исчерпывающее понимание процесса, который вы автоматизируете/моделируете кодом.
Тем не менее, некоторые общие черты успешных архитектур я вам осмелюсь предложить:
- Разделение между кодом архитектуры и кодом имплементации. Кто-то решает задачу на абстрактном уровне (это как начальник, который говорит “нужно повысить продажи в следующем квартале”), а кто-то имплементирует конкретные шаги, необходимые для достижения одной из составляющих общего результата (сотрудник PR отдела начинает давать объявления в газету).
- В какой бы точке программы мы не остановились, всегда должно быть абстрактное объяснение того, чем мы тут занимаемся. На уровне начальника это может быть “мы увеличиваем продажи, т.к. прошлый квартал был неприбыльным”, на уровне конкретного сотрудника это может быть “я даю объявления в газету, т.к. это часть моих должностных обязанностей (интерфейса), и мне только что пришел приказ сверху этим заняться”. Такое объяснение должно быть логичным и соответствовать уровню знаний/кругозора анализируемого субъекта/актера.
- Большинство кода выглядит как взаимодействие поставщика и потребителя услуг. Система уведомлений пользователя предоставляет услугу “уведомить пользователя о событии Х” и в свою очередь в рамках реализации этой услуги потребляет услугу “отправить смс сообщение” и “отправить имейл”.
- Все критические компоненты можно легко заменить на альтернативные реализации. Банально отсоединяем старую компоненту и на тот же интерфейс подсоединяем компоненту с альтернативной реализацией. Кстати, ваш начальник-нетехнать будет ужасно рад такой возможности в какой-то критический момент!
- Архитектуры легко объяснить словами (дополнительной документацией), и относительно сложно “понять смысл” смотря в код. Словами проще объяснить смысловую нагрузку интерфейсов, которые составляют архитектуру, т.к. при высоком уровне абстракции интерфейса эта самая смысловая нагрузка не так очевидна из кода. К тому же, некоторые интерфейсы, официально незадекларированные в рамках используемого языка программирования, могут банально прошмыгнуть мимо глаза программиста, когда он просматривает незнакомый код.
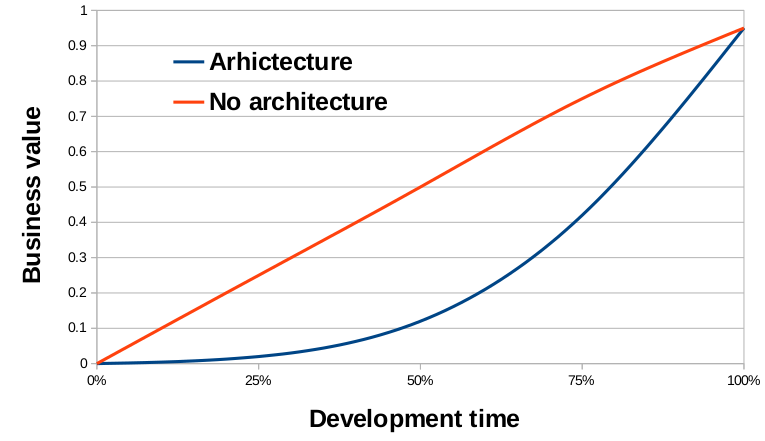
- При использовании архитектуры, большая часть функционала становится доступной ближе к концу цикла разработки. На начальных этапах программист пишет код архитектуры и реализует отдельные подсистемы. Лишь в самом конце он их соединяет между собой в правильной последовательности для достижения конечного (бизнес) результата. А когда архитектуры нет либо ее мало, то функционал поставляется более-менее линейно – банально человеку нужно 10 дней, чтобы написать код, и он каждый день пишет 10% от общего полотна кода. Вот графическое объяснение этого пункта — график распределения завершенности задачи от времени разработки:
Советы для построения успешной архитектуры
Попытайтесь задать 3 вопроса, когда анализируете задачу на архитектуру: Что мы делаем? Зачем мы это делаем? Как мы это делаем? За “что?” отвечает интерфейс, к примеру “мы уведомляем пользователя о событии”. За “зачем?” отвечает потребитель – код, который вызывает подсистему, и на вопрос “как” отвечает конкретная реализация интерфейса (поставщик услуги).
Постарайтесь любую самодостаточную операцию оформить в виде подпрограммы (функции, метода либо еще чего-то в зависимости от доступного вам инструментария). Даже если это всего лишь одна строчка кода, и используется она один раз в вашей программе. Так вы отделяете архитектурный код (список абстрактный действий) от имплементаций. В таком контексте эта функция выступает в роли интерфейса, и тут же получаем потребителя (вызывает функцию) и поставщика (реализация функции). Пример:
function process_object($object) {
$object->data[‘special’] = TRUE;
$object->save();
send_notifications($object);
}или
function process_object($object) {
$object->markAsSpecial();
$object->save();
send_notifications($object);
}Используйте побольше уровней детализации в вашей архитектуре. При интенсивном “вертикальном” дроблении у вас будет широкий выбор из компонент разного калибра. Когда вы начнете решать очередную задачу в рамках такого проекта, у вас будет выбор либо использовать какую-то высокоуровневую систему (быстро, возможно в ущерб гибкости решения), либо “дособрать” из низкоуровневых компонент решение, которое точнее ложится под бизнес потребности. Естественно, по возможности вы будете предпочитать высокоуровневые компоненты, но у вас всегда будет свобода собрать какой-то критический участок из более низкоуровневых компонент. К примеру, у вас может быть высокоуровневая компонента “уведомить пользователя о событии”. Она, исходя из настроек в профиле пользователя выбирает длинный либо короткий вариант уведомления и отсылает его либо смской либо на почту. Такая высокоуровневая компонента использует 2 более низкоуровневые: “отправить смску на номер X с содержанием Y” и “отправить имейл по адресу X с содержанием Y”. Когда вам в следующий раз нужно уведомить пользователя о каком-либо событии вероятнее всего вы воспользуетесь высокоуровневой компонентой. Но у вас остается опция слать смски и письма в обход высокоуровневой компоненты используя низкоуровневый слой напрямую – допустим, это вам может пригодиться при критически важном уведомлении – такое лучше бы слать прямо на телефон смской в обход настроек пользователя в силу критичности ситуации. Чем больше уровней детализации вы выделите, тем больше у вас будет такой свободы. Это как атомная бомба и точечный авиаудар – иногда удобнее разбомбить к чертям полматерика, а иногда удобнее нанести 10 точечных ударов по стратегическим объектам. С бомбой проще (более высокий уровень абстракции – просто ткнуть пальцем в нужный материк), с авиаударом больше мороки (нужно выделить эти 10 стратегических объектов), однако иметь выбор из двух альтернатив всегда лучше, чем одна единственная опция.
Ваше воображение работает в разы быстрее, чем ваши пальцы – валидируйте и “примеряйте” архитектуру на бумажке, прежде чем начать ее реализовывать в коде. Будет обидно понять через 5 часов кодирования, что придуманные вами интерфейсы не покрывают нужды предметной области, и эту проблему вы могли бы предвидеть, потратив 20 минут на анализ архитектуры и “проверку” архитектуры на бумаге. В некоторые моменты я провожу полный рабочий день сидя и смотря в небо – придумывая и обкатывая архитектуру на бумаге.
Не перегружайте ваши интерфейсы. В погоне за полнотой интерфейса, мы можем включить в него избыточные элементы, но здесь можно ненароком кашу испортить маслом. Чем больше элементов включает интерфейс, тем меньше свободы он оставляет тому, кто его будет реализовывать. Так же не забывайте, что возможно, в какой-то момент вам нужно будет изменить этот интерфейс в свете каких-то новых бизнес задач. Чем интерфейс проще, тем проще изменять его и актеров по обе стороны этого интерфейса.
Может звучать парадоксально, но перегруженный интерфейс будет менее полным чем идеально сбалансированный по нагрузке интерфейс. Излишние подробности сужают интерфейс, а не расширяют его, т.к. некоторые подробности теряют свой физический смысл в каком-то другом контексте. К примеру, мы могли бы “перестараться” и в наш интерфейс системы уведомления пользователя о каком-либо событии ввести понятие часового пояса: “уведомить пользователя о событии с учетом (или без) его часового пояса”. В некотором контексте это будет правильным интерфейсом, а в каком-то неправильным. Допустим пользователи нашей системы начнут жить на луне и там нет понятия “часового пояса” в таком смысле, в котором к нему привыкли земляне. Тогда это дополнительная нагрузка в интерфейсе окажется избыточной и будет действовать в ущерб всей архитектуре.
Не забывайте о вопросах производительности и масштабируемости в момент проектирования архитектуры. В идеале интерфейсы должны быть максимально простыми – допустим пару функций, которые позволяют изменять и удалять какую-то сущность из хранилища. Упаковывая в интерфейс лишь 2 функции мы получаем высокий уровень абстракции – мы можем использовать реляционную БД и NoSQL для физического хранения данных. Но если таких сущностей будут тысячи, то становится очевидным, что ими нужно манипулировать на уровне СУБД, а не приложения. Тогда нужно сознательно включить в интерфейс структуру БД, где эти сущности хранятся. В противном случае интерфейс будет красивым, но неполным, ибо с учетом требований производительности, полный интерфейс должен предоставлять быстрый и эффективный инструментарий для массового взаимодействия с сущностями.
Творение архитектуры
Способность правильно понять предметную область, идентифицировать успешные интерфейсы я отношу к искусству. В моем личном случае, я учился этому ремеслу через практику и созерцание архитектур других авторов, всегда пропуская исследуемую архитектуру через призму собственного критического мышления.
В следующий раз, когда вам нужно решить относительно большую задачу, отойдите от компьютера и посидите с листком бумаги час. В начале, возможно, никакие мысли не будут лезть в голову, но вы честно продолжайте размышлять над проблемой и абстракциями/интерфейсами, которые могут быть спрятаны внутри этой проблемы. Не отвлекайтесь – очень важна глубина погружения и концентрация, чтобы вы смогли максимально детально продумать и скомпоновать всех актеров и их связи у себя в воображении.
Когда вы видите чужую (либо свою, но какое-то время ранее реализованную) архитектуру, и вам нужно внести правки в код, попытайтесь проанализировать, удобно ли вносить эти правки при текщей архитектуре, достаточно ли она гибка. Что в ней можно улучшить?
Upd.: я эту статью написал, когда готовился к выступлению на одной конференции. Видеозапись можно просмотреть здесь — meduza.carnet.hr/index.php/media/watch/12326
