Вкратце:
- Пруф уже реализован на C++, JS и PHP, подходит для Java.
- Быстрее чем coroutine и Promise, больше фич.
- Не требует выделения отдельного программного стека.
- Дружит со всеми средствами безопасности и отладки.
- Работает на любой архитектуре и не требует особых флагов компилятора.
Взгляд назад
На заре ЭВМ был единый поток управления c блокировкой на ввод-вывод. Потом к нему добавили прерывания железа. Появилась возможность эффективного использования медленных и непредсказуемых устройств.
С ростом возможностей железа и его малой доступности, появилась необходимость выполнять несколько задач одновременно, что снабдили аппаратной поддержкой. Так появились изолированные процессы с абстрагированными от железа прерываниями в виде сигналов.
Следующим эволюционным этапом стала многопоточность, которая была реализована на фундаменте тех же процессов, но с общим доступом к памяти и другим ресурсам. Такой подход имеет свои ограничения и существенные накладные расходы на переключение в безопасной ОС.
Для общения между между процессами и даже различными машинами был предложена абстракция Promise/Future ещё 40+ лет назад.
Пользовательские интерфейсы и смешная сейчас проблема 10K клиентов привели к периоду расцвета Event Loop, Reactor и Proactor подходов, которые больше ориентированы на обработку событий чем ясную последовательную бизнес-логику.
Наконец пришли к современным coroutine (сопрограмма), которые по сути являются эмуляцией потоков поверх описанных выше абстракций с соответствующими техническими ограничениями и детерминированной передачей управления.
Для передачи событий, результата и исключений вернулись всё к той же концепции Promise/Future. Кое-какие конторы решили назвать чуть иначе — "Task".
В конечном счёте всё спрятали в красивую упаковку async/await, которая требует поддержки компилятора или транслятора в зависимости от технологии.
Проблемы с текущий ситуаций асинхронной бизнес-логики
Рассмотрим только coroutines и Promise, украшенные async/await, т.к. наличие проблем в более старых подходах подтверждает сам процесс эволюции.
Эти два термина не тождественны. Например, в ECMAScript нет сопрограмм, а есть синтаксические облегчения для использования Promise, которое в свою очередь лишь организует работу с адом обратных вызовов (callback hell). По факту, скриптовые движки вроде V8 идут дальше и делают особые оптимизации для чистых async/await функций и вызовов.
Высказывания экспертов о не попавших в C++17 co_async/co_await есть здесь на ресурсе, но давлением софтверного гиганта сопрограммы таки могут появиться в стандарте именно в их виде. Пока же традиционное признанное решение Boost.Context, Boost.Fiber и Boost.Coroutine2.
В Java так же до сих пор нет async/await на уровне языка, но есть такие решения как EA Async, которые как и Boost.Context необходимо подгоняться под каждую версию JVM и байт кода.
В Go присутствуют свои сопрограммы, но если внимательно посмотреть статьи и баг репорты открытых проектов, то выясняется что и здесь не всё так гладко. Возможно, потеря интерфейса сопрограммы как управляемой сущности не лучшая идея.
Мнение автора: сопрограммы на голом железе опасны
Лично автор мало чего имеет против сопрограмм в динамических языках, но крайне насторожено относится к любым заигрываниям со стеком на уровне машинного кода.
Несколько тезисов:
- Требуется выделять стек:
- стек на куче имеет целый ряд недостатков: проблемы своевременного определения переполнения, повреждение соседями и прочие проблемы надежности/безопасности,
- защищённый стек требует минимум одну страницу физической памяти, одну условную страницу и дополнительные накладные расходы для каждого вызова
asyncфункции: 4+KB (минимум) + повышенные системные лимиты, - в конечном итоге может быть так, что значительная часть выделенной под стеки памяти не используется во время простоя сопрограммы.
- Необходимо реализовать комплексную логику сохранения, восстановления и удаления состояния сопрограмм:
- под каждый случай архитектуры процессора (даже модели) и бинарного интерфейса (ABI): пример,
- новые или опциональные фичи архитектуры вносят потенциально латентные проблемы (например, Intel TSX, со-процессоры ARM или MIPS),
- другие потенциальные проблемы из-за закрытой документации проприетарных систем (документация Boost на это ссылается).
- Потенциальные проблемы с инструментами динамического анализа и с безопасностью в целом:
- например, требуется интеграция с Valgrind всё из-за тех же скачущих стеков,
- сложно говорить за антивирусы, но вероятно не особо им это нравится на примере проблем с JVM в прошлом,
- уверен, появятся новые виды атак и будут вскрыты уязвимости, связанные именно с реализацией сопрограмм.
Мнение автора: генераторы и yield принципиальное зло
Эта казалось бы сторонняя тема прямо связана с концепцией сопрограмм и свойства "продолжения".
Если вкратце, то для любой коллекции должен существовать полноценный итератор. Для чего создавать проблему обрезанного итератора-генератора — не понятно. Например, кейс с range() в Python скорее эксклюзивный выпендрёж, чем оправдание технического усложнения.
Если же кейс бесконечного генератора, то и логика его реализации элементарна. Для чего создавать дополнительные технические сложности чтобы внутри пихать бесконечный продолжаемый цикл.
Единственное дельное позже появившееся оправдание, которое приводят сторонники сопрограмм — это всякого рода поточные парсеры с инвертированием управления. По сути, это узкий специализированный кейс решения единичных проблем уровня библиотек, а не бизнес-логики приложений. При этом есть элегантное, простое и более дескриптивное решение через конечные автоматы. Область этих технических проблем сильно меньше области банальной бизнес-логики.
По факту, решаемая проблема получается высосана из пальца и требует сравнительно серьёзных усилий для изначальной реализации и длительной поддержки. На столько, что некоторые проекты могут ввести запрет на использование сопрограмм уровня машинного кода по примеру запрета на goto или использования динамического выделения памяти в отдельных индустриях.
Мнение автора: модель async/await на Promise из ECMAScript более надёжна, но требует адаптации
В отличии от продолжаемых сопрограмм, в этой модели куски кода скрытно делятся на непрерываемые блоки, оформленные в виде анонимных функций. В С++ это не совсем подходит из-за особенностей управления памятью, пример:
struct SomeObject {
using Value = std::vector<int>;
Promise funcPromise() {
return Promise.resolved(value_);
}
void funcCallback(std::function<void()> &&cb, const Value& val) {
somehow_call_later(cb);
}
Value value_;
};
Promise example() {
SomeObject some_obj;
return some_obj.funcPromise()
.catch([](const std::exception &e){
// ...
})
.then([&](SomeObject::value &&val){
return Promise([&](Resolve&& resolve, Reject&&){
some_obj.funcCallback(resolve, val);
});
});
}Во-первых, some_obj будет разрушен при выходе из example() и до вызова лямбда-функций.
Во-вторых, лямбда-функции с захватом переменных или ссылок являются объектами и скрытно добавляют копирование/перемещение, что может отрицательно сказаться на производительности при большом количестве захватов и необходимости выделять память на куче в ходе type erasure в обычной std::function.
В-третьих, сам интерфейс Promise зачат на концепции "обещания" результата, а не последовательного выполнения бизнес-логики.
Схематичное НЕ оптимальное решение может выглядеть примерно так:
Promise example() {
struct LocalContext {
SomeObject some_obj;
};
auto ctx = std::make_shared<LocalContext>();
return some_obj.funcPromise()
.catch([](const std::exception &e){
// ...
})
.then([ctx](SomeObject::Value &&val){
struct LocalContext2 {
LocalContext2(std::shared_ptr<LocalContext> &&ctx, SomeObject::Value &&val) :
ctx(ctx), val(val)
{}
std::shared_ptr<LocalContext> ctx;
SomeObject::Value val;
};
auto ctx2 = std::make_shared<LocalContext2>(
std::move(ctx),
std::forward<SomeObject::Value>(val)
);
return Promise([ctx2](Resolve&& resolve, Reject&&){
ctx2->ctx->some_obj.funcCallback([ctx2, resolve](){ resolve(); }, val);
});
});
}Примечание: std::move вместо std::shared_ptr не подходит из-за невозможности передачи в несколько лямбд сразу и роста их размера.
С добавлением async/await асинхронные "ужасы" приходят в удобоваримое состояние:
async void example() {
SomeObject some_obj;
try {
SomeObject::Value val = await some_obj.func();
} catch (const std::exception& e) (
// ...
}
// Capture "async context"
return Promise([async](Resolve&& resolve, Reject&&){
some_obj.funcCallback([async](){ resolve(); }, val);
});
}Мнение автора: планировщик сопрограмм — это перебор
Некоторые критики называют проблемой отсутствие планировщика и "нечестное" использование ресурсов процессора. Возможно более серьёзная проблема — это локальность данных и эффективное использование кэша процессора.
По первой проблеме: приоритизация на уровне отдельных сопрограмм выглядит большим оверхедом. Вместо этого ими возможно оперировать в общности для конкретной унифицированной задачи. Так поступают с транспортными потоками.
Такое возможно путём создания отдельных экземпляров Event Loop с собственными "железными" потоками и планированием на уровне ОС. Второй вариант — синхронизировать сопрограммы относительно ограничивающего по конкуренции и(или) производительности примитива (Mutex, Throttle).
Асинхронное программирование не делает ресурсы процессора резиновыми и требует абсолютно обычных ограничений по количеству одновременно обрабатываемых задач и ограничения общего времени выполнения.
Защита от длительного блокирования на одной сопрограмме требует тех же мер что и с обратными вызовами — избегать блокирующих системных вызовов и длительных циклов обработки данных.
По второй проблеме требуется исследование, но как минимум сами стеки сопрограмм и детали реализации Future/Promise уже нарушают локальность данных. Есть возможность пытаться продолжить выполнение той же сопрограммы, если Future уже имеет значение. Требуется некий механизм подсчёта времени выполнения или количества таких продолжений чтобы не дать одной сопрограмме захватить всё время процессора. Такое может либо не дать результата, либо дать весьма двоякий результат в зависимости от размера кэша процессора и количества потоков.
Есть ещё и третий момент — многие реализации планировщиков сопрограмм позволяют выполнять их на разных ядрах процессора, что наоборот добавляет проблем из-за обязательной синхронизации при доступе к общим ресурсам. В случае же единого потока Event Loop'а такая синхронизация требуется только на логическом уровне, т.к. каждый синхронный блок обратного вызова гарантированно работает без гонки с другими.
Мнение автора: всё хорошо в меру
Наличие потоков в современных ОС не отменяет использования отдельных процессов. Так же, обработка большого количества клиентов в Event Loop не отменяет использование обособленных "железных" потоков для иных нужд.
В любом случае, сопрограммы и различные варианты Event Loop'ов усложняют процесс отладки без необходимой поддержки в инструментах, а с локальными переменными на стеке сопрограмм всё становится ещё сложнее — к ним практически не добраться.

FutoIn AsyncSteps — альтернатива сопрограммам
За основу возьмём уже хорошо зарекомендовавший себя паттерн Event Loop и организацию схемы обратных вызовов по типу ECMAScript(JavaScript) Promise.
С точки зрения планирования выполнения нас интересуют следующие действия от Event Loop:
- Незамедлительный обратный вызов
Handle immediate(callack)с требованием чистого стека вызовов. - Отложенный обратный вызов
Handle deferred(delay, callback). - Отмена обратного вызова
handle.cancel().
Так получаем интерфейс с названием AsyncTool, который может быть реализован множеством способов, включая поверх уже существующих проверенных разработок. Прямого отношения к написанию бизнес-логики он не имеет, поэтому не будем вдаваться в дальнейшие детали.
Дерево шагов:
В концепции AsyncSteps, выстраивается абстрактное дерево синхронных шагов и выполняется проходом в глубину в последовательности создания. Шаги каждого более глубокого уровня динамично задаются по мере выполнения такого прохода.
Всё взаимодействие происходит через единый интерфейс AsyncSteps, который по конвенции передаётся первым параметром в каждый шаг. По конвенции название параметра asi или устарелое as. Такой подход позволяет практически полностью разорвать связь между конкретной реализацией и написанием бизнес-логики в плагинах и библиотеках.
В каноничных реализациях, каждый шаг получает свой экземпляр объекта, реализующего AsyncSteps, что позволяет своевременно отслеживать логические ошибки в использовании интерфейса.
Абстрактный пример:
asi.add( // Level 0 step 1
func( asi ){
print( "Level 0 func" )
asi.add( // Level 1 step 1
func( asi ){
print( "Level 1 func" )
asi.error( "MyError" )
},
onerror( asi, error ){ // Level 1 step 1 catch
print( "Level 1 onerror: " + error )
asi.error( "NewError" )
}
)
},
onerror( asi, error ){ // Level 0 step 1 catch
print( "Level 0 onerror: " + error )
if ( error strequal "NewError" ) {
asi.success( "Prm", 123, [1, 2, 3], true)
}
}
)
asi.add( // Level 0 step 2
func( asi, str_param, int_param, array_param ){
print( "Level 0 func2: " + param )
}
)Результат выполнения:
Level 0 func 1
Level 1 func 1
Level 1 onerror 1: MyError
Level 0 onerror 1: NewError
Level 0 func 2: PrmВ синхронном виде выглядело бы так:
str_res, int_res, array_res, bool_res // undefined
try {
// Level 0 step 1
print( "Level 0 func 1" )
try {
// Level 1 step 1
print( "Level 1 func 1" )
throw "MyError"
} catch( error ){
// Level 1 step 1 catch
print( "Level 1 onerror 1: " + error )
throw "NewError"
}
} catch( error ){
// Level 0 step 1 catch
print( "Level 0 onerror 1: " + error )
if ( error strequal "NewError" ) {
str_res = "Prm"
int_res = 123
array_res = [1, 2, 3]
bool_res = true
} else {
re-throw
}
}
{
// Level 0 step 2
print( "Level 0 func 2: " + str_res )
}Сразу видна максимальная мимикрия традиционного синхронного кода, что должно помогать в читаемости.
С точки зрения бизнес-логики со временем нарастает большой ком требований, но мы можем разделить его на легко понимаемые части. Описанное ниже, результат обкатки на практике на протяжении четырёх лет.
Базовые API времени выполнения:
add(func[, onerror])— имитацияtry-catch.success([args...])— явное указание успешного завершения:
- подразумевается по умолчанию,
- может передавать результаты на вход в следующий шаг.
error(code[, reason)— прерывание выполнения с ошибкой:
code— имеет строковой тип чтобы лучше интегрироваться с сетевыми протоколами в микросервисной архитектуре,reason— произвольное пояснение для человека.
state()— аналог Thread Local Storage. Предопределённые ассоциативные ключи:
error_info— пояснение последний ошибки для человека,last_exception— указатель на объект последнего исключения,async_stack— стек асинхронных вызовов на сколько позволяет технология,- остальное — задаётся пользователем.
Предыдуший пример уже с реальным С++ кодом и некоторыми дополнительными фичами:
#include <futoin/iasyncsteps.hpp>
using namespace futoin;
void some_api(IAsyncSteps& asi) {
asi.add(
[](IAsyncSteps& asi) {
std::cout << "Level 0 func 1" << std::endl;
asi.add(
[](IAsyncSteps& asi) {
std::cout << "Level 1 func 1" << std::endl;
asi.error("MyError");
},
[](IAsyncSteps& asi, ErrorCode code) {
std::cout << "Level 1 onerror 1: " << code << std::endl;
asi.error("NewError", "Human-readable description");
}
);
},
[](IAsyncSteps& asi, ErrorCode code) {
std::cout << "Level 0 onerror 1: " << code << std::endl;
if (code == "NewError") {
// Human-readable error info
assert(asi.state().error_info ==
"Human-readable description");
// Last exception thrown is also available in state
std::exception_ptr e = asi.state().last_exception;
// NOTE: smart conversion of "const char*"
asi.success("Prm", 123, std::vector<int>({1, 2, 3}, true));
}
}
);
asi.add(
[](IAsyncSteps& asi, const futoin::string& str_res, int int_res, std::vector<int>&& arr_res) {
std::cout << "Level 0 func 2: " << str_res << std::endl;
}
);
}API для создания циклов:
loop( func, [, label] )— шаг с бесконечно повторяемым телом.forEach( map|list, func [, label] )— шаг-итерация по объекту коллекции.repeat( count, func [, label] )— шаг-итерация указанное количество раз.break( [label] )— аналог традиционного прерывания цикла.continue( [label] )— аналог традиционного продолжения цикла с новой итерации.
Спецификация предлагает альтернативные названия breakLoop, continueLoop и прочие в случае конфликта с зарезервированными словами.
Пример C++:
asi.loop([](IAsyncSteps& asi) {
// infinite loop
asi.breakLoop();
});
asi.repeat(10, [](IAsyncSteps& asi, size_t i) {
// range loop from i=0 till i=9 (inclusive)
asi.continueLoop();
});
asi.forEach(
std::vector<int>{1, 2, 3},
[](IAsyncSteps& asi, size_t i, int v) {
// Iteration of vector-like and list-like objects
});
asi.forEach(
std::list<futoin::string>{"1", "2", "3"},
[](IAsyncSteps& asi, size_t i, const futoin::string& v) {
// Iteration of vector-like and list-like objects
});
asi.forEach(
std::map<futoin::string, futoin::string>(),
[](IAsyncSteps& asi,
const futoin::string& key,
const futoin::string& v) {
// Iteration of map-like objects
});
std::map<std::string, futoin::string> non_const_map;
asi.forEach(
non_const_map,
[](IAsyncSteps& asi, const std::string& key, futoin::string& v) {
// Iteration of map-like objects, note the value reference type
});API интеграции с внешними событиями:
setTimeout( timeout_ms )— вызывает ошибкуTimeoutпо истечению времени, если шаг и его поддерево не закончили выполнение.setCancel( handler )— устанавливает обработчик отмены, который вызывается при общей отмене потока и при разворачивании стека асинхронных шагов во время обработки ошибки.waitExternal()— простое ожидание внешнего события.
- Примечание: безопасно использовать только в технологиях со сборщиком мусора.
Вызов любой из этих функций делает необходимым явный вызов success().
Пример C++:
asi.add([](IAsyncSteps& asi) {
auto handle = schedule_external_callback([&](bool err) {
if (err) {
try {
asi.error("ExternalError");
} catch (...) {
// pass
}
} else {
asi.success();
}
});
asi.setCancel([=](IAsyncSteps& asi) { external_cancel(handle); });
});
asi.add(
[](IAsyncSteps& asi) {
// Raises Timeout error after specified period
asi.setTimeout(std::chrono::seconds{10});
asi.loop([](IAsyncSteps& asi) {
// infinite loop
});
},
[](IAsyncSteps& asi, ErrorCode code) {
if (code == futoin::errors::Timeout) {
asi();
}
});Пример ECMAScript:
asi.add( (asi) => {
asi.waitExternal(); // disable implicit success()
some_obj.read( (err, data) => {
if (!asi.state) {
// ignore as AsyncSteps execution got canceled
} else if (err) {
try {
asi.error( 'IOError', err );
} catch (_) {
// ignore error thrown as there are no
// AsyncSteps frames on stack.
}
} else {
asi.success( data );
}
} );
} );API интеграции с Future/Promise:
await(promise_future[, on_error])— ожидание Future/Promise как шаг.promise()— превращает весь поток выполнения в Future/Promise, используется вместоexecute().
Пример C++:
[](IAsyncSteps& asi) {
// Proper way to create new AsyncSteps instances
// without hard dependency on implementation.
auto new_steps = asi.newInstance();
new_steps->add([](IAsyncSteps& asi) {});
// Can be called outside of AsyncSteps event loop
// new_steps.promise().wait();
// or
// new_steps.promise<int>().get();
// Proper way to wait for standard std::future
asi.await(new_steps->promise());
// Ensure instance lifetime
asi.state()["some_obj"] = std::move(new_steps);
};API контроля потока выполнения бизнес-логики:
AsyncSteps(AsyncTool&)— конструктор, который привязывает поток выполнения к конкретному Event Loop.execute()— запускает поток выполнения.cancel()— отменяет поток выполнения.
Здесь уже требуется конкретная реализация интерфейса.
Пример C++:
#include <futoin/ri/asyncsteps.hpp>
#include <futoin/ri/asynctool.hpp>
void example() {
futoin::ri::AsyncTool at;
futoin::ri::AsyncSteps asi{at};
asi.loop([&](futoin::IAsyncSteps &asi){
// Some infinite loop logic
});
asi.execute();
std::this_thread::sleep_for(std::chrono::seconds{10});
asi.cancel(); // called in d-tor by fact
}прочие API:
newInstance()— позволяет создать новый поток выполнения без прямой зависимости на реализацию.sync(object, func, onerror)— то же, но с синхронизацией относительно объекта, реализующего соответствующий интерфейс.parallel([on_error])— специальныйadd(), подшаги которого представляют из себя отдельные потоки AsyncSteps:
- у всех потоков общий
state(), - родительский поток продолжает выполнения по завершению всех дочерних,
- не перехваченная ошибка в любом дочернем сразу отменяет все остальные дочерние потоки.
- у всех потоков общий
Примеры C++:
#include <futoin/ri/mutex.hpp>
using namespace futoin;
ri::Mutex mtx_a;
void sync_example(IAsyncSteps& asi) {
asi.sync(mtx_a, [](IAsyncSteps& asi) {
// synchronized section
asi.add([](IAsyncSteps& asi) {
// inner step in the section
// This synchronization is NOOP for already
// acquired Mutex.
asi.sync(mtx_a, [](IAsyncSteps& asi) {
});
});
});
}
void parallel_example(IAsyncSteps& asi) {
using OrderVector = std::vector<int>;
asi.state("order", OrderVector{});
auto& p = asi.parallel([](IAsyncSteps& asi, ErrorCode) {
// Overall error handler
asi.success();
});
p.add([](IAsyncSteps& asi) {
// regular flow
asi.state<OrderVector>("order").push_back(1);
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(4);
});
});
p.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(2);
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(5);
asi.error("SomeError");
});
});
p.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(3);
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(6);
});
});
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order"); // 1, 2, 3, 4, 5
});
};Стандартные примитивы для синхронизации
Mutex— ограничивает одновременное исполнение вNпотоков с очередью вQ, по умолчаниюN=1, Q=unlimited.Throttle— ограничивает количество входовNв периодPс очередью вQ, по умолчаниюN=1, P=1s, Q=0.Limiter— комбинацияMutexиThrottle, которая типично используется на входе обработки внешних запроса и при вызове внешних систем с целью устойчивой работы под нагрузкой.
В случае выхода за лимиты очереди, поднимается ошибка DefenseRejected, смысл которой ясен из описания Limiter.
Ключевые преимущества
Концепция AsyncSteps не была самоцелью, а родилась вследствие необходимости более контролируемого асинхронного выполнения программ с точки зрения лимита времени, отмены и в целом связности отдельных обратных вызовов. Ни одно из универсальных решений на тот момент и сейчас не предоставляет такой же функциональности. Поэтому:
Единая спецификация FTN12 для всех технологий — быстрая адаптация для разработчиков при переключение с одной технологии на другую.
Интеграция отмены setCancel() — позволяет отменять все внешние запросы и подчищать ресурсы ясным и безопасным способом при внешней отмене или появлении ошибки времени исполнения. Это избегает проблемы асинхронного выполнения тяжёлых задач, результат которых уже не требуется. Это аналог RAII и atexit() в традиционном программировании.
Непосредственно отмена выполнения cancel() — типично используется при отсоединении клиента, истечения максимального срока выполнения запроса или иных причин завершения. Это аналог SIGTERM или pthread_cancel(), оба из которых весьма специфичны в реализации.
Таймеры отмены шага setTimeout() — типично используется для ограничения общего времени выполнения запроса и для ограничения времени ожидания подзапросов и внешних событий. Действуют на всё поддерево, выкидывает перехватываемую ошибку "Timeout".
Интеграция с другими технологиями асинхронного программирования — использование FutoIn AsyncSteps не требует отказываться от уже используемых технологий и не требует разработки новых библиотек.
Универсальная реализация на уровне конкретного языка программирования — нет необходимости в специфичных и потенциально опасных с изменениями ABI манипуляциях на уровне машинного кода, которые требуются для сопрограмм. Хорошо подходит для Embedded и безопасно на неполноценных MMU.

К цифрам
Для тестов используется Intel Xeon E3-1245v2/DDR1333 с Debian Stretch и последним обновлением микрокода.
Сравниваются пять вариантов:
- Boost.Fiber с
protected_fixedsize_stack. - Boost.Fiber с
pooled_fixedsize_stackи выделением на общей куче. - FutoIn AsyncSteps в стандартном исполнении.
- FutoIn AsyncSteps в динамически отключенным пулом памяти (
FUTOIN_USE_MEMPOOL=false).
- приведено лишь для свидетельства эффективности
futoin::IMemPool.
- приведено лишь для свидетельства эффективности
- FutoIn NitroSteps<> — альтернативная реализация со статическим выделением всех буферов во время создания объекта.
- конкретные параметры лимитов задаются в виде продвинутых параметров шаблона.
Ввиду функциональной ограниченности Boost.Fiber сравниваются следующие показатели производительности:
- Последовательное создание и выполнение 1 млн. потоков.
- Параллельное создание потоков с лимитом в 30 тыс. и исполнение 1 млн. потоков.
- ограничение в 30 тыс. исходит из потребности вызывать
mmap()/mprotect()дляboost::fiber::protected_fixedsize_stack. - большая цифра так же выбрана для давления на кэш процессора.
- ограничение в 30 тыс. исходит из потребности вызывать
- Параллельное создание 30 тыс. потоков и 10 млн. переключений в ожидании внешнего события.
- в обоих случаях "внешнее" событие удовлетворяется в отдельном потоке в рамках той же технологии.
Используется одно ядро и один "железный" поток, т.к. это позволяет добиться максимальной производительности, исключая гонки на спинлоках и атомарных операциях. Наилучшие значения из серии тестов идут в результат. Проверяется стабильность показателей.
Сборка сделана с GCC 6.3.0. Результаты с Сlang и tcmalloc также проверялись, но различия несущественны для статьи.
Исходный код тестов доступен на GitHub и GitLab.
1. Последовательное создание
| Технология | Время | Гц |
|---|---|---|
| Boost.Fiber protected | 4.8s | 208333.333Hz |
| Boost.Fiber pooled | 0.23s | 4347826.086Hz |
| FutoIn AsyncSteps | 0.21s | 4761904.761Hz |
| FutoIn AsyncSteps no mempool | 0.31s | 3225806.451Hz |
| FutoIn NitroSteps | 0.255s | 3921568.627Hz |
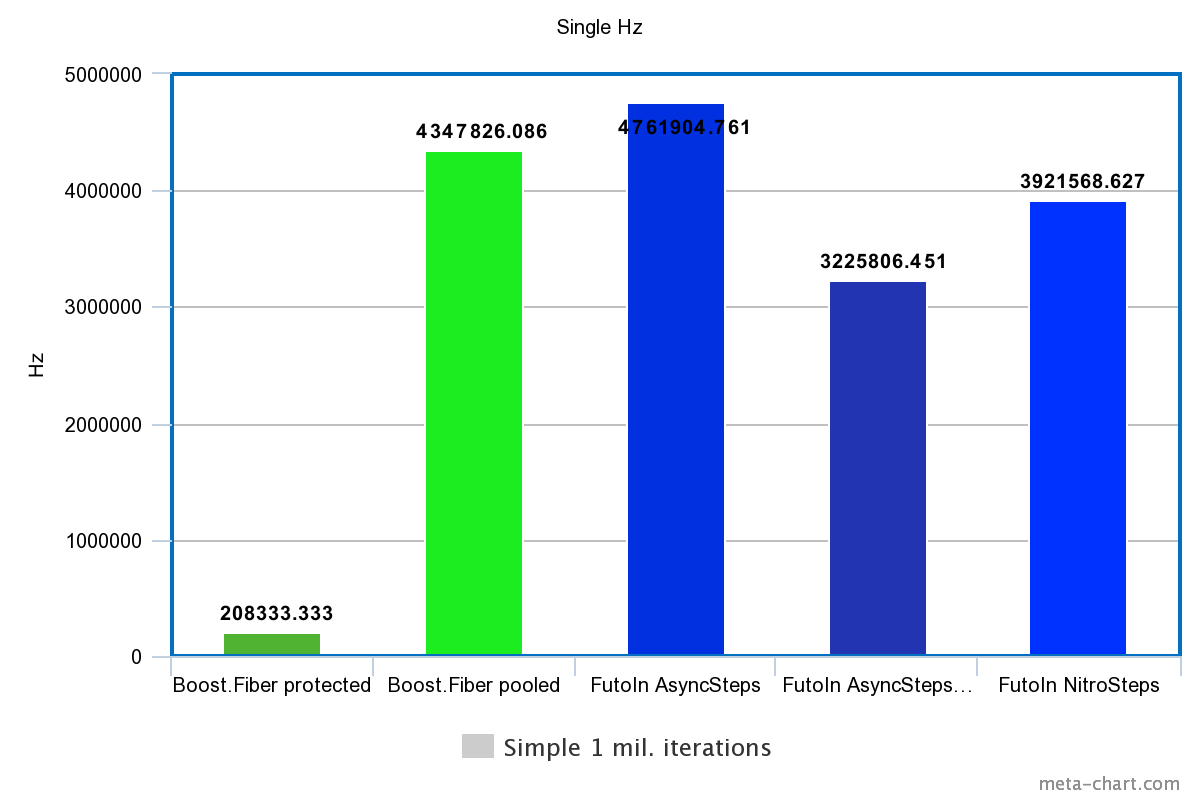
Больше — лучше.
Здесь основная потеря у Boost.Fiber из-за системных вызовов работы со страницами памяти, но даже менее безопасный pooled_fixedsize_stack оказывается более медленным, чем стандартная реализация AsyncSteps.
2. Параллельное создание и исполнение
| Технология | Время | Гц |
|---|---|---|
| Boost.Fiber protected | 6.31s | 158478.605Hz |
| Boost.Fiber pooled | 1.558s | 641848.523Hz |
| FutoIn AsyncSteps | 1.13s | 884955.752Hz |
| FutoIn AsyncSteps no mempool | 1.353s | 739098.300Hz |
| FutoIn NitroSteps | 1.43s | 699300.699Hz |
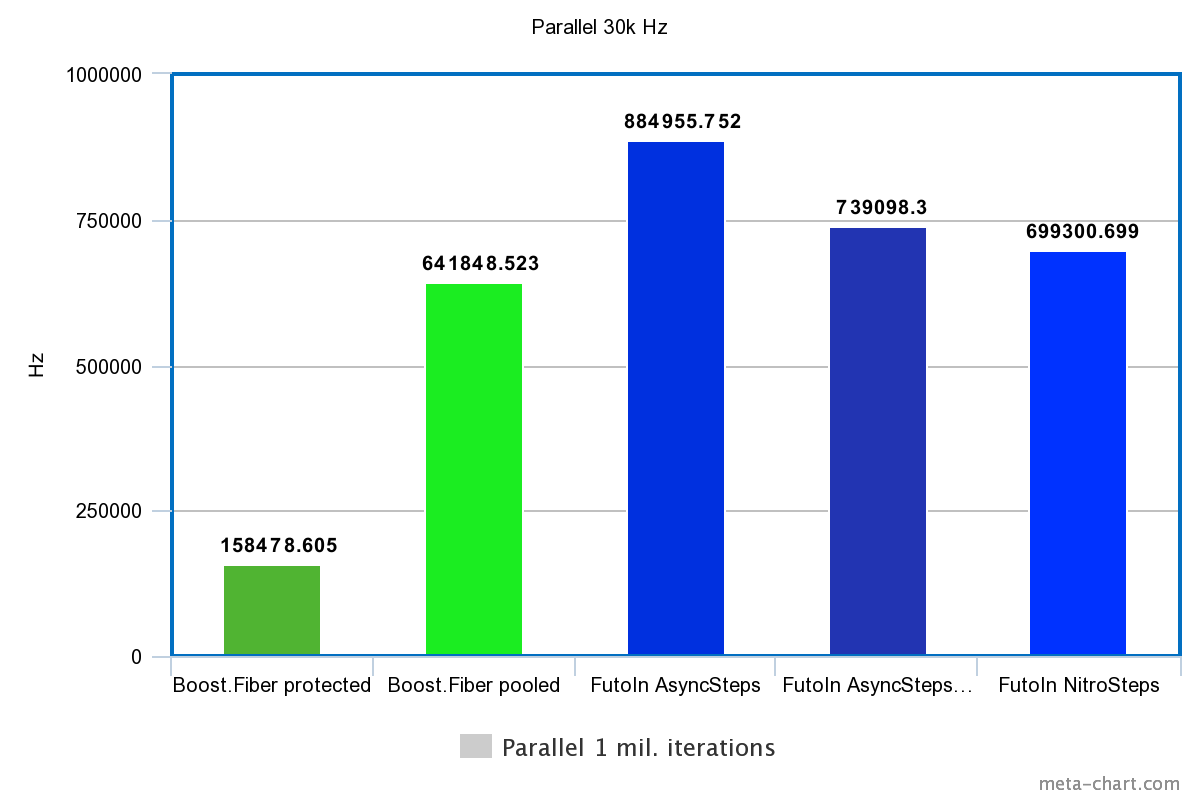
Больше — лучше.
Здесь те же проблемы, но мы видим значительное замедление по сравнению с первым тестом. Нужен более детальный анализ, но теоретическая догадка указывает на неэффективность кэширования — выборочные значения количества параллельных потоков дают картину функции с множеством явных изломов.
3. Параллельные циклы
| Технология | Время | Гц |
|---|---|---|
| Boost.Fiber protected | 5.096s | 1962323.390Hz |
| Boost.Fiber pooled | 5.077s | 1969667.126Hz |
| FutoIn AsyncSteps | 5.361s | 1865323.633Hz |
| FutoIn AsyncSteps no mempool | 8.288s | 1206563.706Hz |
| FutoIn NitroSteps | 3.68s | 2717391.304Hz |
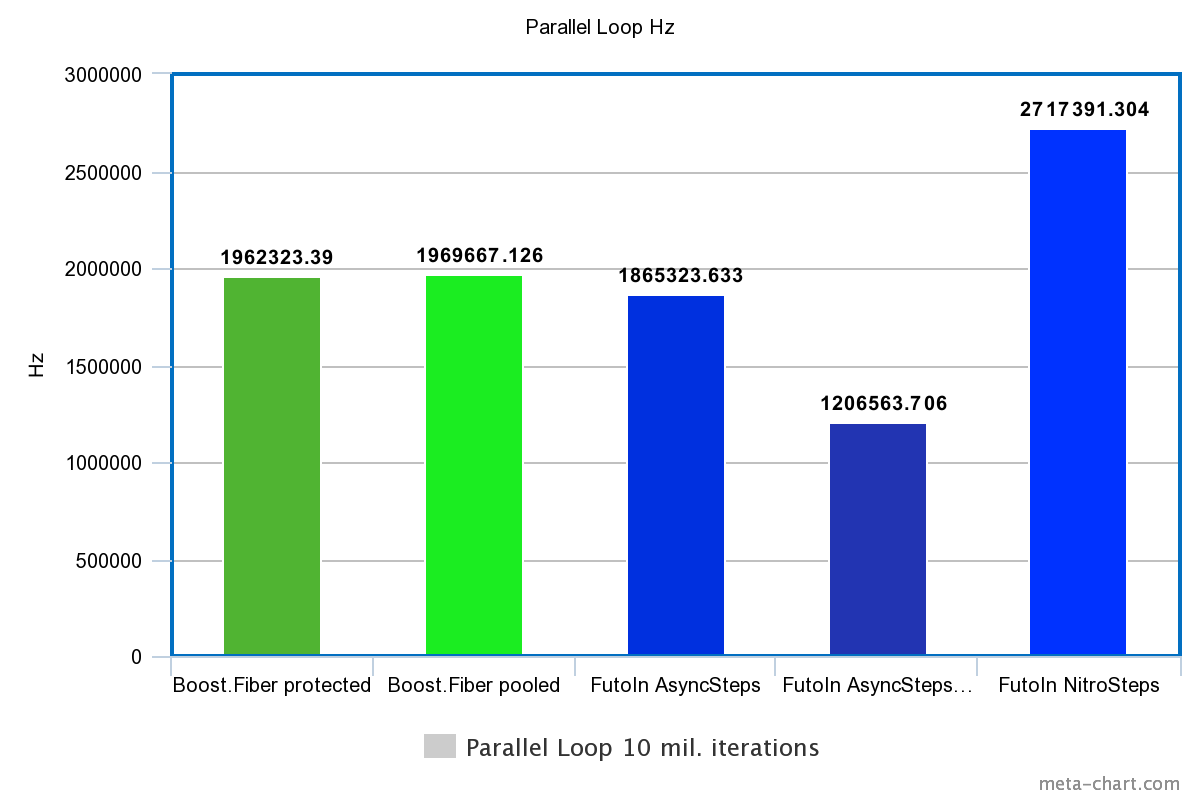
Больше — лучше.
Убирая оверхед создания, мы видим что в голом переключении потоков Boost.Fiber начинает выигрывать у стандартной реализации AsyncSteps, но значительно проигрывает NitroSteps.
Использование памяти (по RSS)
| Технология | Память |
|---|---|
| Boost.Fiber protected | 124M |
| Boost.Fiber pooled | 505M |
| FutoIn AsyncSteps | 124M |
| FutoIn AsyncSteps no mempool | 84M |
| FutoIn NitroSteps | 115M |
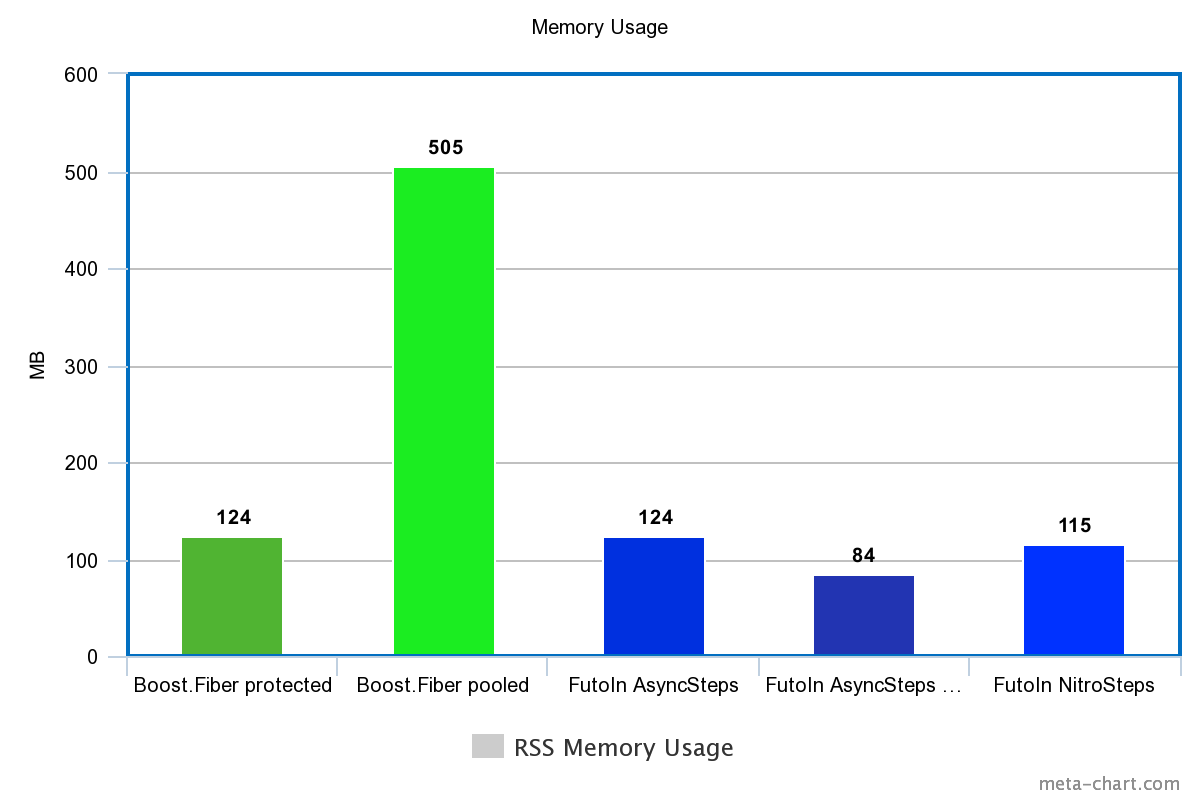
Меньше — лучше.
И снова, Boost.Fiber нечем гордиться.
Бонус: тесты на Node.js
Всего два теста так же из-за ограниченности Promise: создание+выполнение и циклы по 10 тыс. итераций. Каждый тест 10 секунд. Берутся средние значения в Гц второго прохода после оптимизирующего JIT при NODE_ENV=production, используя пакет @futoin/optihelp.
Исходный код так же на GitHub и GitLab. Используются версии Node.js v8.12.0 и v10.11.0, установленные через FutoIn CID.
| Tech | Simple | Loop |
|---|---|---|
| Node.js v10 | ||
| FutoIn AsyncSteps | 1342899.520Hz | 587.777Hz |
| async/await | 524983.234Hz | 630.863Hz |
| Node.js v8 | ||
| FutoIn AsyncSteps | 682420.735Hz | 588.336Hz |
| async/await | 365050.395Hz | 400.575Hz |
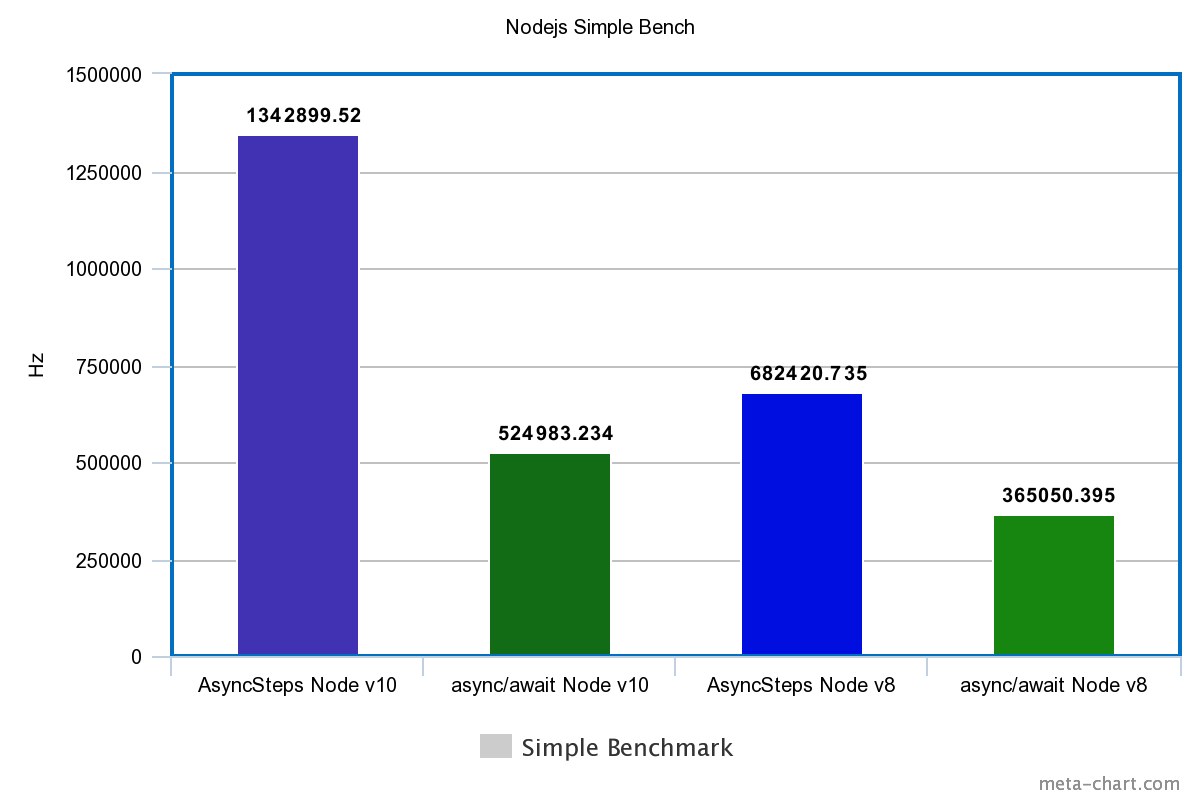
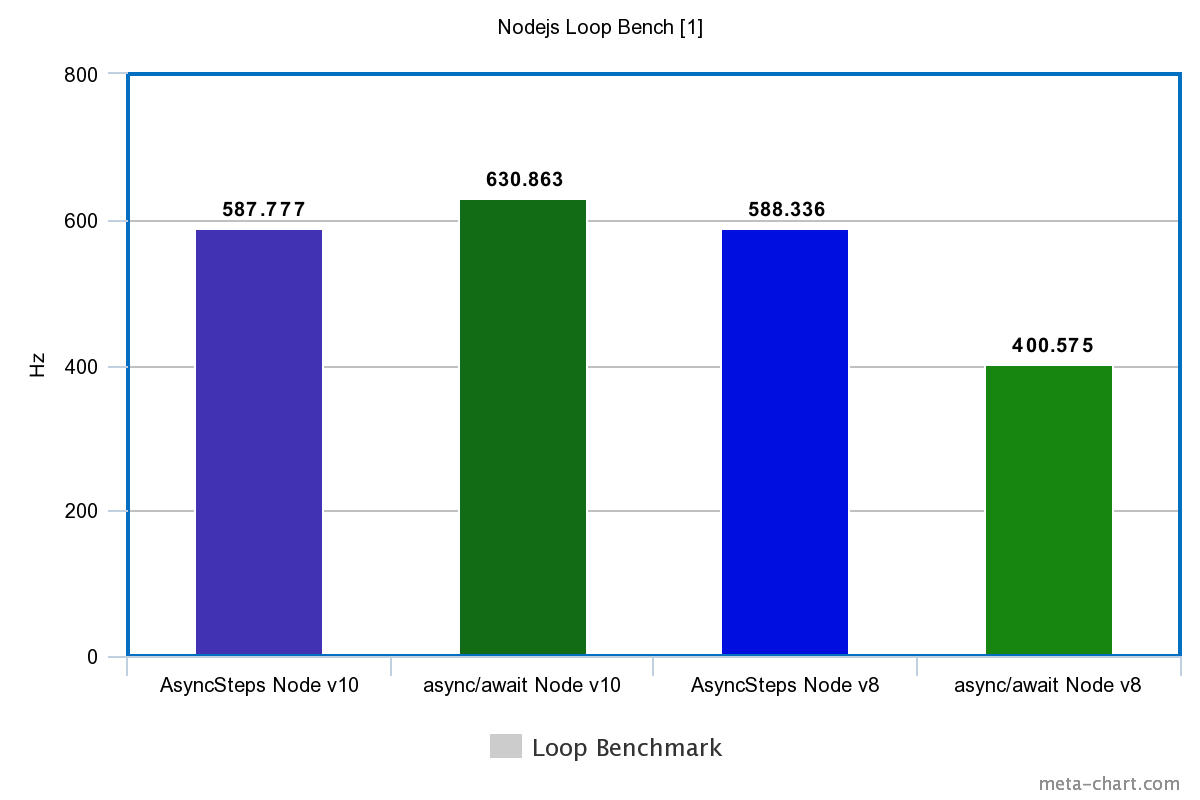
Больше — лучше.
Внезапный разгром async/await? Да, но в V8 для Node.js v10 подтянули оптимизацию циклов и стало чуть лучше.
Стоит добавить, что реализация Promise и async/await блокирует Node.js Event Loop. Бесконечный цикл без ожидания внешнего события попросту повесит процесс (пруф), но с FutoIn AsyncSteps такого не случается.
Периодический выход из AsyncSteps в Node.js Event Loop и есть причина ложной победы async/await в тесте-цикле на Node.js v10.
Оговорюсь, что сравнивать показатели производительности с С++ будет некорректно — разная реализация методологии тестирования. Для приближения, результаты тестирования циклов Node.js нужно умножить на 10 тыс.
Выводы
На примере C++, FutoIn AsyncSteps и Boost.Fiber показывают схожую длительную производительность и потребление памяти, а вот на запуске Boost.Fiber серьёзно проигрывает и ограничен системными лимитами по количеству mmap()/mprotect.
Максимальная производительность зависит от эффективного использования кэша, но в реальной жизни данные бизнес-логики могут оказывать большее давление на кэш, чем реализация сопрограмм. Вопрос полноценного планировщика остаётся открытым.
FutoIn AsyncSteps для JavaScript превосходит async/await в производительности даже в последней версии Node.js v10.
В конечном счёте, основная нагрузка должна быть непосредственно от бизнес-логики, а не от реализации концепции асинхронного программирования. Поэтому незначительные отклонения не должны быть существенным аргументом.
Разумно написанная бизнес-логика внедряет асинхронные переходы только когда подразумевается ожидание внешнего события в любом виде или когда объём обрабатываемых данных слишком велик и на долго блокирует "железный" поток выполнения. Исключение из этого правила — написание библиотечных API.
Заключение
Принципиально, интерфейс FutoIn AsyncSteps проще, понятнее и более функционален чем любые из конкурентов без "сахара" async/await. Вдобавок, он реализован стандартными средствами и унифицирован для всех технологий. Как и в случае с Promise из ECMAScript, AsyncSteps может получить свой "сахар" и его поддержку в компиляторах или средах выполнения практически любого языка.
Замеры производительности не сильно оптимизированной реализации показывают сравнимые и даже превосходящие результаты относительно альтернативных технологий. Гибкость возможной реализации доказана двумя разными подходами AsyncSteps и NitroSteps для единого интерфейса.
Помимо уже указанной выше спецификации, есть ориентированная на разработчика-пользователя документация.
По запросам возможна реализация версии для Java/JVM или любого другого языка с адекватными анонимными функциями — иначе читаемость кода падает. Любая помощь проекту приветствуется.
Если вам действительно нравится такая альтернатива, то не стесняйтесь поставить звёздочки на GitHub и/или GitLab.
