«Восьмерка» еще даже не вышла RTM а я уже пишу про нее пост. Зачем? Ну, основная идея что тот, кто предупрежден — вооружен. Так что в этом посте будет про то что известно на текущий момент, а если это все подстава, ну, поделом.
Nullable Reference Types
Я не знаю, в курсе вы или нет, но дизайнеры всех современных языков «продолбали» как минимум несколько важных аспектов. Один из основных продолбов — это неинициализированные объекты, указатель на которые имеет значение NULLnullptrnull
C# это конечно тоже зацепило в разных ипостасях, вот например:
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
public string MiddleName { get; set; }
public Person(string first, string last, string middle) =>
(FirstName, LastName, MiddleName) = (first, last, middle);
public string FullName =>
$"{FirstName} {MiddleName[0]} {LastName}";
}
Пример выше очень хорошо иллюстрирует проблему. У человека может быть отчество но у меня, например, в паспорте его нет и следовательно непонятно что писать в это поле. Дефолтное значение строки в C# это null$string.Format()null
Кардинального решения этой проблемы нет, т.к. если внезапно запретить nullOptional
Системы статического анализа вроде Решарпера уже давно пытаются как-то облегчить участь разработчика, предупреждая о возможных косяках. Собственно для этого придумали аннотации (NuGet пакет JetBrains.Annotations
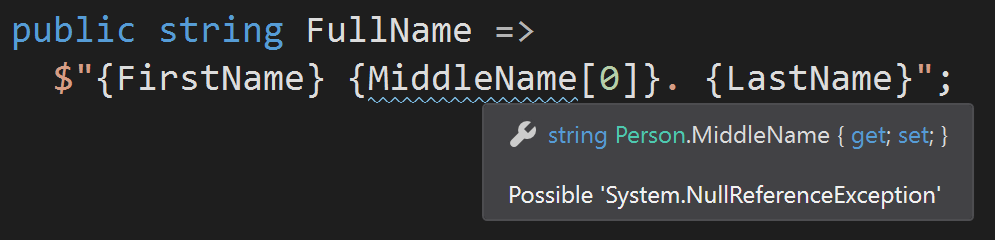
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
[CanBeNull] public string MiddleName { get; set; }
public Person(string first, string last, [CanBeNull] string middle) =>
(FirstName, LastName, MiddleName) = (first, last, middle);
public string FullName =>
$"{FirstName} {MiddleName[0]} {LastName}";
}
Код выше заставляет системы статического анализа ругаться на возможный NRE в точке MiddleName[0]
Но Microsoft… как всегда берет то, что делает другие и банально копирует. Вообще есть шутка, что в долгосрочной перспективе VS просто скопирует все фичи Решарпера. А потом запретит плагины. Поэтому хорошо что есть райдер.
Короче, МС естественно не стали менять язык. Точнее как не стали, они конечно его поменяли. Вместо решарперных аннотаций, в C#8 можно написать вот так:
#nullable enable
Просто написав от эту штуку наверху файла вы меняете поведения компилятора. Теперь, при написании чего-то вроде
var p = new Person("Dmitri", "Nesteruk", null);
вы получите следующий warning:
1>NullableReferenceTypes.cs(26,48,26,52): warning CS8625: Cannot convert null literal to non-nullable reference or unconstrained type parameter.
Да-да, просто предупреждение, а не ошибку (хотя treat warnings as errors никто не отменял).
Ну да ладно, а что дальше? А дальше нам хочется как-то все-таки сказать C#, что теоретически MiddleNamenull[0]
Для этого мы меняем поле на вот такое:
public string? MiddleName;
Хмм, что это? Кому-то может показаться что string?Nullable<T>T : structstring
Теперь компилятор выдаст вам еще один варнинг на доступ по индексу ноль. И чтобы оно заработало вам придется как-то перестраховаться, например написав:
public string FullName => $"{FirstName} {MiddleName?[0]} {LastName}";
Теперь самый важный вопрос: что же поменялось в IL? С точки зрения исполняемого кода — ничего! Но с точки зрения метаданных поменялось конечно: теперь в типе который использует nullable аннотации все типы которые являются nullable проаннотированы атрибутом [Nullable]
Чувствительность к проверкам
Аннотации в C#8 работают в какой-то мере как Котлиновские смарт-касты. Иначе говоря, если у меня есть апи который выдает nullable-тип
string? s = GetString();
То конечно при попытке достучаться до первой буквы я получу warning. Но если я напишу так:
if (s != null){ char c = s[0];}
то варнингов не будет! Компилятор понимает, что мы сами сделали проверку и поэтому не стоит лишний раз волноваться. Насколько глубоко компилятор копает подобные сценарии я не проверял.
Предотвращение лишних проверок
Есть два способа отключить проверки на null. Первый — это просто писать код без «вопросиков», тем самым констатировав тот факт что все твои поля, параметры и так далее вообще ни при каких условиях null-ами быть не могут.
Второй подход — это явно сказать компилятору что в этой точке проверка не нужна. Вот несколько примеров:
(null as Person).FullName(null as Person)!.FullName(null as Person)!!!!!!!!!!!!!.FullName(null as Person)!?.FullNamenull?!
Проверки в либах
Естественно, то вся эта кухня имеет хоть какой-то смысл только при условии что BCL и прочие популярные библиотеки проаннотированны этими аннотациями. Ведь сейчас я могу написать
Type t = Type.GetType("abracadabra");Console.WriteLine(t.Name);
и не получить никакого предупреждения. Я-то знаю что Type.GetType()nullnullable
И нет, мы не можем «форсировать» подобные проверки кодом вроде
Type t = Type.GetType("abracadabra");
Type? u = t;
Console.WriteLine(u.Name);
Код выше все равно не выдаст предупреждение. Очевидно, компилятор считает что t != nullunull
Итого
Nullable reference types — сомнительной полезности фича, которую еще рано использовать. Оригинальности в ней мало. В долгосрочной перспективе она, конечно, должна помочь нам как-то бороться с рисками nullability но глобально она проблему, как вы понимаете, не решает.
Индексы и Диапазоны
На матстатистке есть такое хороше упражнение: брать диапазон чисел, обладающих тем или иным распределением, преобразовывать его, и потом считать статистику по результату. Например, если X~N(0,1), чему равны E[X²] и V[X²]?
Диапазоны это очень хорошо, но дизайнерами сишарпа явно хотелось получить диапазоны в стиле Питона, а для этого пришлось ввести понятие «с конца».
Итак, у нас за кулисами появляются два новых типа: IndexRange
Index
Вы никогда не задумывались, почему это индекс в массив обязательно intuintx[-1]
Некоторые языки позволяют брать элементы массива с конца с помощью отрицательных индексов. Но это немного криво т.к. последний элемент получит индекс -1 в связи с тем, что у нас нет понятия положительного и отрицательного нуля, нуль один.
В C# пошли другим путем и ввели новый синтаксис. Но, все по порядку. Для начала, ввели новый тип под названием Index
Index i0 = 2; // implicit conversion
Индекс выше, как вы понимаете, будет ссылаться на третий элемент с начала той или иной коллекции.
У самого типа Index
ValueIsFromEnd
Структуру можно инициализировать просто вызвав конструктор:
Index i1 = new Index(0, false);
Код выше, как вы поняли, берет первый элемент с начала. А вот последний элемент (то есть нулевой, но с конца) можно взять вот так:
var i2 = ^0; // Index(0, true)
Опаньки! Многие из вас наверное хотели, чтобы оператор ^
Встроенные типы, такие как массивы или строки, конечно же поддерживают индексер (operator this[]Index
var items = new[] { 1, 2, 3, 4, 5 };
items[^2] = 33; // 1, 2, 33, 4, 5
Range
Следующий кусочек этого паззла — это тип Range
X..Y
Что означает «все элементы от X включительно до Y». При этом, включает ли диапазон значение с индексом YY
Итак, вот несколько примеров:
var a = i1..i2; // Range(i1, i2)var b = i1..; // Range(i1, new Index(0, true));i1var c = ..i2; // Range(new Index(0, false), i2)i2var e = ..;Range.ToEnd(2);
Включается ли конечный элемент?
Окей, знаете что в С++ толстым слоем разбросано неопределенное поведение (undefined behavior?). Ну так вот, в реализации Range
Представьте массив x = {1, 2, 3}x[0..2]{1, 2}x[..2]x[..]{1, 2, 3}
Это немного выносит мозг т.к. элементы x[2]x[^1]Range
Еще немного семантики
Во-первых, диапазон X..YX <= YArgumentOutOfRangeException
Во-вторых, «шаг» не включен в спеку, то есть нельзя написать 1..2..100
Range
В массивах, он дает копию подмассива, прям копируя каждый элемент
В строках происходит вызов
Substring()На коллекциях можно вызывать
AsSpan()RangeВ
SpanRangeSpan.Slice()
Конечно, вы можете также запилить поддержку Index/Rangeoperator this[]
Итого
Полезные в целом фичи, которые являются просто слоем синтаксического сахара который компилятор разворачивает в инициализацию разных struct
И да, решарпероводам будет много всяких веселых инспекций:
Default Interface Members
Никто не рискует породить столько ненависти сколько реализация дефолтных интерфейс мемберов, то есть бархатное преврашение интрефейсов в абстрактные классы. И первый вопрос, на который нужно ответить — зачем?
Ну типичная мотивация такая. Вот допустим вы хотите сделать Enumerable.Count()while (x.MoveNext())Count()
if (x is IList<T> list)
return list.Count;
Логично? А как насчет IReadOnlyList<T>
Ситуация, приведенная выше наводит нас на вынужденное, очень грубое нарушение open-closed principle да и других принципов SOLID, т.к. делать проверки на все возможные типы ради оптимизации — это провальная затея.
А что можно сделать? Ну, можно было бы, чисто теоретически, как-то взять и добавить реализацию Count()IReadOnlyList<T>IReadOnlyList<T>.Count()IEnumerable<T>.Count()
Именно этот подход и реализуют дефолтные методы интерфейсов. Они позволяют реализовать нечто, функционально-эквивалентное экстеншн-методам, но также поддающееся правилам наследования и виртуальных вызовов.
Тонкости использования
Но давайте для начала посмотрим на более приземленный пример:
public interface IHuman
{
string Name { get; set; }
public void SayHello()
{
Console.WriteLine($"Hello, I am {Name}");
}
}
public class Human : IHuman
{
public string Name { get;set; }
}
Пример выше искусственнен, но обязателен для понимания того, что вот так писать нельзя:
Human human = new Human() { Name = "John" };
human.SayHello(); // will not compile
Странно да? Вроде бы, валидный код. На самом деле нет — дело в том, что конкретный класс, хоть он и реализует тот или иной интерфейс, понятия не имеет о дефолтных методах этого интерфейса.
Почему, спросите вы? Потому, что вся соль этих методов в том, чтобы добавлять их пост фактум, когда вашим интерфейсом уже пользуются. А что если за это время класс HumanSayHello()
Поэтому дизайнеры приняли такое решение: дефолтные методы доступны только через сам интерфейс, то есть требуется явное или неявное приведение типа к интерфейсу:
IHuman human = new Human() { Name = "John" };
human.SayHello();
((IHuman)new Human { … }).SayHello();
Наследование интерфейсов
Все, что я описал выше, наводит нас на интересную мысль: если два интерфейса реализуют одинаковый метод Foo()Foo()
public interface IHuman
{
string Name { get; set; }
void SayHello()
{
Console.WriteLine($"Hello, I am {Name}");
}
}
public interface IFriendlyHuman : IHuman
{
void SayHello()
{
Console.WriteLine( $"Greeting, my name is {Name}");
}
}
((IHuman)new Human()).SayHello();
// Hello, I am John
((IFriendlyHuman)new Human()).SayHello();
// Greeting, my name is John
Заметьте, что в коде выше IFriendlyHuman.SayHello()IHuman.SayHello()SayHello()
public interface IFriendlyHuman : IHuman
{
void IHuman.SayHello()
// ↑↑↑↑↑↑
{
Console.WriteLine( $"Greeting, my name is {Name}");
}
}
Вот в этом случае вызов SayHello()IHumanIFriendlyHuman
((IHuman)new Human()).SayHello();
Greeting, my name is John
((IFriendlyHuman)new Human()).SayHello();
Greeting, my name is John
Diamond Inheritance
Естественно, в ситуации когда вы можете иметь два «честных override-а» в двух интерфейсах-наследниках породит конфликт в случае, если вы попытаетесь реализовать их оба:
interface ITalk { void Greet(); }
interface IAmBritish : ITalk
{
void ITalk.Greet() => WriteLine("Good day!");
}
interface IAmAmerican : ITalk
{
void ITalk.Greet() => WriteLine("Howdy!");
}
class DualNational : IAmBritish, IAmAmerican {}
// Error CS8705 Interface member 'ITalk.Greet()' does not have a most specific implementation. Neither 'IAmBritish.ITalk.Greet()', nor 'IAmAmerican.ITalk.Greet()' are most specific.
Проблема тут в том, что компилятор не может найти «более специфичный» (то есть, ниже в иерархии наследования) интерфейс для использования и, в результате равнозначности, не поймет что нужно делать если кто-то вызовет какой-нибудь IAmAmerican.Greet()
Итого
Фича для писателей АПИ. Обычным пользователям скорее всего не стоит беспокоиться, особенно если вы, как я, контролируете весь свой код и вам не страшно в любой момент менять его API. Единственный реальный кейс — это когда вот прям нужно оверрайдить экстеншн-методы. У вас есть подобные юз-кейсы?
Pattern Matching
Эту фичу нагло крадут из F# уже на протяжении нескольких минорных релизов. Конечно — в F# ведь эта фича очень удобна, но она идет рука об руку с теми фичами, которых в С# нет, а именно алгебраические типы и функциональные списки.
Но несмотря на это, аналогом F#ного matchswitch
Property Matching
Если у объекта есть поля или свойства, можно мэтчить по ним:
struct PhoneNumber{
public int Code, Number;
}
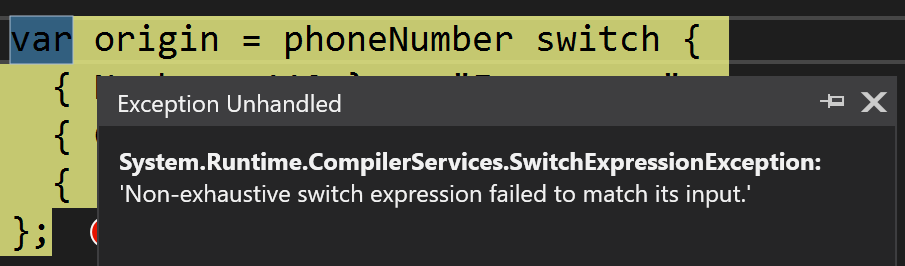
var phoneNumber = new PhoneNumber();
var origin = phoneNumber switch {
{ Number: 112 } => "Emergency",
{ Code: 44 } => "UK"
};
Код выше анализирует структуру объекта phoneNumber
Несмотря на всю лаконичность, код выше — бажный, так как не отлавливает все кейсы. У дизайнеров было два выбора: либо молча сглатывать неохват паттерна делая default-init (иначе говоря, возвращать default(T)
Ну и системы статического анализа кода тоже в долгу не останутся:

Загадка
Поскольку мы можем между фигурных скобок анализировать все что угодно, мы можем сделать и кейс, где фигурные скобки пустые:
var origin = phoneNumber switch {
{ Number: 112 } => "Emergency",
{ Code: 44 } => "UK",
{ } => "Indeterminate",
_ => "Missing"
};
Что это значит? Да то, что теперь есть 2 кейса: _{}null
Пример выше определенно покрывает все кейсы, так что исключение мы на нем не словим. А что насчет вот такого?
var origin = phoneNumber switch {
{ Number: 112 } => "Emergency",
{ Code: 44 } => "UK",
{ } => "Unknown"
};
Покрывает ли пример выше все варианты? Если phoneNumberstructclassnull
Вот и получается, что покрытие всех вариантов зависит не только от типа объекта но еще и от контекста компилятора.
Рекурсивные паттерны
Все-таки с неймингом у МС получается ооочень плохо, прям фееричный булшит. Сначала nullable reference types — масло масляное, ибо референсные типы являются nullable по определению, но термин recursive patterns — это еще на порядок хуже.
В F#, поскольку там есть функциональные списки, можно рекурсивно проверять подсписки списка на соответствие паттернам. В C# же, этот термин значит совсем другое, причем как я уже сказал, нейминг этой фичи в C# — просто шлак.
Если коротко, «рекурсивные паттерны» в C# это возможность углубиться внутри структуры того или иного объекта и проверить еще и поля-полей, если так можно выразиться:
var personsOrigin = person switch {
{ Name: "Dmitri" } => "Russia",
{ PhoneNumber: { Code: 46 } } => "Sweden",
{ Name: var name } => $"No idea where {name} lives"
};
В примере выше проиллюстрированы сразу две идеи. Первая — это то, что можно углубиться в объект person.PhoneNumberCode46
Валидация
Хорошее применение всей этой кухне: комплесная валидация разных аспектов одного сложного объекта в одном switch
var error = person switch {
null => "Object missing",
{ PhoneNumber: null } => "Phone number missing entirely",
{ PhoneNumber: { Number: 0 } } => "Actual number missing",
{ PhoneNumber: { Code: var code } } when code < 0 => "WTF?",
{ } => null // no error
};
if (error != null)
throw new ArgumentException(error);
Как видите, в коде выше идет несколько проверок: простые проверки с паттернами, плюс ключевое слово when
Интеграция с проверками на типы
Проперти-паттерны можно «поженить» с проверками на типы которые появились одним сишарпом ранее. Теперь можно проверить на тип, а потом еще и распаковать структуру:
IEnumerable<int> GetMainOfficeNumbers()
{
foreach (var pn in numbers)
{
if (pn is ExtendedPhoneNumber { Office: "main" })
yield return pn.Number;
}
}
В примере выше мы сначала проверяем тип номера телефона и, если он подходит, распаковываем его и проверяем что речь идет именно про главный офис. Очень удобно.
Деконструкция
Надеюсь вы не забыли про деконструкцию — фичу языка которая позволяет, по сути, распаковывать тип в кортеж. Для этого тип должен реализовывать метод Deconstruct()out
Так вот, эту фичу тоже можно поженить с паттерн-мэтчингом и получить следующее:
var type = shape switch
{
Rectangle((0, 0), 0, 0) => "Point at origin",
Circle((0, 0), _) => "Circle at origin",
Rectangle(_, var w, var h) when w == h => "Square",
Rectangle((var x, var y), var w, var h) =>
$"A {w}×{h} rectangle at ({x},{y})",
_ => "something else"
};
Код выше распаковывает содержимое прямоугольника или круга в кортежные структуры, при этом есть варианты: либо заниматься паттерн-мэтчингом, либо просто деструктурировать объекты в переменные, как показано в последнем примере. Заметьте что этот процесс тоже является «рекурсивным» — у прямоугольника есть точка начала, которая деструктурируется в круглых скобках. Прочерк (_
Итого
Нужные и полезные возможности, которые найдут свое применение. Валидация и похожий анализ типов становится очень лаконичным.
Заключение
Что, я не все фичи показал? Ну, я и не обещал, вообщем-то. Для начала хватит. Пока язык не релизнули я могу еще чуток поисследовать. А если и вы хотите поисследовать, вам потребуется VS 2019 Preview (да-да, preview версия а не RTM), .NET Core 3 (многое из описанного выше попросту не поддерживается в .NET Framework), ну и dotPeek тоже будет полезен чтобы понять, что же там за кулисами.
У меня пока все. Продолжение (возможно) следует. ■
