Предлагается взглянуть на dataset постов с pikabu.ru c точки зрения датастатистики. Сам датасет в составе 450к штук собран лучшими круглосуточными парсерами, обработан отдушками, убирающими дубликаты статей, а также нашпигован дополнительными столбцами, смысл наличия которых доступен только посвященным. Здесь не столько интересен сам датасет, сколько подход к анализу подобных сайтов. В последующих постах попробуем применить элементы из maсhine learning для анализа.

Работу с датасетом можно вести как в обыкновенном excel, так и jupyter notebook, поля данных разделены табуляцией. Мы остановимся на последнем варианте, и все команды будут приводиться с учетом того, что работа ведется в jupyter notebook.
Будем работать в windows. Поэтому зайдем, используя cmd в папку со скачанным датасетом и запустим jupyter notebook одноименной командой.
Далее импортируем модули.
Так как датасет не содержит заголовков, обозначим их перед загрузкой датасета:
Здесь все наглядно: название статьи, ссылка на нее, id статьи, рейтинг (количество плюсов), дата статьи, количество комментариев, id автора, мета рейтинг статьи, имя автора, ссылка на автора, ссылка на комьюнити.
Считаем датасет.
Здесь проведена небольшая оптимизация значений при считывании, чтобы некоторые столбцы были представлены как числовые.
Итак, датасет представляет 468595 строк,11 столбцов.
Первые 5 записей

Статистическое описание:

Несмотря на то, что парсеры работали не покладая рук, в датасете есть небольшие дыры, иными словами технологические отверстия, представленные пропусками. Данные пропуски в pandas попадают со значением NaN. Посмотрим количество строк с такими пустотами:
Как это выглядит на датасете:

1444 строки с пропусками общей картины не портят, но, все таки, избавимся от них:
Проверяем, что удаление прошло успешно:
Посмотрим названия колонок

Выберем первую колонку

Взглянем на минимум в датасете
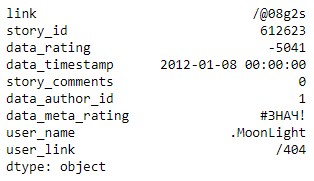
Максимум

То же самое более наглядно:

Теперь соберем значения из интересных столбцов в массив:
Можно посмотреть на один из столбцов массива:
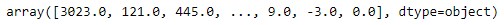
Посмотрим на количество статей с рейтингом более 10000:
Только 2672 статей имеют сверхвысокий рейтинг из 450к
Сначала импортируем модуль:
Выясним если связь между id автора статьи и рейтингом статьи?
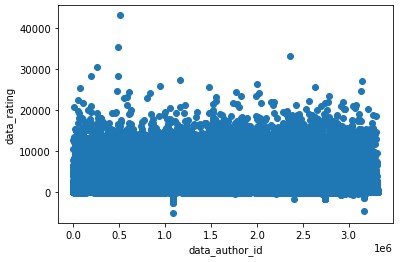
Из-за большого количества данных сложно уловить взаимосвязь и, скорее всего, она отсутствует.
Если связь между id статьи и рейтингом статьи?

Здесь заметно, что посты с более высоким номером (более поздние посты) получают больший рейтинг, за них чаще отдают голоса. Растет популярность ресурса?
Если связь между датой статьи и рейтингом?

Также видна взаимосвязь между более поздними публикациями и рейтингом постов. Более качественный контент или опять же просто рост посещаемости ресурса?
Если связь между рейтингом статьи и количеством комментов к ней?

Здесь прослеживается линейная зависимость, хотя она сильно распылена. Логика определенная есть, чем выше рейтинг поста, тем больше комментов.
Посмотрим на топ авторов (авторов, суммарный рейтингов постов которых максимален):

Добавим наглядности:

Построим графики, используя столбцы с id постов, их рейтингом и комментариями, сохраним результат в .png:

Сгруппируем данные по дате и суммарному рейтингу статей на эту дату:

Посмотрим, сколько статей всего выходило на определенную дату (месяц):

Склеим две таблицы:

Теперь нарисуем, используя plotly:
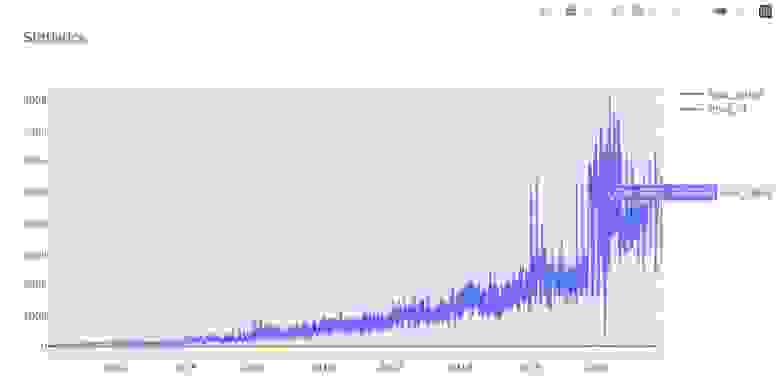
Прелесть plotly в ее интерактивности. В данном случае на графике при наведении виден суммарный рейтинг статей на определенную дату(месяц). Видно, что рейтинг просел в 2020. Но это можно объяснить тем, что количество статей из данного промежутка недостаточно собрано парсерами, а также то, что посты пока не обросли достаточным количеством плюсов.
Внизу графика красной линией так же интерактивно показано количество уникальных статей на определенную дату.
Сохраним график в виде html-файла.
Посмотрим сколько авторов в датасете:

Сколько всего статей на автора:
Кто пишет чаще всего (более 500 статей):
Так вот кто «засоряет» ресурс ). Их не так и много:
Посмотрим, сколько комьюнити на ресурсе всего:
И какое из них самое плодовитое:

*Данные о комьюнити не совсем корректное, так как при парсинге собиралось первое упоминаемое комьюнити, а авторы часто указывают по несколько штук.
Напоследок, посмотрим как применить функцию с вынесением результата в отдельный столбец.
Это понадобится для последующего изучения датасета.
Простая функция отнесения рейтинга статьи к группе.
Если рейтинг больше < 5000 — bad, > 5000 — good.
Применим функцию ratingGroup к DataFrame и выведем результат в отдельный столбец -ratingGroup
В датасете появится новый столбец со значениями:

Скачать — датасет.
Скачать неочищенный датасет, чтобы самому почистить от дубликатов — датасет.
*python чистит (удаляет дубликаты строк исходя из id статьи) почти час! Если кто-нибудь перепишет код на с++ буду благодарен!:
Вопрос снят, т.к. неожиданно ) обнаружен словарь в python, который работает в 10-ки раз быстрее:
Jupyter notebook — скачать.

Работу с датасетом можно вести как в обыкновенном excel, так и jupyter notebook, поля данных разделены табуляцией. Мы остановимся на последнем варианте, и все команды будут приводиться с учетом того, что работа ведется в jupyter notebook.
Будем работать в windows. Поэтому зайдем, используя cmd в папку со скачанным датасетом и запустим jupyter notebook одноименной командой.
Далее импортируем модули.
import pandas as pd
import numpy as np
Так как датасет не содержит заголовков, обозначим их перед загрузкой датасета:
headers=['story_title','link','story_id','data_rating','data_timestamp','story_comments','data_author_id','data_meta_rating','user_name','user_link','story__community_link']
Здесь все наглядно: название статьи, ссылка на нее, id статьи, рейтинг (количество плюсов), дата статьи, количество комментариев, id автора, мета рейтинг статьи, имя автора, ссылка на автора, ссылка на комьюнити.
Считаем датасет.
df = pd.read_csv('400k-pikabu.csv',parse_dates=['data_timestamp'],
warn_bad_lines=True,
index_col = False,
dtype ={'story_title':'object','link':'object','story_id':'float32','data_rating':'float32',
'story_comments':'float32','data_author_id':'float32'},
delimiter='\t',names=headers)
Здесь проведена небольшая оптимизация значений при считывании, чтобы некоторые столбцы были представлены как числовые.
Итак, датасет представляет 468595 строк,11 столбцов.
print(df.shape)#468595 строк,11 столбцов
Первые 5 записей
df.head(5)

Статистическое описание:
df.describe()
Работа с пустыми значениями в датасете
Несмотря на то, что парсеры работали не покладая рук, в датасете есть небольшие дыры, иными словами технологические отверстия, представленные пропусками. Данные пропуски в pandas попадают со значением NaN. Посмотрим количество строк с такими пустотами:
len(df.loc[pd.isnull( df['story_title'])])
Как это выглядит на датасете:
df.loc[pd.isnull( df['story_title'])]

1444 строки с пропусками общей картины не портят, но, все таки, избавимся от них:
data1=df.dropna(axis=0, thresh=5)
Проверяем, что удаление прошло успешно:
len(data1.loc[pd.isnull(data1['story_id'])])
Поработаем с датасетом
Посмотрим названия колонок
df.columns
Выберем первую колонку
col = df['story_title']
col
Взглянем на минимум в датасете
data1.min()
Максимум
data1.max()
То же самое более наглядно:
data1.loc[:,['user_name', 'data_rating', 'story_comments']].min()
Теперь соберем значения из интересных столбцов в массив:
arr = data1[['story_id', 'data_rating', 'data_timestamp','user_name']].valuesМожно посмотреть на один из столбцов массива:
arr[:, 1] #столбец рейтинг

Посмотрим на количество статей с рейтингом более 10000:
print((arr[:, 1] > 10000.0).sum())Только 2672 статей имеют сверхвысокий рейтинг из 450к
Порисуем графики
Сначала импортируем модуль:
import matplotlib.pyplot as pltВыясним если связь между id автора статьи и рейтингом статьи?
plt.scatter(data1['data_author_id'], data1['data_rating'])
plt.xlabel('data_author_id')
plt.ylabel('data_rating')
Из-за большого количества данных сложно уловить взаимосвязь и, скорее всего, она отсутствует.
Если связь между id статьи и рейтингом статьи?
plt.scatter(data1['story_id'], data1['data_rating'])
plt.xlabel('story_id')
plt.ylabel('data_rating')
Здесь заметно, что посты с более высоким номером (более поздние посты) получают больший рейтинг, за них чаще отдают голоса. Растет популярность ресурса?
Если связь между датой статьи и рейтингом?
plt.scatter(data1['data_timestamp'], data1['data_rating'])
plt.xlabel('data_timestamp')
plt.ylabel('data_rating')
Также видна взаимосвязь между более поздними публикациями и рейтингом постов. Более качественный контент или опять же просто рост посещаемости ресурса?
Если связь между рейтингом статьи и количеством комментов к ней?
plt.scatter(data1['story_comments'], data1['data_rating'])
plt.xlabel('story_comments')
plt.ylabel('data_rating')
Здесь прослеживается линейная зависимость, хотя она сильно распылена. Логика определенная есть, чем выше рейтинг поста, тем больше комментов.
Посмотрим на топ авторов (авторов, суммарный рейтингов постов которых максимален):
top_users_df = data1.groupby('user_name')[['data_rating']].sum().sort_values('data_rating', ascending=False).head(10)
top_users_df

Добавим наглядности:
top_users_df.style.bar()
Попробуем другие инструменты визуализации. Например, seaborn
# для установки библиотек
! pip3 install seaborn
from __future__ import (absolute_import, division,
print_function, unicode_literals)
# отключим предупреждения
import warnings
warnings.simplefilter('ignore')
# будем отображать графики прямо в jupyter'e
%pylab inline
#графики в svg выглядят более четкими
%config InlineBackend.figure_format = 'svg'
#увеличим размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 6,3
import seaborn as snsПостроим графики, используя столбцы с id постов, их рейтингом и комментариями, сохраним результат в .png:
%config InlineBackend.figure_format = 'png'
sns_plot = sns.pairplot(data1[['story_id', 'data_rating', 'story_comments']]);
sns_plot.savefig('pairplot.png')

Попробуем инструмент визуализации Plotly
from plotly.offline import init_notebook_mode, iplot
import plotly
import plotly.graph_objs as go
init_notebook_mode(connected=True)
Сгруппируем данные по дате и суммарному рейтингу статей на эту дату:
df2 = data1.groupby('data_timestamp')[['data_rating']].sum()
df2.head()
Посмотрим, сколько статей всего выходило на определенную дату (месяц):
released_stories = data1.groupby('data_timestamp')[['story_id']].count()
released_stories.head()
Склеим две таблицы:
years_df = df2.join(released_stories)
years_df.head()
Теперь нарисуем, используя plotly:
trace0 = go.Scatter(
x=years_df.index,
y=years_df.data_rating,
name='data_rating'
)
trace1 = go.Scatter(
x=years_df.index,
y=years_df.story_id,
name='story_id'
)
data = [trace0, trace1]
layout = {'title': 'Statistics'}
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)

Прелесть plotly в ее интерактивности. В данном случае на графике при наведении виден суммарный рейтинг статей на определенную дату(месяц). Видно, что рейтинг просел в 2020. Но это можно объяснить тем, что количество статей из данного промежутка недостаточно собрано парсерами, а также то, что посты пока не обросли достаточным количеством плюсов.
Внизу графика красной линией так же интерактивно показано количество уникальных статей на определенную дату.
Сохраним график в виде html-файла.
plotly.offline.plot(fig, filename='stats_pikabu.html', show_link=False);Группировки данных
Посмотрим сколько авторов в датасете:
data1.groupby('user_name').size()
Сколько всего статей на автора:
data1['user_name'].value_counts()
Кто пишет чаще всего (более 500 статей):
for i in data1.groupby('user_name').size():
if i>500:
print (data1.iloc[i,8],i) #8-номер столбца с user_nameТак вот кто «засоряет» ресурс ). Их не так и много:
авторы
crackcraft 531
mpazzz 568
kastamurzik 589
pbdsu 773
RedCatBlackFox 4882
Wishhnya 1412
haalward 1190
iProcione 690
tooNormal 651
Drugayakuhnya 566
Ozzyab 1088
kalinkaElena9 711
Freshik04 665
100pudofff 905
100pudofff 1251
Elvina.Brestel 1533
1570525 543
Samorodok 597
Mr.Kolyma 592
kka2012 505
DENTAARIUM 963
4nat1k 600
chaserLI 650
kostas26 1192
portal13 895
exJustice 1477
alc19 525
kuchka70 572
SovietPosters 781
Grand.Bro 1051
Rogo3in 1068
fylhtq2222 774
deystvitelno 539
lilo26 802
al56.81 2498
Hebrew01 596
TheRovsh 803
ToBapuLLI 1143
ragnarok777 893
Ichizon 890
hoks1 610
arthik 700
mpazzz 568
kastamurzik 589
pbdsu 773
RedCatBlackFox 4882
Wishhnya 1412
haalward 1190
iProcione 690
tooNormal 651
Drugayakuhnya 566
Ozzyab 1088
kalinkaElena9 711
Freshik04 665
100pudofff 905
100pudofff 1251
Elvina.Brestel 1533
1570525 543
Samorodok 597
Mr.Kolyma 592
kka2012 505
DENTAARIUM 963
4nat1k 600
chaserLI 650
kostas26 1192
portal13 895
exJustice 1477
alc19 525
kuchka70 572
SovietPosters 781
Grand.Bro 1051
Rogo3in 1068
fylhtq2222 774
deystvitelno 539
lilo26 802
al56.81 2498
Hebrew01 596
TheRovsh 803
ToBapuLLI 1143
ragnarok777 893
Ichizon 890
hoks1 610
arthik 700
Посмотрим, сколько комьюнити на ресурсе всего:
data1.groupby('story__community_link').size() 
И какое из них самое плодовитое:
data1['story__community_link'].value_counts()
*Данные о комьюнити не совсем корректное, так как при парсинге собиралось первое упоминаемое комьюнити, а авторы часто указывают по несколько штук.
Напоследок, посмотрим как применить функцию с вынесением результата в отдельный столбец.
Это понадобится для последующего изучения датасета.
Простая функция отнесения рейтинга статьи к группе.
Если рейтинг больше < 5000 — bad, > 5000 — good.
def ratingGroup( row ):
# проверяем, что значение рейтинга не равно NaN
if not pd.isnull( row['data_rating'] ):
if row['data_rating'] <= 5000:
return 'bad'
if row['data_rating'] >= 20000:
return 'good'
# если значение возраста NaN, то возвращаем Undef
return 'Undef'Применим функцию ratingGroup к DataFrame и выведем результат в отдельный столбец -ratingGroup
data1['ratingGroup'] = data1.apply( ratingGroup, axis = 1 )
data1.head(10)В датасете появится новый столбец со значениями:

Скачать — датасет.
Скачать неочищенный датасет, чтобы самому почистить от дубликатов — датасет.
*python чистит (удаляет дубликаты строк исходя из id статьи) почти час! Если кто-нибудь перепишет код на с++ буду благодарен!:
with open('f-final-clean-.txt','a',encoding='utf8',newline='') as f:
for line in my_lines:
try:
b=line.split("\t")[2]
if b in a:
pass
else:
a.append(b)
f.write(line)
except:
print(line)
Вопрос снят, т.к. неожиданно ) обнаружен словарь в python, который работает в 10-ки раз быстрее:
a={}
f = open("f-final.txt",'r',encoding='utf8',newline='')
f1 = open("f-final-.txt",'a',encoding='utf8',newline='')
for line in f.readlines():
try:
b=line.split("\t")[2]
if b in a:
pass
else:
a[b]=b
#print (a[b])
f1.write(line)
except:
pass
f.close()
f1.close()
Jupyter notebook — скачать.
