
Как выглядят данные?
Во-первых, посмотрим на имеющиеся тестовые и тренировочные данные (данные соревнования «Toxic comment classification challenge» на платформе kaggle.com). В тренировочных данных, в отличии от тестовых, имеются метки для классификации:
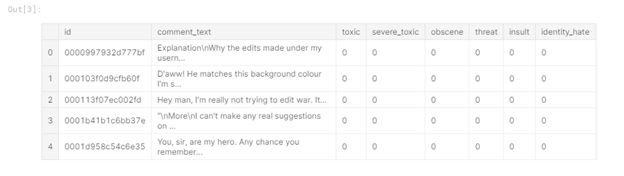
Рисунок 1 — Train data head
Из таблицы видно, что мы имеем в тренировочных данных 6 столбцов-меток («toxic», «severe_toxic», «obscene», «threat», «insult», «identity_hate»), где значение «1» свидетельствует о принадлежности комментария к классу, также присутствует столбец «comment_text», содержащий комментарий и столбец «id» – идентификатор комментария.
Тестовые данные не содержат меток классов, так как используются для отправки решения:

Рисунок 2 — Test data head
Извлечение признаков
Следующий этап – извлечение признаков из комментариев и проведение исследовательского анализа данных (EDA). Во-первых, посмотрим распределение типов комментариев в тренировочном наборе данных. Для этого был создан новый столбец «toxic_type», содержащий все классы, к которым относился комментарий:
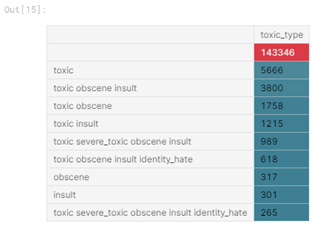
Рисунок 3 — Топ-10 типов токсичных комментариев
Из таблицы видно, преобладающий тип – отсутствие каких-либо меток класса, и многие комментарии принадлежат больше чем к одному классу.
Также посмотрим, как распределено количество типов для каждого комментария:
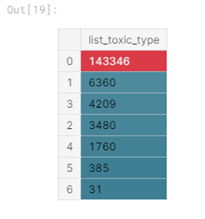
Рисунок 4 — Количество встречающихся типов
Заметим, что преобладает ситуация, когда комментарий характеризуется только одним типом токсичности, также достаточно часто комментарий характеризуется тремя типами токсичности и реже всего комментарий относят ко всем типам.
Теперь перейдём к этапу извлечения признаков из текста, который часто называют features extraction. Я извлекла следующие признаки:
Длина комментария. Я предполагаю, что гневные комментарии скорее всего будут короткими;
Верхний регистр. В агрессивно-эмоциональных комментариях возможно в словах будет чаще встречаться верхний регистр;
Смайлики. При написании токсичного комментария вряд ли будут использоваться позитивно окрашенные смайлики ( :), и т.д.), так же рассмотрим наличие грустных смайликов ( :(, и т.д.);
Пунктуация. Вероятно, авторы негативных комментариев не придерживаются правил пунктуации, в большей степени они используют «!»;
Количество сторонних символов. Некоторые люди при написании оскорбительных слов часто используют символы @, $ и т.д.
Добавление признаков осуществляется следующим образом:
train_data[‘total_length’] = train_data[‘comment_text’].apply(len)
train_data[‘uppercase’] = train_data[‘comment_text’].apply(lambda comment: sum(1 for c in comment if c.isupper()))
train_data[‘exclamation_punction’] = train_data[‘comment_text’].apply(lambda comment: comment.count(‘!’))
train_data[‘num_punctuation’] = train_data[‘comment_text’].apply(lambda comment: comment.count(w) for w in ‘.,;:?’))
train_data[‘num_symbols’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in ‘*&$%’))
train_data[‘num_words’] = train_data[‘comment_text’].apply(lambda comment: len(comment.split()))
train_data[‘num_happy_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-)’, ‘:)’, ‘;)’, ‘;-)’)))
train_data[‘num_sad_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-(’, ‘:(’, ‘;(’, ‘;-(’)))Исследовательский анализ данных
Теперь исследуем данные с использованием только что полученных признаков. В первую очередь, посмотрим корреляцию признаков между собой, корреляцию между признаками и метками классов, корреляцию между метками классов:

Рисунок 5 — Корреляция
Корреляция говорит о наличии линейной зависимости между признаками. Чем ближе значение корреляции по модулю к 1, тем ярче выражена линейная зависимость между элементами.
Например, можно увидеть, что количество слов и длина текста сильно коррелированы между собой (значение 0.99), значит, какой-то признак из них можно убрать, я убрала количество слов. Также мы можем сделать еще несколько выводов: корреляция практически отсутствует между выделенными признаками и метками классов, самый мало коррелируемый признак – количество символов, а длина текста коррелирует с количеством символов пунктуации и количеством символов, приведённых к верхнему регистру.
Далее, построим несколько визуализаций для более детального понимания влияния признаков на метку класса. Для начала посмотрим, как распределены длины комментариев:
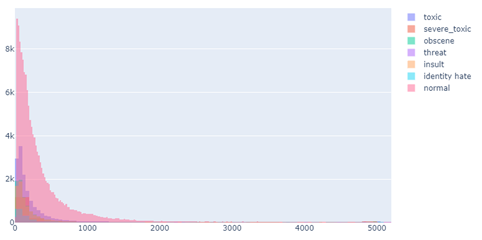
Рисунок 6 — Распределение длин комментариев (график интерактивный, но тут скриншот)
Как и предполагалось, для комментариев, которые были не отнесены к какому-либо классу (т.е. являются нормальными), длина намного больше, чем для помеченных комментариях. Из негативных комментариев самыми короткими являются угрозы (threat), а самыми длинными – токсичные (toxic).
Теперь исследуем комментарии с точки зрения пунктуации. Будем строить графические представления для средних значений, чтобы графики получились более интерпретируемыми:

Рисунок 7 — Средние значения пунктуации (график интерактивный, но тут скриншот)
Из рисунка видно, что мы получили три кластера.
Первый – нормальные комментарии, для них характерно соблюдение пунктуационных правил (расстановка знаков препинания, «:», например) и небольшое количество восклицательных знаков.
Второй состоит из угроз (threat) и очень токсичных комментариев (severe toxic), для такой группы характерно обильное использование восклицательных знаков и на среднем уровне используются иные знаки пунктуации.
Третий кластер – токсичные (toxic), непристойные (obscene), оскорбления (insult) и ненавистные по отношению к некоторой личности (identity hate) имеют небольшое количество как пунктуационных знаков, так и восклицательных.
Добавим третью ось для большей наглядности – верхний регистр:

Рисунок 8 -Трёхмерное изображение (интерактивное, но тут скриншот)
Здесь видим аналогичную ситуацию – выделяется три кластера. Также отметим, что расстояние между элементами второго кластера больше, чем расстояние между элементами третьего кластера. Это можно увидеть и на двумерном графике:
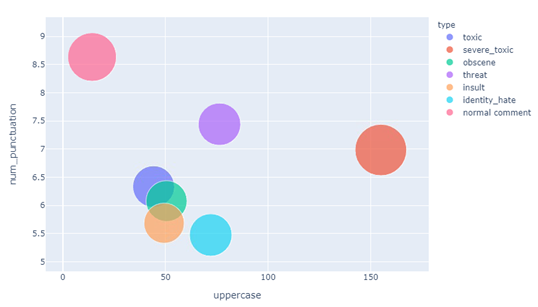
Рисунок 9 — Верхний регистр и пунктуация (интерактивное, здесь скриншот)
Теперь рассмотрим на типы комментариев в разрезе верхнего регистра/количества сторонних символов:
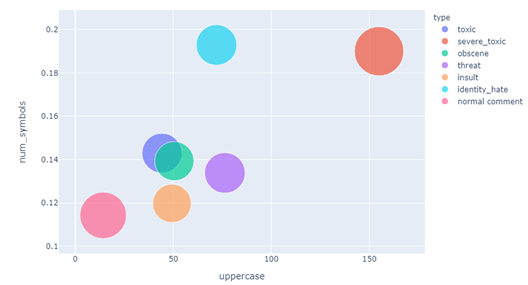
Рисунок 10 — Верхний регистр и количество сторонних символов (интерактивное, здесь скриншот)
Как видно, явно выделяются очень токсичные комментарии – они имеют большое количество символов в верхнем регистре и много сторонних символов. Также сторонние символы активно используют авторы ненавистных по отношению к некоторой личности комментариев.
Таким образом, выделение новых признаков и их визуализация позволяет интерпретировать имеющиеся данные лучше и выше построенные визуализации можно резюмировать следующим образом:
Очень токсичные комментарии отделены от остальных;
Нормальные комментарии также стоят особняком;
Токсичные, непристойные и носящие оскорбительный характер комментарии очень близки друг к другу в разрезе рассмотренных характеристик.
Использование DataFrameMapper для объединения текстовых и числовых признаков
Теперь рассмотрим, как можно использовать вместе текстовые и числовые признаки в Logistic regression.
Во-первых, нужно выбрать модель для репрезентации текста в подходящей для алгоритмов машинного обучения форме. Я использовала tf-idf модель, так как она способна выделить специфичные слова и сделать менее значимыми частые слова (например, предлоги):
tvec = TfidfVectorizer(
sublinear_tf=True,
strip_accents=’unicode’,
analyzer=’word’,
token_pattern=r’\w{1,}’,
stop_words=’english’,
ngram_range=(1, 1),
max_features=10000
)Итак, если мы хотим работать с предоставляемыми библиотекой Pandas dataframe и алгоритмами машинного обучения библиотеки Sklearn, можно использовать модуль Sklearn-pandas, служащий неким связующим между данными в формате dataframe и Sklearn-методами.
mapper = DataFrameMapper([
([‘uppercase’], StandardScaler()),
([‘exclamation_punctuation’], StandardScaler()),
([‘num_punctuation’], StandardScaler()),
([‘num_symbols’], StandardScaler()),
([‘num_happy_smilies’], StandardScaler()),
([‘num_sad_smilies’], StandardScaler()),
([‘total_length’], StandardScaler())
], df_out=True)Сначала нужно создать DataFrameMapper как показано выше, он должен содержать названия столбцов, имеющих numeric features. Далее создаём матрицу признаков, которую далее будем передавать в Logistic regression для обучения:
x_train = np.round(mapper.fit_transform(numeric_features_train.copy()), 2).values
x_train_features = sparse.hstack((csr_matrix(x_train), train_texts))Аналогичная последовательность действий производится также над набором данных для тестирования.
Вычислительный эксперимент
Для проведения multi-label classification построим цикл, который будет проходиться по всем категориям и оценивать качество классификации кросс-валидацией с параметрами cv=3 и scoring=’roc_auc’:
scores = []
class_names = [‘toxic’, ‘severe_toxic’, ‘obscene’, ‘threat’, ‘identity_hate’]
for class_name in class_names:
train_target = train_data[class_name]
classifier = LogisticRegression(C=0.1, solver= ‘sag’)
cv_score = np.mean(cross_val_score(classifier, x_train_features, train_target, cv=3, scoring= ‘auc_roc’))
scores.append(cv_score)
print(‘CV score for class {} is {}’.format(class_name, cv_score))
classifier.fit(train_features, train_target)
print(‘Total CV score is {}’.format(np.mean(scores)))</source
<b>Результат работы:</b>
<img src="https://habrastorage.org/webt/kt/a4/v6/kta4v6sqnr-tar_auhd6bxzo4dw.png" />
<i>Рисунок 11 — Результат работы</i>
Лучше всего классификатор справился с непристойными комментариями, также неплохие результаты были получены для токсичных, оскорбительных комментариев, которые, как мы видели при проведении исследовательского анализа, часто встречались вместе. Скорее всего, это можно обосновать тем, что в непристойных комментариях есть специфичные слова, которые хорошо их отделяют от остальных. Хорошее значение на кросс-валидации комментариев, отнесенных к “toxic”, возможно, обусловлено тем, что эта категория является самой популярной (согласно рисунку 3). Также классификатор хорошо справился с определением очень токсичных комментариев, вероятно, потому что этот тип явно выражен по отношению к остальным, о чём говорилось при проведении исследовательского анализа данных.