Привет, Habr! Я уже рассказывал про AIOps и методы машинного обучения в работе с ИТ инцидентами, про зонтичный мониторинг и различные подходы к сервис менеджменту. Сейчас хотелось бы поделиться вполне конкретным алгоритмом, как можно без особых затрат быстро получить информацию о работоспособности бизнес-приложений с помощью синтетического мониторинга и построить на базе этого метрики здоровья бизнес-сервисов. Рассказ будет построен на кейсе внедрения подхода в одной авиакомпании.
Сейчас есть много APM систем, таких как Appdynamics, Dynatrace, и других, где есть внутри модуль контроля UX через синтетические проверки. И если стоит задача быстрее пользователей узнать о сбое, я расскажу почему все эти APM не нужны. Также модной фишкой APM являются метрики здоровья, я покажу как можно их построить без APM.

Зачем еще одно решение, когда уже есть несколько ИТ-мониторингов?
Хорошо настроенный ИТ-мониторинг позволяет снять множество задач поддержки ИТ, но они ограничены в решении сразу нескольких проблем:
1. Первым делом самолеты
Технический мониторинг не позволяет оценить состояние бизнес-функций систем и инфраструктуры на площадках. Например, когда пропадает канал связи на площадке – это событие для сетевого инженера, но не для бизнеса. У нас есть более сложные кейсы, когда есть несколько помещений с терминалами, где лётный состав должен пройти check-in. В каждом помещении до пяти терминалов, во время «разлёта» мы понимали, что поломка одного-двух терминалов в комнате не влияет на процедуру, однако три-четыре – создадут очередь среди лётного состава, что может повлиять на выполнение одной из важных метрик – «выполнение плана полётов», и часть лётного состава нужно отправить в другую комнату. При потере пяти терминалов – мы теряем в этом помещении ряд бизнес-функций и запускается BCP (Business Сontinuity Planning) – план действий, когда бизнес работает без ИТ. Настроить подобные кейсы простым техническим мониторингом сложно, а продуктовым командам нужен простой инструмент, которые не требует больших компетенций в ИТ-мониторинге.
2. Проводить проверку производительности приложений, но не «закопаться» в обработке результатов
Комплексные системы практически невозможно на 100% покрыть мониторингами метрик или логов. Всегда найдётся что-то, не покрытое мониторингами, из-за чего бизнес-функция системы может оказаться недоступной или деградированной. И тут приходит на помощь способ проверки через эмуляцию работы бизнес-функций методом синтетических транзакций, то есть имитация того, как человек в браузере или на "толстом" клиенте нажимает на кнопки и получает некий результат. Она гарантированно скажет о доступности бизнес-функции для остальных пользователей. Но систем и тестов много, просматривать результаты каждого — трудозатратно и долго. Нужен еще инструмент «оркестрации» синтетических тестов, визуализации результатов.
3. Перестать звонить и спрашивать «единственного, кто знает»
В организациях с крупным IT все системы переплетены друг с другом интеграциями настолько, что порой сложно понять, где кончается одна система и начинается другая. В результате в случае сбоя одной системы совершенно не очевидно, как он может повлиять на другие системы. Информация о взаимосвязи систем обычно только в одном «хранилище» — в головах техлидов продуктовых команд. Нужно было сделать эти данные открытыми и доступными, чтобы в случае сбоя не нужно было опрашивать сотрудников, которые обладают какой-либо информацией. Решить эту задачу могла бы ресурсно-сервисная модель, которая отражала бы влияние различных элементов инфраструктуры на стабильность работы бизнеса.
4. Хьюстон, у нас проблемы?.. или нет?
Конкретно в этой авиакомпании использовалось несколько мониторингов:
А) мониторинг «коробок» и каналов связи – Zabbix, Prometheus для систем в kubernetes
Б) мониторинг логов на платформе семейства ELK (elastic – logstash – kibana).
Любой из них мог сообщить об отклонениях, не было одного места, где можно узнать о состоянии компонентов в целом.
5. Отчёты не отчётов ради
Руководство компании хочет видеть состояние бизнес-функций, а не ИТ-компонентов, причем как в ретроспективе, так и в реальном времени. Отчеты должны быть доступны в одном месте, с понятной «не для технарей» визуализацией, а не в интерфейсах, созданных инженерами для инженеров (вроде дашборда Zabbix или Grafana). Такие отчеты должны быть ежедневными и отражать, что происходило за сутки в зоне ответственности разных исполнителей и какие именно события повлияли на деградацию того или иного сервиса. Раньше такие отчеты были часто субъективными – они были основаны на передаваемых инженерами сводках о значимых событиях. С каждой ответственной, как правило приходилось созваниваться лично и уточнять детали.
6. Куда бежать в первую очередь?
Также была потребность считать SLA с учётом влияния на бизнес. К примеру, в определенный город есть рейс по средам. Недоступность связи с аэропортом в другие дни, а также в день полёта в районе пяти часов до вылета на самом деле никакого влияния на работу не оказывает. Это хотелось бы учитывать при анализе SLA за период. Кроме того, SLA должны помогать инженерам расставить приоритеты в действиях: одно дело, если событие происходит в районе вылета – на это необходимо реагировать 24/7 и срочно, другое дело – если в ближайшее время ИТ функциями никто пользоваться не планирует, и такие события можно брать в работу в порядке очереди. Решить указанные проблемы хотелось инструментом интуитивно понятным, не требующим наличия глубоких технических компетенций в продуктовых командах.
Мы начали внедрять решение, которое закрыло бы все эти задачи, которые не решаются ИТ-мониторингом.
В итоге мы получили следующий набор компонентов мониторинга:
Zabbix и Prometheus для анализа метрик
ELK для анализа логов
Jenkins для управления запуском синтетических проверок, по сути это автотесты, плюс Selenium, как библиотека с помощью которой пишутся на Python эти автотесты
Monq для агрегации всех событий, оркестрации синтетических проверок, зонтичной аналитики и автоматизации процессов
При этом первые два компонента уже были, а вторые два надо было поднять и интегрировать между собой.
Необходимо было решить следующие задачи:
Убедиться, что решение может выступать единым место для агрегации данных по текущим системам мониторинга;
Визуализировать и свести в одну систему результаты выполнения функциональных синтетических тестов, как для web интерфейсов, так и для desktop приложений;
Построить ресурсно-сервисную модель сервисов в рамках всего ИТ;
Настроить автоматизацию по оповещениям и проверить возможности автоматизации на базе скриптов.
Для инсталла платформы и необходимого окружения по функциональному мониторингу нам потребовалось выделить 11 виртуальных машин (4 ушло под monq, 7 для нод Jenkins). Выделение ресурсов было, пожалуй, самым длительным этапом нашего проекта.
Синтетический мониторинг
Синтетический мониторинг - это иммитация действий, которые могли бы совершить пользователи или внешние системы, с последующим мониторинга результатов этих действий. Иногда его также называют функциональным мониторингом или мониторингом синтетических транзакций.
Как я уже писал выше, в этом проекте нам надо было показать клиенту, что мы можем тестировать web-интерфейсы, desktop приложения и проверять доступность бизнес-функций.
По итогу, было написано ряд функциональных автотестов, которые проверяли бизнес-функции. При этом тесты были относительно небольшими и состояли из нескольких шагов, периодичность запуска тестов - 5 минут. Ключевым было: проверить авторизацию в системах, проверить отображение важной информации для конечных пользователей. По каждому шагу в тесте были настроены триггеры по критическому времени выполнения шагов.
В результате мы увидели результаты тестов, на основании которых, можно было уже проводить оценку работы бизнес функций наших приложений, благодаря тому, что в интерфейсе видна ошибка, из-за которой тот или иной шаг провалился и прикреплен скриншот экрана в этот момент.
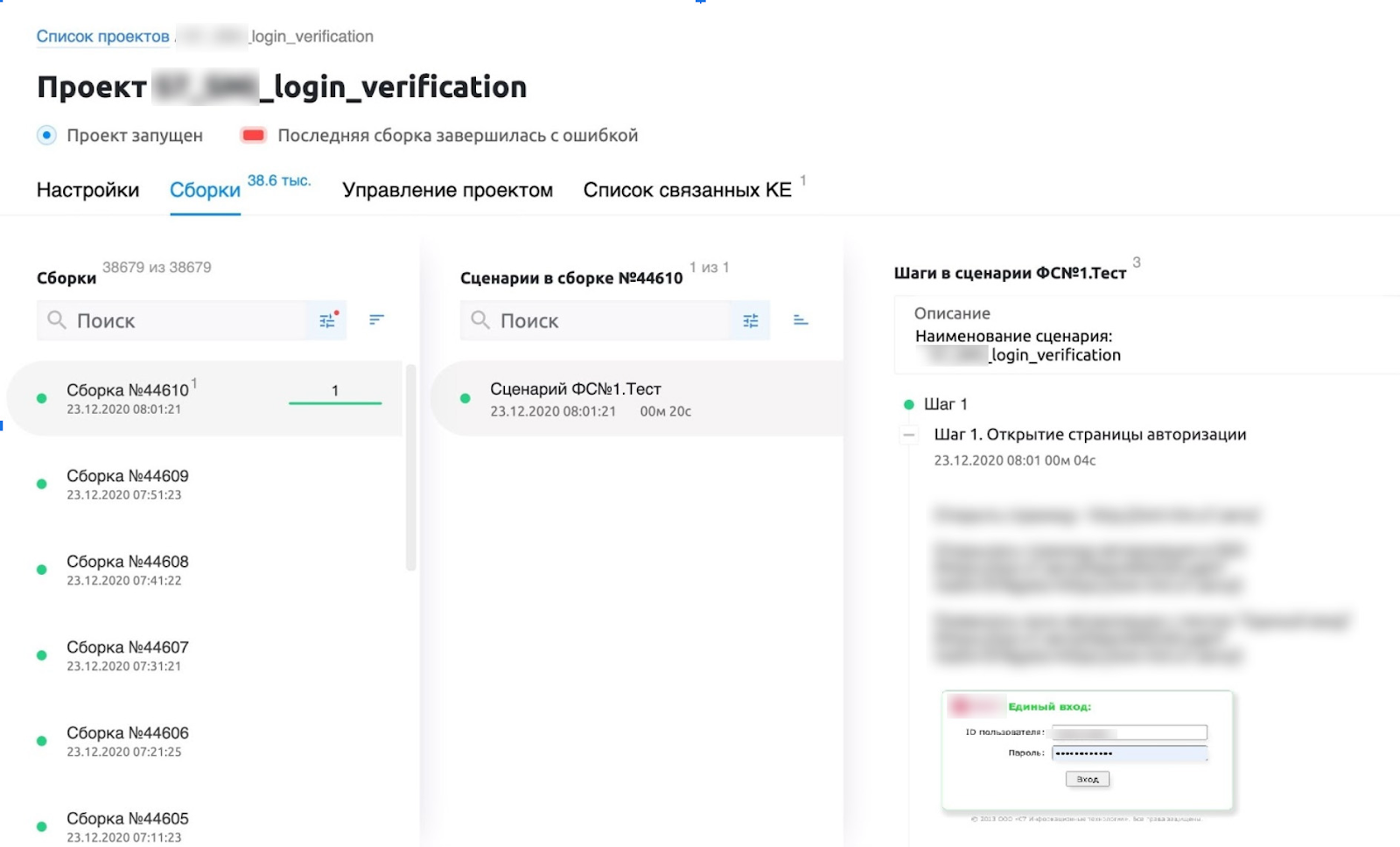
Пример проверки авторизации на интранет-портале
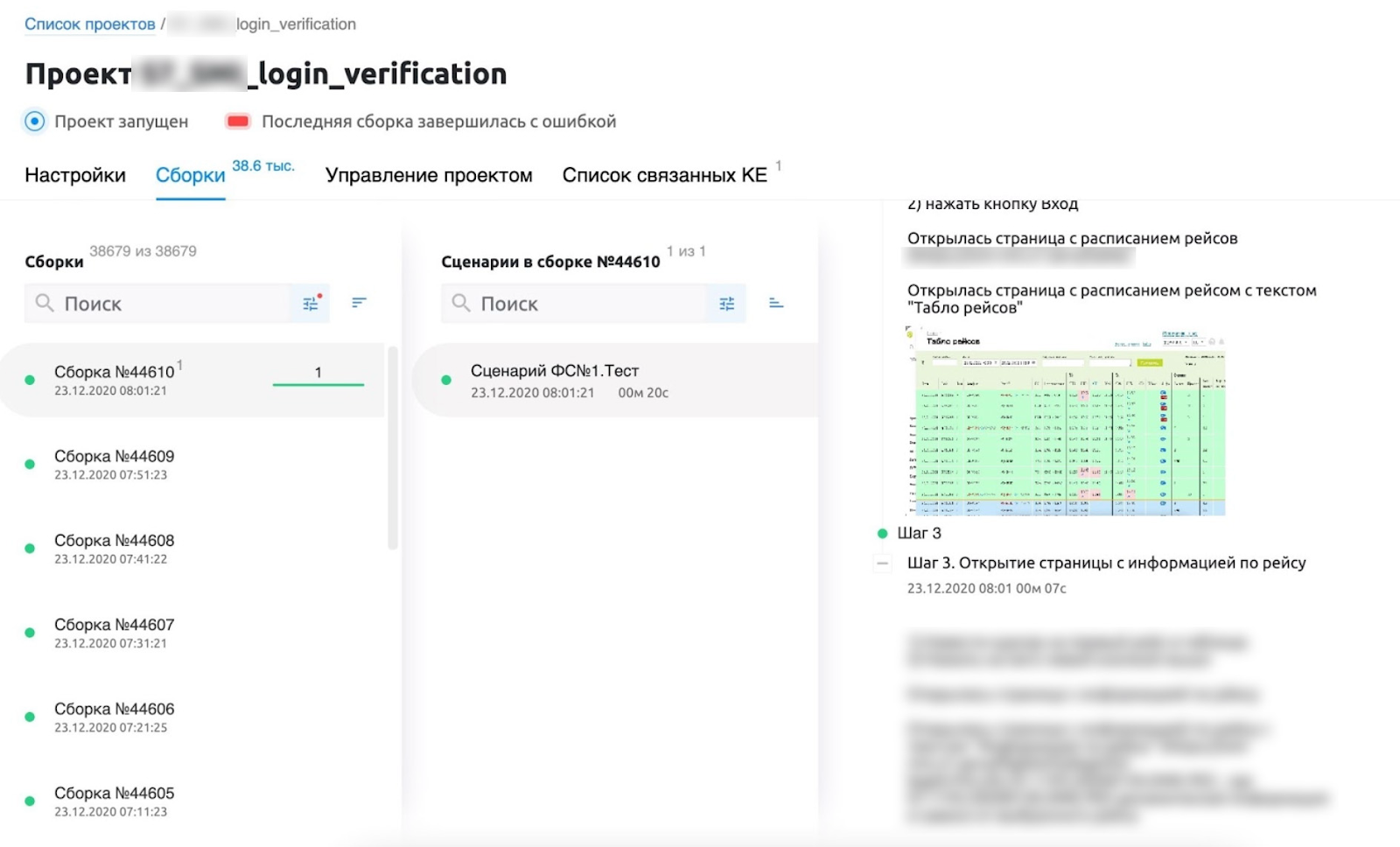
Пример проверки доступности табло рейсов
Опишу подробнее логику одного web-теста по шагам:
1. Открываем страницу авторизации портала. Проверяем, есть ли текст - "Единый вход"
browser.timeout = 25
with allure.step('Шаг 1. Открытие страницы авторизации'):
try:
browser.get("https://***/")
browser.xpath("/html/body/div[2]")
assert browser.xpath("/html/body/div[2]/div[1]/span[contains(text(), 'Единый вход:')]")
allure.attach('screenshot', browser.get_screenshot_as_png(), type=AttachmentType.PNG)
except:
allure.attach('error_screen', browser.get_screenshot_as_png(), type=AttachmentType.PNG)
raise2. Проходим авторизацию. Вводим необходимые данные, нажимаем на кнопку "Вход"
with allure.step('Шаг 2. Авторизация пользователя'):
try:
smi_login = browser.xpath("//*[@id='IDToken1']")
smi_login.click()
smi_login.send_keys("***")
smi_password = browser.xpath("//*[@id='IDToken2']")
smi_password.click()
smi_password.send_keys("***")
browser.xpath("/html/body/div[2]/div[2]/form/input[1]").click()
assert browser.xpath("/html/body/app-root/div/div/s7-header/div/div/div/div/div[1]/h1[contains(text(), 'Табло рейсов')]")
allure.attach('screenshot', browser.get_screenshot_as_png(), type=AttachmentType.PNG)
except:
allure.attach('error_screen', browser.get_screenshot_as_png(), type=AttachmentType.PNG)
raise3. Открываем страницу с информацией по рейсу. Выбираем рейс, кликаем на него, открывается информация по рейсу и проверяем наличие текста "Информация по рейсу"
with allure.step('Шаг 3. Открытие страницы с информацией по рейсу'):
try:
browser.xpath("//*[@id='flightTable']/tbody/tr[1]/td[1]").click()
browser.xpath("/html/body/app-root/div/div/main/flight-info/div/div/leg-info/div/div/div[1]/div[1]/passengers-summary/div/div[1]/div[2]/div[1][contains(text(), 'Лист ожидания')]")
allure.attach('screenshot', browser.get_screenshot_as_png(), type=AttachmentType.PNG)
except:
allure.attach('error_screen', browser.get_screenshot_as_png(), type=AttachmentType.PNG)
raiseЦифровое здоровье сервисов
Метрика цифрового здоровья - это показатель, показывающий насколько элемент ИТ инфраструктуры, сервис или бизнес-функция могут удовлетворять потребности своих клиентов (прочих компонентов ИТ или конечных пользователей). Здоровье сервисов рассчитывается на базе внутренних проверок и влияния связанных по РСМ прочих ИТ компонентов. Например, если у нас из трех нод базы данных (где один master и два slave) упала одна master, то здоровье упадет до нуля, а если slave - то просто будет меньше 100% в соответствии с весовыми коэффициентами влияния в архитектуре решения.
Итак, на этом этапе в платформу уже поступали события, присутствовали результаты синтетических проверок, мы приступили к одной из самых интересных вещей - создание ресурсно-сервисной модели по терминалам, в которых летный состав проходит check-in.
Мы поделили все терминалы на точки присутствия (аэропорты) и их фактическое местоположение внутри здания, чтобы можно было проще ориентироваться визуально и в последствии можно было проще настраивать автоматизацию, в зависимости от локации и важности.
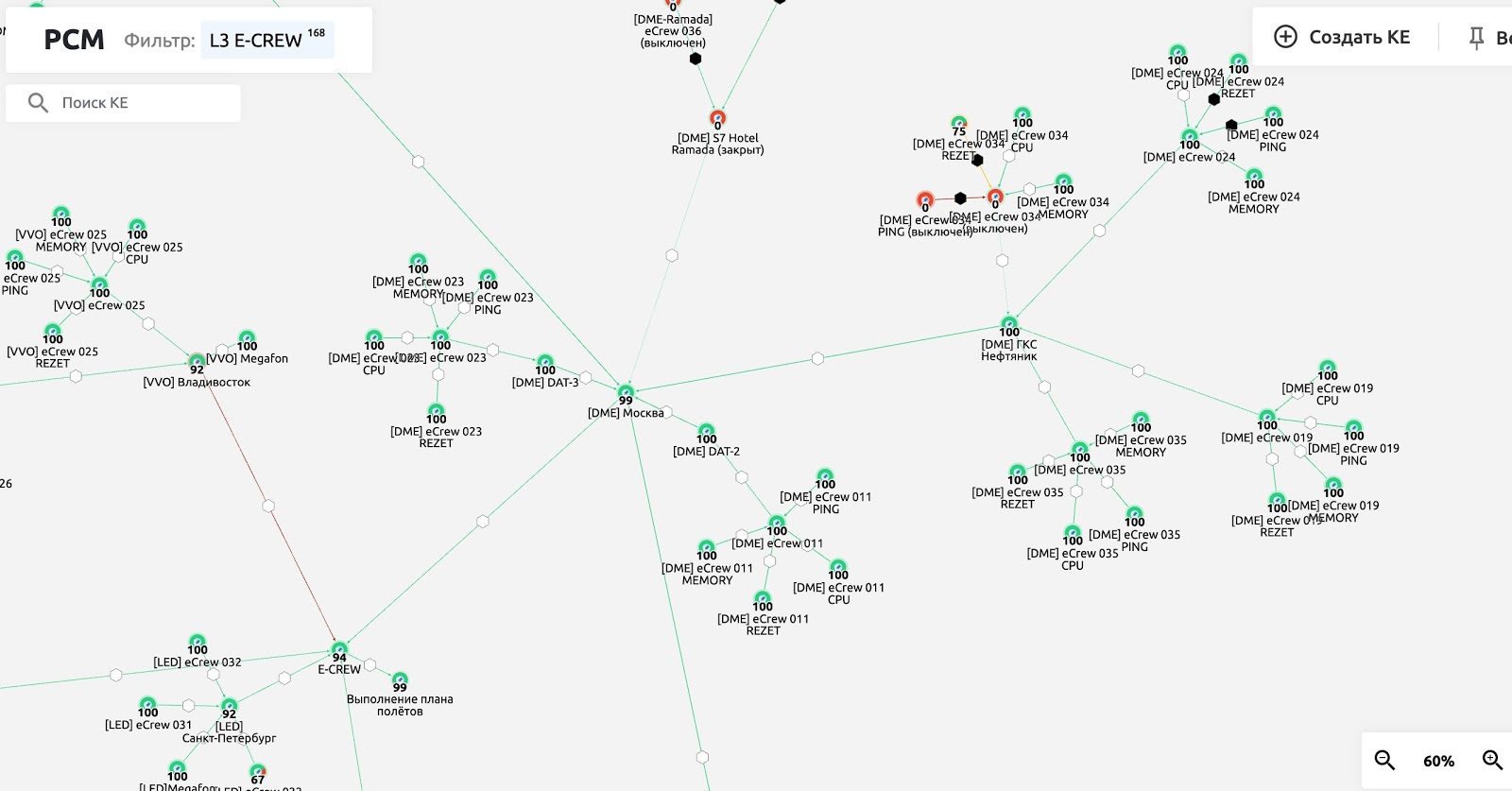
На РСМ видна взаимосвязь элементов и их влияние друг на друга. В случае сбоя в одной КЕ «красным» загорятся связанные с ней
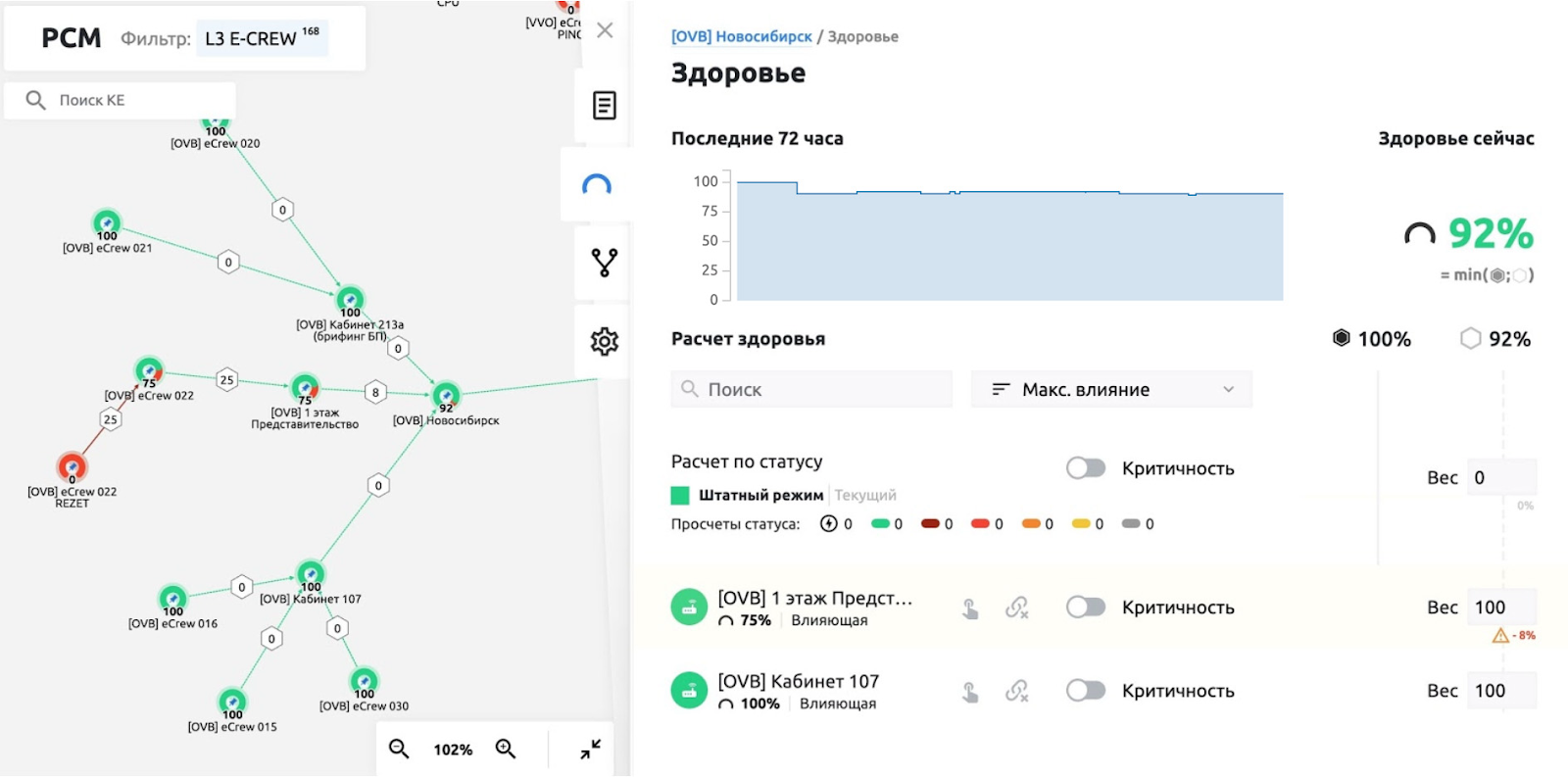
А так можно смотреть на состояние элементов на карте РСМ с их привязкой к состоянию здоровья
Для удобства настроили несколько различных представлений РСМ, для разного уровня сотрудников.
L1 - видно здоровье "бизнеса" в целом.
L2 - здоровье информационных систем. Сюда же мы отнесли результаты функционального мониторинга. В случае, если видим ошибки по тестам, можем провалиться ниже и посмотреть детальнее, что там происходит на уровне инфраструктуры и какие события вносят деградацию или недоступность ИС.
L3 - самая подробная детализация включающая в себя работу всей инфраструктуры.

Так на верхнем уровне видно здоровье основных ИТ сервисов компании
Основываясь на метриках здоровья сервисов настроили автоматизацию, по некоторым событиям были настроены скрипты для управления конечными устройствами. Но это уже про другое, так что в рамках этой статьи описывать это не буду. Самое главное, что за два месяца мы настроили отображение самых важных метрик здоровья ИТ для бизнеса, построенных на синтетических проверках с анализом первопричин, на базе логов и метрик с ИТ-инфраструктуры. Стоимость программных продуктов за эти два месяца составила менее 150 тысяч рублей, а трудозатраты - 2,5 человека на фултайме. Мне кажется неплохой результат. Любой APM был бы на порядок дороже.
