Comments 12
Ого. Весьма нетривиально.
что-то даже расхотелось вообще использовать эти таблицы после прочитанного, лучше уж сразу редис/мемскл какой-нибудь, да даже sqlite в памяти получше будет
Спасибо за пост. Реально полезно. Никогда не доводилось In-Memory с FULL моделью восстановления использовать, а то что на SIMPLE было так сильно не приводило к росту In-Memory файловой группы, но ее легко не фринкнуть и это большая проблема.
И докину еще одну проблему с которой столкнулся давно (сейчас не знаю исправили или нет, но было до 2016 SP2) когда таблица In-Memory обернута в Native Compile хранимку то если нет плана выполенения… план генерируется но сам запрос падает по ошибке. Повторный запрос выполняется корректно потому что план уже в кеше. И когда памяти не хватало было весьма занимательно разбираться почему отваливались транзакции в рамках таких вот конструкций.
И докину еще одну проблему с которой столкнулся давно (сейчас не знаю исправили или нет, но было до 2016 SP2) когда таблица In-Memory обернута в Native Compile хранимку то если нет плана выполенения… план генерируется но сам запрос падает по ошибке. Повторный запрос выполняется корректно потому что план уже в кеше. И когда памяти не хватало было весьма занимательно разбираться почему отваливались транзакции в рамках таких вот конструкций.
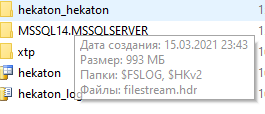
А вы проверяли размер файлов относящихся к этой базе с помощью, прошу прощения, файлового менеджера? Если мне не изменяет память Filestream это просто pipeline для данных, которые могут храниться как на диске так и в памяти (In-Memory OLTP).
А вы проверяли размер файлов относящихся к этой базе с помощью, прошу прощения, файлового менеджера?
На диске занимает столько же, сколько я получаю запросом к sys.database_flies. Воспроизвести эту ситуацию и посмотреть размер на диске с помощью вашего любимого файлового менеджера вы можете минуты за 3 с использованием скриптов в посте.
Причём, если у вас больше 16 ГБ ОЗУ — файлы будут по 128 МБ, если меньше (как у меня сейчас) — по 16 МБ. Ну а в каких-то случаях, начиная с SQL Server 2016, могут использоваться «large checkpoint» по 1 ГБ!
Это, кстати, занятная штука очень.
Столкнулись с ней, когда с небольшого prod-сервера база уезжала по log shipping на сервер со всякой аналитикой.
И вот на prod у нас скромный каталог с этими файлами по 16Мб. А на сервере аналитики (где памяти в избытке было) эти же самые файлы превращаются в
И второй момент с In-Memory и log shipping'ом.
На получателе recovery баз увеличился очень значительно. При этом в логе видно, что сам файл trn поднимается быстро, а recovery базы потом длится по 30-40 минут.
Какого-либо воркэраунда не нашли и пришлось страдать. Есть подозрение, что это связано всё с теми же файлами.
Мы хотим попробовать выкинуть in-memory таблицу в отдельную бд на том же сервере, где вообще нет не-inmemory таблиц. В основной базе таблицу грохнуть и создать под её именем синоним, который будет смотреть на таблицу в новой бд. Если получится, такую базу и в ag можно будет включить, чтобы вместе ездили в случае файловера.
Sign up to leave a comment.
Тёмная сторона SQL Server In-Memory OLTP