In this article, we will briefly review a technology that underlies ChatGPT — embeddings. Also we’ll write a simple intelligent search in a codebase of a project.

Embedding is the process of converting words or text into a set of numbers called a numeric vector. Vectors can be compared with each other to determine how similar two texts or words are in meaning.
For example, we take two numerical vectors (embeddings) of the words "donate" and "give". The words are different but the meaning is similar, i.e. they are interconnected, and the result of both will be giving something to someone.
To get a similar result in the context of a code, we can convert the words into embeddings and compare their similarity measures. The value of measure will range from 0 to 1, where 1 is the maximum similarity and 0 is no correlation. Cosine similarity can be taken as such a comparison function. Imagine that we have done all the necessary operations with embeddings and now analyze the result. We also compared two embeddings of the words "give" and "red". For the words "give" and "donate" the function returned the number 0.80, and for "give" and "red" — only 0.20. Thus, we can conclude that "give" and "donate" are closer than "give" and "red".
In the codebase of a project, embeddings can be used to search in a code or documentation. For example, you can make an embedding (vector) out of the search query and then measure similarity of both to find relevant functions or classes.
So, to make it you need an Open AI account and an API token. If you don't have an account yet, you can register on the official Open AI website. After registering and verifying your account, go to the API Keys profile section and generate an API token.
To start they give $18. That was enough to make an example for this article (below) and conduct further testing of the service.
Take a TypeScript project as a codebase. I recommend taking a small one so as not to wait for generating embeddings long. Also you can use an example. You also need Python 3+ versions and the library from Open AI. No worries if you don't know any of these languages. The code examples below are simple and don't require a deep understanding of both.
Let's get started. First, you need to write a code to extract various pieces of code from the project, such as functions. TypeScript provides a convenient compiler API for working with an AST, which simplifies the task. Install csv-stringify library to generate CSV:
$ npm install csv-stringifyThen create the file code-to-csv.js and write the extraction of information from the code:
const path = require('path');
const ts = require('typescript');
const csv = require('csv-stringify/sync');
const cwd = process.cwd();
const configJSON = require(path.join(cwd, 'tsconfig.json'));
const config = ts.parseJsonConfigFileContent(configJSON, ts.sys, cwd);
const program = ts.createProgram(
config.fileNames,
config.options,
ts.createCompilerHost(config.options)
);
const checker = program.getTypeChecker();
const rows = [];
const addRow = (fileName, name, code, docs = '') => rows.push({
file_name: path.relative(cwd, fileName),
name,
code,
docs
});
function addFunction(fileName, node) {
const symbol = checker.getSymbolAtLocation(node.name);
if (symbol) {
const name = symbol.getName();
const docs = getDocs(symbol);
const code = node.getText();
addRow(fileName, name, code, docs);
}
}
function addClass(fileName, node) {
const symbol = checker.getSymbolAtLocation(node.name);
if (symbol) {
const name = symbol.getName();
const docs = getDocs(symbol);
const code = `class ${name} {}`;
addRow(fileName, name, code, docs);
node.members.forEach(m => addClassMember(fileName, name, m));
}
}
function addClassMember(fileName, className, node) {
const symbol = checker.getSymbolAtLocation(node.name);
if (symbol) {
const name = className + ':' + symbol.getName();
const docs = getDocs(symbol);
const code = node.getText();
addRow(fileName, name, code, docs);
}
}
function addInterface(fileName, node) {
const symbol = checker.getSymbolAtLocation(node.name);
if (symbol) {
const name = symbol.getName();
const docs = getDocs(symbol);
const code = `interface ${name} {}`;
addRow(fileName, name, code, docs);
node.members.forEach(m => addInterfaceMember(fileName, name, m));
}
}
function addInterfaceMember(fileName, interfaceName, node) {
if (!ts.isPropertySignature(node) || !ts.isMethodSignature(node)) {
return;
}
const symbol = checker.getSymbolAtLocation(node.name);
if (symbol) {
const name = interfaceName + ':' + symbol.getName();
const docs = getDocs(symbol);
const code = node.getText();
addRow(fileName, name, code, docs);
}
}
function getDocs(symbol) {
return ts.displayPartsToString(symbol.getDocumentationComment(checker));
}
for (const fileName of config.fileNames) {
const sourceFile = program.getSourceFile(fileName);
const visitNode = node => {
if (ts.isFunctionDeclaration(node)) {
addFunction(fileName, node);
} else if (ts.isClassDeclaration(node)) {
addClass(fileName, node);
} else if (ts.isInterfaceDeclaration(node)) {
addInterface(fileName, node);
}
ts.forEachChild(node, visitNode);
};
ts.forEachChild(sourceFile, visitNode);
}
for (const row of rows) {
row.combined = '';
if (row.docs) {
row.combined += `Code documentation: ${row.docs}; `;
}
row.combined += `Code: ${row.code}; Name: ${row.name};`;
}
const output = csv.stringify(rows, {
header: true
});
console.log(output);The script collects all the fragments we need and prints a CSV table to the console. CSV table consists of the columns file_name, name, code, docs, combined.
file_name contains the path to the file in the project,
name is the name of the fragment, for example, "function’s name",
code is the entity code,
docs is the description from the comments to the fragment,
combined is the addition of the contents of the code and docs columns, we are going to use this column to generate embeddings.
You don't need to run it.
Now to Python.
Install the library from Open AI and utilities for working with embeddings:
$ pip install openai[embeddings]Create the file create_search_db.py with the following code:
from io import StringIO
from subprocess import PIPE, run
from pandas import read_csv
from openai.embeddings_utils import get_embedding as _get_embedding
from tenacity import wait_random_exponential, stop_after_attempt
get_embedding = _get_embedding.retry_with(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(10))
if __name__ == '__main__':
# 1
result = run(['node', 'code-to-csv.js'], stdout=PIPE, stderr=PIPE, universal_newlines=True)
if result.returncode != 0:
raise RuntimeError(result.stderr)
# 2
db = read_csv(StringIO(result.stdout))
# 3
db['embedding'] = db['combined'].apply(lambda x: get_embedding(x, engine='text-embedding-ada-002'))
# 4
db.to_csv("search_db.csv", index=False)The script runs code-to-csv.js(1), the result is loaded into a dataframe(2) and embeddings are generated for the content in the combined(3) column. Embeddings are written to the embedding column. The final table with everything needed for the search is saved to the search_db.csv(4) file.
For the script to work, you need an API token. The openai library can automatically take the token from the environment variables, so you can write a convenient script to make it:
export OPENAI_API_KEY=YourTokenSave it somewhere, for example, in env.sh, and run:
$ source env.shEverything is ready to generate the search database.
Run the script create_search_db.py and wait until the CSV file with the database appears. This may take a couple of minutes. After that, you can start writing a search engine.
Create a new search.py file and write the following:
import sys
import numpy as np
from pandas import read_csv
from openai.embeddings_utils import cosine_similarity, get_embedding as _get_embedding
from tenacity import stop_after_attempt, wait_random_exponential
get_embedding = _get_embedding.retry_with(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(10))
def search(db, query):
# 4
query_embedding = get_embedding(query, engine='text-embedding-ada-002')
# 5
db['similarities'] = db.embedding.apply(lambda x: cosine_similarity(x, query_embedding))
# 6
db.sort_values('similarities', ascending=False, inplace=True)
result = db.head(3)
text = ""
for row in result.itertuples(index=False):
score=round(row.similarities, 3)
if type(row.docs) == str:
text += '/**\n * {docs}\n */\n'.format(docs='\n * '.join(row.docs.split('\n')))
text += '{code}\n\n'.format(code='\n'.join(row.code.split('\n')[:7]))
text += '[score={score}] {file_name}:{name}\n'.format(score=score, file_name=row.file_name, name=row.name)
text += '-' * 70 + '\n\n'
return text
if __name__ == '__main__':
# 1
db = read_csv('search_db.csv')
# 2
db['embedding'] = db.embedding.apply(eval).apply(np.array)
query = sys.argv[1]
print('')
# 3
print(search(db, query))Let's analyze how the script works. The data from search_db.csv is loaded into a dataframe(1), an object-oriented representation of the table. Then embeddings from the table are converted into arrays with numbers(2) so that they can be worked with. At the end, the search function is launched with a search query string(3).
The search function generates an embedding for the query(4), measures similarity of this embedding with each embedding from the base, and stores the similarity score in the similarities column(5).
The degree of similarity is determined by a number from 0 to 1, where 1 means the maximum fit. The rows in the table are sorted by similarities(6).
Finally, the first three rows are retrieved from the database and printed to the console.
The search engine is ready, you can test it.
For the test, run the command with the request:
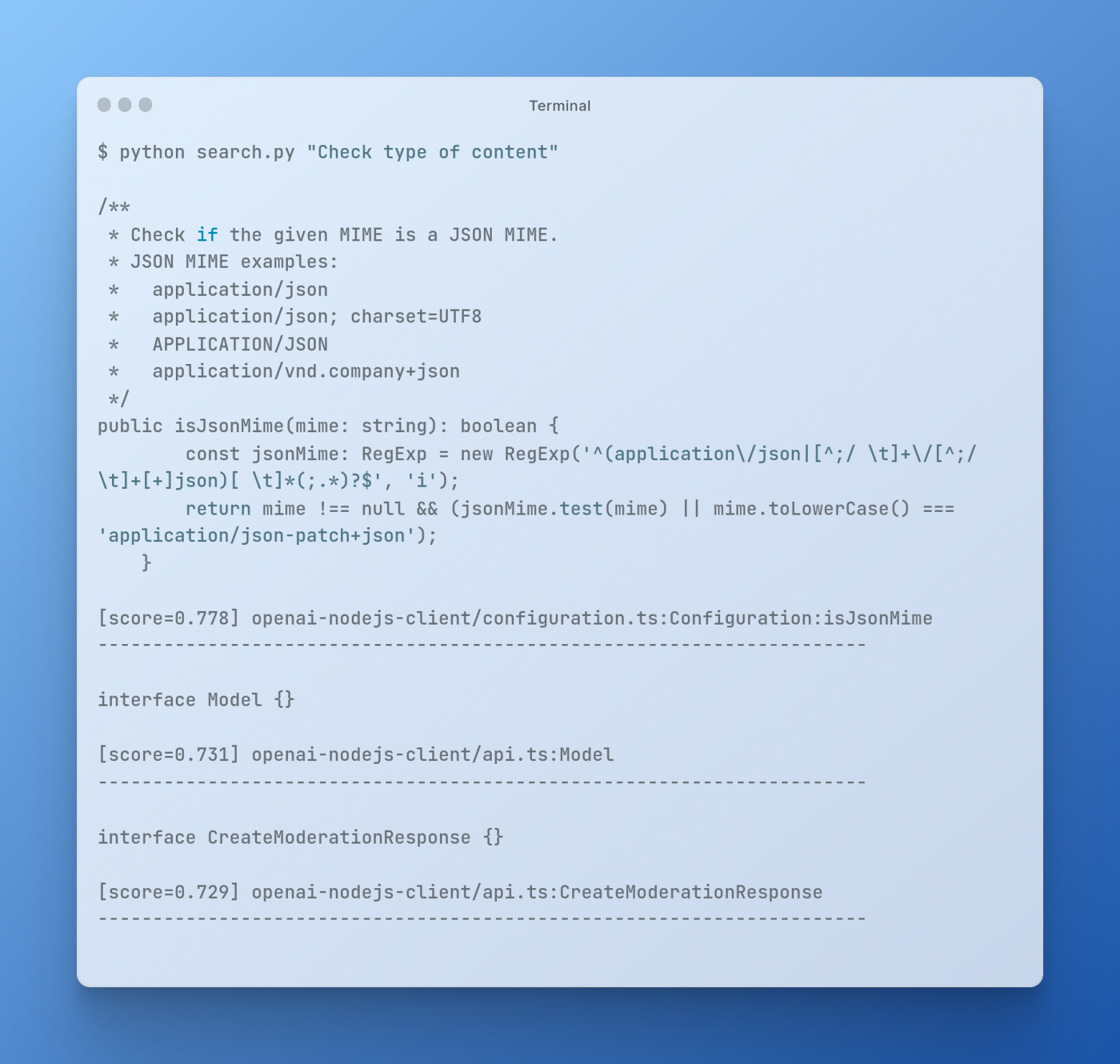
Now try to enter a request in another language:
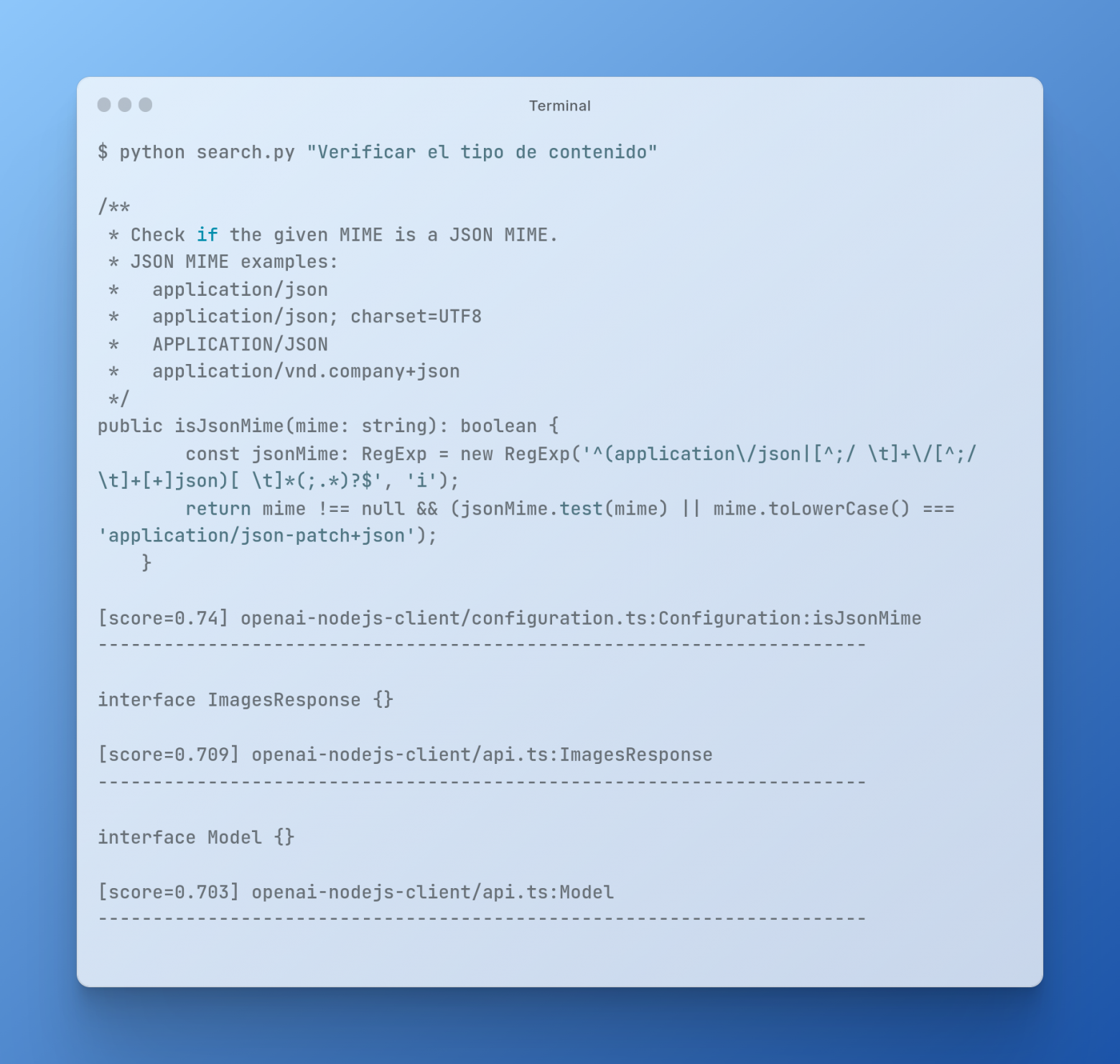
As you can see, the search is based on the meaning of the words in the query, and not just on keywords.
The tool is not limited to just this case and one project. You can organize a more extensive search for all projects at once. This is useful if you develop several similar applications every year and would like to quickly find code snippets, or you have a lot of documentation, and a keyword search is not a good call. It all depends on the tasks and scope.
Thanks for your attention!
Links:
