
Нагрузка и ресурсы, как оно есть.
Год назад я делал нудный доклад о нагрузке, с ним можно ознакомиться здесь: http://vimeo.com/7631344 .
Вкратце обозначу основные положения из него:
- По стратегии предоставления ресурсы могут быть гарантированными и разделяемыми. Между ними нет холивара — они или такие, или такие. Со своими особенностями.
- Ресурсы должны быть поделены по функциональности. Чем более полно выделены отдельные по смыслу функционирования сервисы, тем легче справиться с контролем ресурсов. С «кучей» всегда разобраться сложнее.
- Разделяемые ресурсы должны работать на полной производительности. Нельзя «тормозить» ресурс. Требуется оптимально выбрать «точку входа» и ограничить её и только её.
Проблема.
В нашем случае мы рассматриваем виртуальный UNIX-хостинг с разделяемыми ресурсами. Т.е. множество различных сайтов на одном сервере или группе серверов.
Одной из самых ярких проблем виртуального хостинга является неконтролируемая, не поддающаяся разумной формализации посещаемость, в особенности её резкие скачки. В результате — периодический взрывной рост соединений с веб-сервером, вытекающая из этого нагрузка на базу данных и/или диск, замедление выдачи результатов по сумме причин. Обратная связь — рост соединений с веб-сервером из-за замедляющейся обработки.
Такое в 90% случаев происходит по вине различных роботов, как «белых» (Yandex, Google и проч.), так и «серых» (другие индексирующие сервисы — sape, linkfeed и им подобные) и даже (о боже!) «черных» — роботов, ворующих контент. «Черные роботы» обычно пытаются сдернуть контент «за раз», поэтому приходят на сайт в десятки одновременных потоков, чем создают немалые проблемы.
Ситуация почти всегда усугубляется тем, что очередь желающих попасть к веб-серверу в момент наплыва соединений к какому-нибудь сайту растёт. Даже когда «виновник» затихает, освободившиеся ресурсы резко пытается занять скопившаяся «очередь». Это приводит к так называемой «зыби». В моей практике нередки были проблемные случаи даже при отношении один сервер — три сайта.
Установка «тонкого прокси» (например, nginx) перед веб-сервером устраняет некоторое количество симптомов проблемы. Сама проблема остаётся.
«Вынос» базы данных на отдельную машину снижает порядок негативного эффекта, но не устраняет его, и не во всех случаях экономически оправдан.
Есть вариант кэширования страниц сайтов. Но будем реалистами — большинство разработчиков не знают ничего о среде исполнения своих разработок, знать не хотят и не будут. Примерно на пятом сайте вы уже забудете, что куда кэшируется, что не кэшируется никогда, кто только что поменял структуру сайта или что-нибудь ещё.
Теория.
Очевидно, что в описываемой ситуации «точкой входа» является соединение с веб-сервером, и ограничивать надо именно его. Сразу возникает вопрос — что мы хотим «сказать» пришедшему «лишнему» соединению? Если мы ему хоть что-то «скажем», будь то ошибка 503 или сброс соединения, мы в итоге будем иметь «битые» сайты у неопределённого числа посетителей в хаотичном порядке. Из готовых решений у нас есть только limit_req в nginx с высоким burst. Но возникает проблема — как подобрать параметр скорости запросов? Можно, конечно, доработать limit_conn, на параметр burst из limit_req. Но у обоих решений есть проблема — ограничивается точка входа на «тонкий прокси».
На наш взгляд, точка входа «тонкого прокси» является не самым удачным местом для ограничения. У готовых же решений для apache проблема общая — они что-то, да возвращают. Доработка невозможна даже теоретически — не держать же обработчик апача в ожидании «разрешения», это сводит на нет весь смысл затеи.
Предыстория
Мы предоставляем услугу хостинга приложений на языке python посредством mod_wsgi. Апач запускает для каждого сайта некоторое количество специальных обработчиков, которые постоянно находятся в памяти. Каково же было наше удивление, когда мы осознали, что особо не замечаем эффекта «наплыва» на таких сайтах (например — http://twihoo.ru, который является достаточно большим по посещаемости, но не самым крупным по нагрузке на сервер!).
Присмотрелись внимательнее. Понятно — апач общается с обработчиками по unix-сокету, и все «лишние» соединения просто ждут, когда их обработают. В итоге получается «размазывание» нагрузки по времени без лишних телодвижений. Эта практика сильно уменьшила наш религиозный страх перед постоянно находящимися в памяти процессами пользователей, и мы начали искать решение.
Эврика!
Решение пришло совершенно неожиданно. Я участвовал в настройке сервера нашим партнёрам и хотел поставить им несколько отдельно настроенных веб-серверов apache. Заглянув в сценарий запуска apache из коллекции пакетов FreeBSD, я вдруг обнаружил, что там предусматривается такая возможность «из коробки». Сайты у партнёров раскрученные, посещаемые, тяжёлые. Партнёры требовательны и полностью зависят от качества работы сайтов. Учитывая наш опыт хостинга WSGI, соблазн провести эксперимент «в бою» победил.
«Каждому свой apache» оказалось очень удачной мыслью. Совсем недавно планировщик FreeBSD зависел от количества процессов (по умолчанию до версии 7.1), но мы, как прогрессивная компания, уже использовали новые версии FreeBSD с новым планировщиком. Эксперимент показал, что при наличии ресурсов 3-4 процесса апача выдерживают достаточно большую посещаемость даже «тяжёлых» сайтов. Такое решение имеет целый ряд очевидных преимуществ перед специализированными решениями вроде mod_peruser и mod_itk — отсутствие невнятно работающего кода этих модулей, возможность управлять количеством модулей апача, возможность делать специализированные настройки этих модулей.
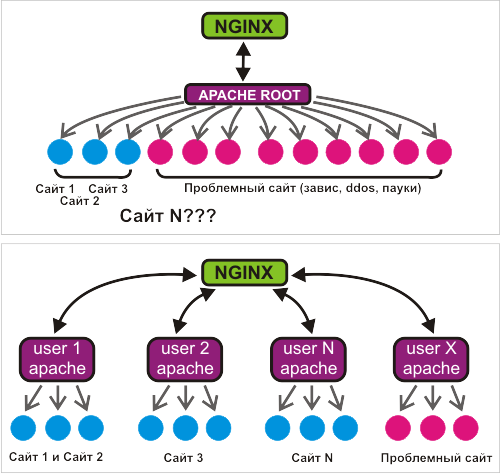
До настоящего времени мы использовали для хостинга apache 1.3.x с немного переделанным самым первым патчем Дмитрия Котерова — на каждый запрос apache делал vfork(), потом setgid() и setuid(), после обслуживания запроса — _exit(). Новый способ даёт нам возможность сэкономить процессорное время, затрачиваемое на эти процедуры.
Но есть и минус — требования к количеству постоянно занимаемой памяти. Современные машины виртуальной памяти, особенно унаследованные из ОС mach, очень сложные. Сосчитать и даже прикинуть заранее, сколько физической памяти будет реально задействовано, не представляется возможным.
К слову сказать, похожую схему выделенных веб-серверов используют как некоторые российские, так и некоторые зарубежные хостинг-провайдеры. Например: MediaTemple с услугой GridContainers (http://mediatemple.net/webhosting/gs/features/containers.php). Правда несколько сложнее и с виртуализацией, но общая идея похожа.
Через тернии к звёздам.
Мы приняли волевое решение рискнуть. Целый месяц мы писали программу сборки конфигураций по данным панели, реагирование на изменения, запуск и останов веб-сервера, автоматическое отслеживание состояния каждого из сотен запущенных веб-сереров, ротация журналов, изменения конфигурации «тонкого прокси» — nginx. Заодно мы причёсывали и оптимизировали все задействованные в перестройке узлы.
Первый провал ожидал нас с… php. Мы пытались собрать php 5.2.x статически с апачем, чтобы сократить время старта веб-сервера и, теоретически, издержки во время исполнения. К сожалению, без хитрой правки внутри системы сборки php этого сделать не удалось. Адекватно поправить уже не позволяло время, и нам пришлось временно отказаться от затеи. Кстати, если есть желающие, в ЖЖ описана эта проблема, можно попробовать её решить годными методами: community.livejournal.com/ru_root/1884339.html.
Но наконец-то система подготовлена. Мы перевели на неё несколько «своих» сайтов. Результат воодушевил — трёх обработчиков апача с лихвой хватило для тяжёлого сайта на drupal посещаемостью в ~1200 уников. В качестве особого теста мы попробовали небольшую «dos-атаку» на данный сайт (10000 запросов по 100 одновременных) — сайт замедлил работу но не оказал почти никакого влияния на работу остальных сайтов. Особых заметных подвижек в распределении памяти мы не диагностировали. Наш же сайт хостинга, который мы тоже перевели на новую систему, вообще не появлялся в выводе top. И вот, за три ночи я радостно перевёл все остальные сервера на новую систему. Почему ночью? Потому что ночью сервера обычно пустуют, и за счёт этого все переделки делаются наиболее быстро и незаметно.
Наступило утро понедельника…
Полный провал.
Сервер с наименьшим количеством сайтов стал работать заметно лучше, но заметно медленнее. На сервере с i386-архитектурой ОС не диагностировалась нехватка памяти, но вдруг mysql занял под себя все обращения к диску и почти парализовал его. Самый же мощный сервер сделал гигабайтный своп и тоже почти парализовал диски.
Подобное состояние «перегруженного» сервера имеет свои плюсы. Стрессовые ситуации вообще способствуют умственной работе. Мы сразу отловили всех, кто создаёт временные таблицы в mysql на сотни мегабайт, мы отловили несколько сайтов, делавших несколько сотен апдейтов баз в секунду. Мы полностью привели в порядок все настройки серверов mysql. Заодно поправили для себя утилиту mytop, до которой ранее руки не доходили: schors.livejournal.com/652161.html. Но ничего не дало ощутимых улучшений. В порыве лёгкой паники мы попробовали сделать большие буфера для записи журналов апача — буфера для частых записей вообще полезны. Практика показала нулевой результат при данных обстоятельствах.
К концу дня мы готовы были дать отмашку на откат всего обратно. Но откат — это сдача позиций, поскольку мы так и не поняли, что происходит. Это значит, новая система и решение проблемы появятся ещё не скоро. Мы ещё немного потянули время. Почти сутки были потрачены на полную диагностику системы и воскурение всех возможных мануалов и руководств.
Результаты в теории оказались банальными — всё-таки не хватает памяти. Не вся память хочет бывать в дисковом свопе, не все программы при нехватке памяти сообщают об этом (например, mysql с временными таблицами и кэшами), используя другие инструменты. Посчитав стоимость дополнительной оперативной памяти, мы не задумываясь решились на обновление оборудования. И угадали.
Двукратное увеличение памяти решило всё. Хочу отметить, что это всё после выглядит странно — изначально было ясно, что может памяти не хватить. Но всё было неясно. Могло не хватить чего угодно — мог не справиться планировщик, мог не справиться процессор, памяти могло не хватить никакой вообще, могло не хватить обработчиков apache, могло не хватить буферов, могло не хватить диска. Вообще, последнее нас и сбило с толку. Вместо того, чтобы провести прямую зависимость между утилизацией памяти и дисковой активностью, мы бросились решать проблему «что же так грузит диск» смотря на то что делают с ним программы.
И тут неожиданно в спину нам ударил… php. Собранный статикой php 5.2.11 вдруг отказался нормально работать с модулем gd (графика). Причём он вообще отказался работать на том срезе библиотек, который у нас был. Магическими методами за бессонную ночь нам удалось привести в рабочее состояние только php с динамически загружаемыми расширениями. Эта проблема находится так: www.google.ru/#hl=ru&newwindow=1&q=gd-png+fatal+libpng+error+freebsd+imagecreatefrompng&lr=&aq=f&oq=&fp=7b635a504e075d30. Понять, на какой зависимости это происходит, так и не удалось. Проблема открыта.
На пути к мировому господству.
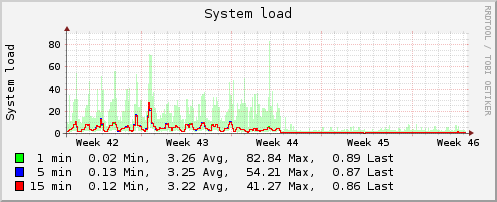
Итог оказался потрясающим. Мы выравняли нагрузку. Представляем показательный график в «попугаях» Load Average. В районе 44-ой недели чётко видно вдруг выравнявшуюся 15-ти минутную нагрузку («холмики» сгладились), которая с апгрейдом оборудования в конце недели предсказуемо упала.
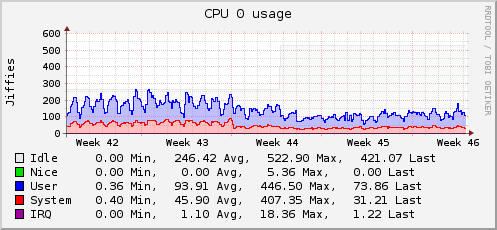
Мы выиграли процессорное время за счёт отказа от постоянных vfork(). На графике видно, что использование cpu заметно упало в начале 44-ой недели, после апгрейда оборудования в конце недели изменения менее заметны.
Остался один вопрос — не перестарались ли мы с ограничением в три обработчика веб-сервера apache на пользователя? В среднем по больнице, каждый пользователь размещает по два сайта. Но у некоторых нередко бывает и десять. Мы внимательно следим за сообщениями нашего мониторинга. На каждый запущенный apache у нас стоит проверка соединения с таймаутом в 60 секунд. Так мы определяем, что сайт точно «лёг». Прошло уже две недели. Срабатывание мониторинга исчисляется единичными случаями. Что характерно — буквально у трёх клиентов из сотен. Обычно это происходит или от нестандартных наплывов желающих что-нибудь «качнуть», или иногда во время бэкапа базы данных, или от допущенных в процессе обновления сайта ошибок.
Новая система принесла нам и приятные неожиданности. Мы получили «честный top». Программа top показывает процессы в системе, по умолчанию сортируя их по некоему странному параметру — процент использования процессора. Он вычисляется на фиксированном промежутке времени ядром по достаточно хитрому оценочному алгоритму и на самом деле не является в чистом виде процентом. В случае, когда один процесс веб-сервера может обрабатывать соединения к сайтам разных пользователей, мы видим «остаточный» процент от прошлого использования процесса. В случае, когда мы делаем vfork(), мы вообще видим только те процессы, что успевают попасть в опрос. В новой системе такого очевидно не происходит. Те процессы, которые появляются на верху top'а, действительно самые требовательные к ресурсам.
Вот так, перешагнув через подсознательный страх нового, переделав чуть менее чем полностью функциональную архитектуру хостинга, мы избавились от «эффекта понедельника».
