
Написано по следам публикации Большие потоки трафика и управление прерываниями в Linux
В нашей городской сети более 30 тысяч абонентов. Суммарный объем внешних каналов — более 3 гигабит. А советы, данные в упомянутой статье, мы проходили еще несколько лет назад. Таким образом, я хочу шире раскрыть тему и поделиться с читателями своими наработками в рамках затрагиваемого вопроса.
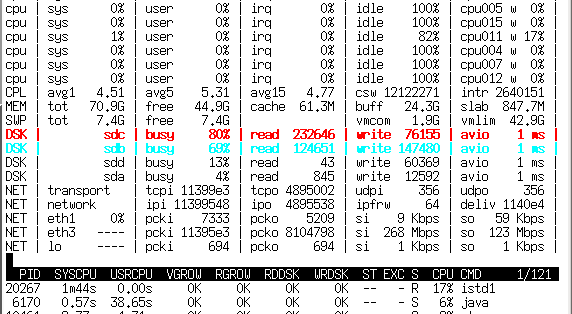
В заметке описываются нюансы настройки/тюнинга маршрутизатора и NAT-сервера под управлением Linux, а также приведены некоторые уточнения по поводу распределения прерываний.
В нашей городской сети более 30 тысяч абонентов. Суммарный объем внешних каналов — более 3 гигабит. А советы, данные в упомянутой статье, мы проходили еще несколько лет назад. Таким образом, я хочу шире раскрыть тему и поделиться с читателями своими наработками в рамках затрагиваемого вопроса.
В заметке описываются нюансы настройки/тюнинга маршрутизатора и NAT-сервера под управлением Linux, а также приведены некоторые уточнения по поводу распределения прерываний.





 Нередко перед системными администраторами встает задача оповещения себя и коллег о каких-либо событиях на сервере, будь то отчет об успешных входах по ssh, резко возросшая нагрузка, падение сервиса, сообщение о переключении на резервное питание или вскипевшем чайнике.
Нередко перед системными администраторами встает задача оповещения себя и коллег о каких-либо событиях на сервере, будь то отчет об успешных входах по ssh, резко возросшая нагрузка, падение сервиса, сообщение о переключении на резервное питание или вскипевшем чайнике.