
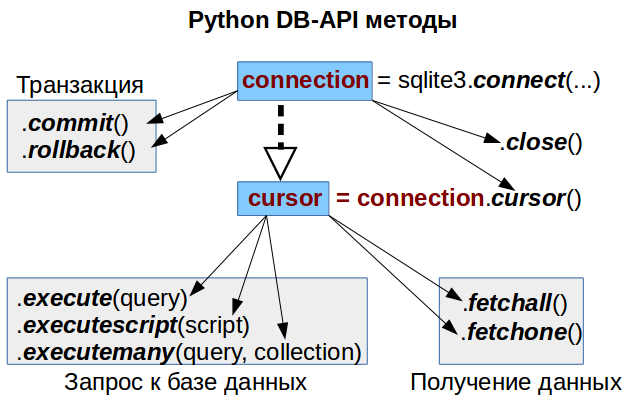
Ловим ошибки в диалогах поддержки с помощью LLM: опыт команды Yandex Crowd

Ежемесячно клиентская поддержка продуктов Яндекса обрабатывает миллионы обращений. Мы регулярно проверяем диалоги вручную. Это помогает бороться, например, с опечатками и другими ошибками операторов. Но проверить все диалоги в таком режиме невозможно — их слишком много. Поэтому мы решили посмотреть в сторону LLM-решений.
Привет! Меня зовут Дарья Шатько, я руководитель ML-группы в Yandex Crowd. В этой статье я расскажу, как мы с моим коллегой Антоном Удаловым внедряли большие языковые модели в контроль качества клиентской поддержки. А именно — почему регулярки и BERT не взлетели, как мы собрали репрезентативный golden‑датасет, как победили лимит контекста, снизили ложные срабатывания через многоступенчатый LLM‑flow и в итоге покрыли проверками абсолютно все диалоги поддержки.









{kind=link}