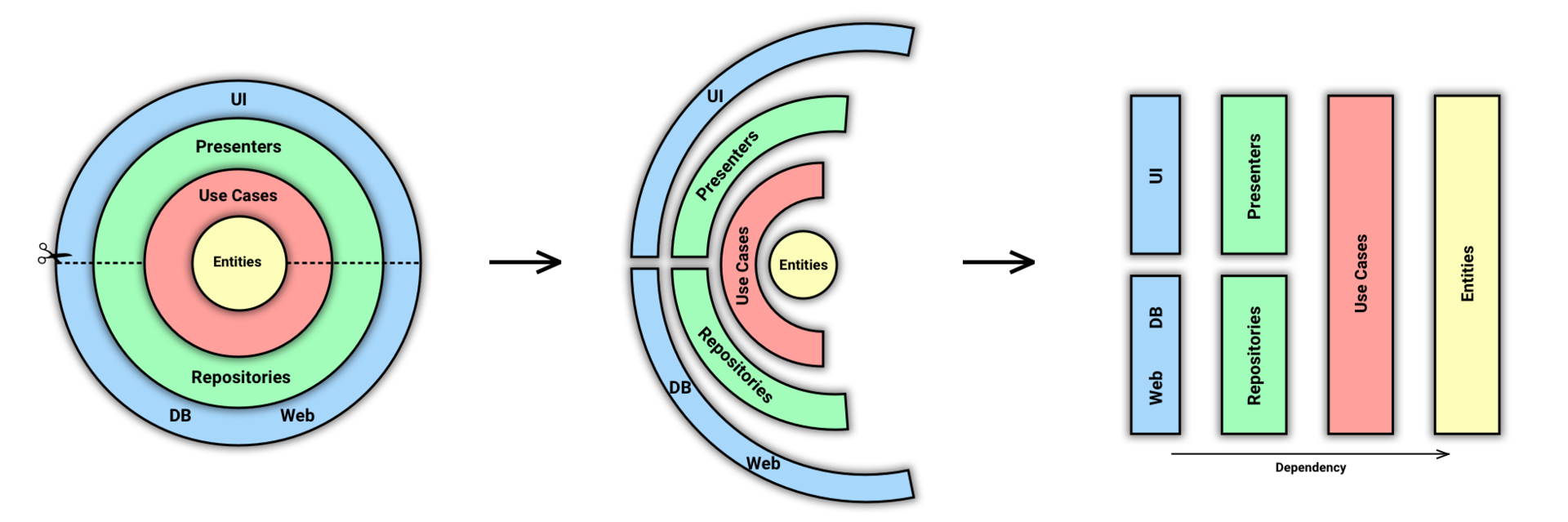
Symfony и Command Bus
16 min
Уже больше года использую паттерн Command Bus в своих Symfony-проектах и наконец решил поделиться опытом. В концев концов обидно, что в Laravel это есть «из коробки», а в Symfony, из которого Laravel во многом вырос — нет, хотя самому понятию Command/Query Separation уже не менее 10 лет. И если с буквой «Q» из аббревиатуры «CQRS» еще понятно что делать (лично меня вполне устраивают custom repositories), то куда приткнуть букву «C» — неясно.
На самом деле, даже в банальных CRUD-приложениях Command Bus дает очевидные преимущества:

На самом деле, даже в банальных CRUD-приложениях Command Bus дает очевидные преимущества:
- контроллеры становятся «худыми» (редкий «экшен» занимает более 15 строк),
- бизнес-логика покидает контроллеры и становится максимально независимой от фреймворка (в результате ее несложно повторно использовать в других проектах, даже если они написаны не на Symfony),
- упрощается unit-тестирование бизнес-логики,
- сокращается дублирование кода (когда, например, необходимо реализовать «фичу» как через Web UI, так и через API).



 Эванс написал
Эванс написал