В первый раз я услышал о CQRS, когда устроился на новую работу. В компании, в которой работаю и по сей день, мне сразу сказали что на проекте, над которым я буду работать используется CQRS, Event Sourcing, и MongoDB в качестве базы данных. Из этого всего я слышал только о MongoDB. Попытавшись вникнуть в CQRS, я не сразу понял все тонкости данного подхода, но почему-то мне понравилась идея разделения модели взаимодействия с данными на две — read и write. Возможно потому что она как-то перекликалась с парадигмой программирования “разделение обязанностей”, возможно потому что была очень в духе DDD.
Вообще многие говорят о CQRS как о паттерне проектирования. На мой взгляд он слишком сильно влияет на общую архитектуру приложения, что бы называться просто “паттерном проектирования”, поэтому я предпочитаю называть его принципом или подходом. Использование CQRS проникает почти во все уголки приложения.
Сразу хочу уточнить что я работал только со связкой CQRS + Event Sourcing, и никогда не пробовал просто CQRS, так как мне кажется что без Event Sourcing он теряет очень много бенефитов. В качестве CQRS фреймворка я буду использовать наш корпоративный Paralect.Domain. Он чем-то лучше других, чем то хуже. В любом случае советую вам ознакомиться и с остальными. Я здесь упомяну только несколько фреймворков для .NET. Наиболее популярные это NCQRS, Lokad CQRS, SimpleCQRS. Так же можете посмотреть на Event Store Джонатана Оливера с поддержкой огромного количества различных баз данных.
Что же такое CQRS?
CQRS расшифровывается как Command Query Responsibility Segregation (разделение ответственности на команды и запросы). Это паттерн проектирования, о котором я впервые услышал от Грега Янга (Greg Young). В его основе лежит простое понятие, что вы можете использовать разные модели для обновления и чтения информации. Однако это простое понятие ведет к серьёзным последствиям в проектировании информационных систем. (с) Мартин Фаулер
Не сказать что исчерпывающее определение, но сейчас я попробую объяснить что именно Фаулер имел в виду.
К настоящему времени сложилась такая ситуация что практические все работают с моделью данных как с CRUD хранилищем. CQRS предлагает альтернативный подход, но затрагивает не только модель данных. Если вы используете CQRS, то это сильно отражается на архитектуре вашего приложения.
Вот как я изобразил схему работы CQRS
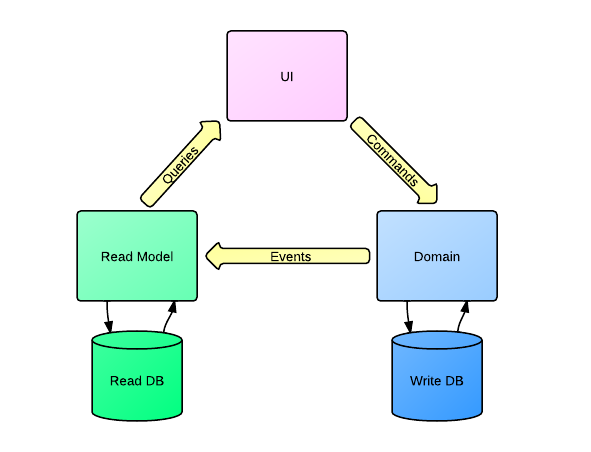
Первое что бросается в глаза это то что у вас уже две модели данных, одна для чтения (Queries), одна для записи (Commands). И обычно это значит что у вас еще и две базы данных. И так как мы используем CQRS + Event Sourcing, то write-база (write-модель) — это Event Store, что-то вроде лога всех действий пользователя (на самом деле не всех, а только тех которые важны с точки зрения бизнес-модели и влияют на построение read-базы). А read-база — это в общем случае денормализировнное хранилище тех данных, которые вам нужны для отображения пользователю. Почему я сказал что read-база денормализированная? Вы конечно можете использовать любую структуру данных в качестве read-модели, но я считаю что при использовании CQRS + Event Sourcing не стоит сильно заморачиваться над нормализвацией read-базы, так как она может быть полностью перестроена в любое время. И это большой плюс, особенно если вы не хотите использовать реляционные базы данных и смотрите в сторону NoSQL.
Write-база вообще представляет собой одну коллекцию ивентов. То есть тут тоже нету смысла использовать реляционную базу.
Идея Event Sourcing в том чтобы записывать каждое событие, которое меняет состояние приложения в базу данных. Таким образом получается что мы храним не состояние наших сущностей, а все события которые к ним относятся. Однако мы привыкли к тому чтобы манипулировать именно состоянием, оно храниться у нас в базе и мы всегда можем его посмотреть.
В случае с Event Sourcing мы тоже оперируем с состоянием сущности. Но в отличии от обычной модели мы это состоянием не храним, а воспроизводим каждый раз при обращении.
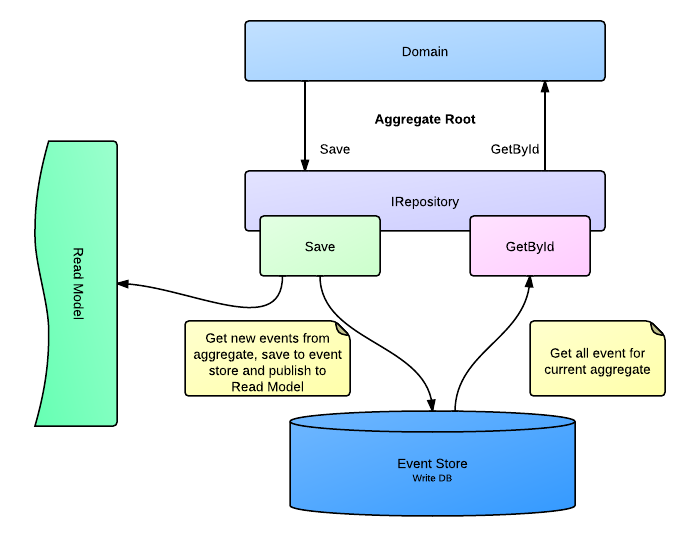
Если посмотреть на код, который поднимает агрегат из базы, можно и не заметить какую-то разницу с традиционным подходом.
На самом же деле репозиторий не берет из базы готовое состояние агрегата UserAR (AR = Aggregate Root), он выбирает из базы все события которые ассоциируются с этим юзером, и потом воспроизводит их по порядку передавая в метод On() агрегата.
Например у класса агрегата UserAR должен быть следующий метод, для того чтобы восстановить в состоянии пользователя его ID
Из всего состояния агрегата мне нужна только _id юзера, так же я мог бы восстановить состояние пароля, имени и т.д. Однако эти поля могут быть модифицированы и другими событиями, не только User_CreatedEvent соответственно мне нужно будет обработать их все. Так как все события воспроизводятся по порядку, я уверен, что всегда работаю с последним актуальным состоянием агрегата, если я конечно написал обработчики On() для всех событий которые это состояние изменяют.
Давайте рассмотрим на примере создания пользователя как работает CQRS + Event Sourcing.
Первое что я сделаю — это сформирую и отправлю команду. Для простоты пусть команда создания юзера имеет только самый необходимый набор полей и выглядит следующим образом.
Пусть вас не смущает имя класса команды, оно не соответствует общепринятым гайдлайнсам, но позволяет сразу понять к какому агрегату она относится, и какое действие выполняется.
Затем мне нужен обработчик этой команды. Обработчику команды обязательно нужно передать ID нужного агрегата, по этому ID он получит агрегат из репозитория. Репозиторий строит объект агрегата следующим образом: берет из базы все события которые относятся к этому агрегату, создает новый пустой объект агрегата, и по порядку воспроизведет полученные события на объекте агрегата.
Но так как у нас команды создания — поднимать из базы нечего, значит создаем агрегат сами и передаем ему метаданные команды.
Посмотрим как выглядит конструктор агрегата.
Так же у агрегата обязательно должен быть конструктор без параметров, так как когда репозиторий воспроизводит состояние агрегата, ему надо сначала создать путой экземпляр, а затем передавать события в методы проекции (метод On(User_CreatedEvent created) является одним из методов проекции).
Немного уточню на счет проекции. Проекция — это воспроизведение состояния агрегата, на основе событий из Event Store, которые относятся к этом агрегату. В примере с пользователем — это все события для данного конкретного пользователя. А агрегате все те же события которые сохраняются через метод Apply, можно обработать во время воспроизведения его состояния. В нашем фреймворке для это достаточно написать метод On(/*EventType arg*/), где EventType — тип события которое вы хотите обработать.
Метод Apply агрегата инициирует отправку событий всем обработчикам. На самом деле события будут отправлены только при сохранение агрегата в репозиторий, а Apply просто добавляет их во внутренний список агрегата.
Вот обработчик события(!) создания пользователя, который записывает в read базу собственно самого пользователя.
У события может быть несколько обработчиков. Такая архитектура помогает сохранять целостность данных, если ваши данные сильно денормализированы. Допустим мне надо часто показывать общее количество пользователей. Но у меня их слишком много и операция count по всем очень затратна для моей БД. Тогда я могу написать еще один обработчик события, который будет уже относится к статистике и каждый раз при добавлении пользователя будет увеличивать общий счетчик пользователей на 1. И я буду уверен, что никто не создаст пользователя, не обновив при этом счетчик. Если бы я не использовал CQRS, а была бы у меня обычная ORM, пришлось бы следить в каждом месте где добавляется и удаляется пользовать чтоб обновился и счетчик.
А использование Event Sourcing’а даёт мне дополнительные приемущеста. Даже если я ошибся в каком-то EventHandler’е или не обработал событие везде где мне это надо, я могу легко это исправать просто перегенировав read базу с уже правильной бизнесс логикой.
С созданием понятно. Как происходит изменение агрегата и валидация команды? Рассмотрим пример со сменой пароля.
Я приведу только command handler и метод агрегата ChangePassword(), так как в остальных местах разница в общем не большая.
Хочу заметить что очень не желательно чтобы невалидное событие было передано в метод Apply(). Конечно вы сможете его обработать потом в event handler’е, но лучше вообще его не сохранять, если оно вам не важно, так как это только засорит Event Store.
В случае со сменой пароля вообще нет никакого смысла сохранять это событие, если вы конечно не собираете статистку по неудачным сменам пароля. И даже в этом случае следует хорошенько подумать, ножно ли это событие вам во write модели или есть смысл записать его в какое-нибудь темповое хранилище. Если вы предполагаете что бизнес логика валидации события может измениться то тогда сохраняйте его.
Вот собственно и все о чем я хотел рассказать в этой статье. Конечно она не раскрывает все аспекты и возможности CQRS + Event Sourcing, об этом я планирую рассказать в следующих статьях. Так же остались за кадром проблемы которые возникают при использовании данного подхода. И об этом мы тоже поговорим.
Если у вас есть какие-то вопросы, задавайте их в комментариях. С радостью на них отвечу. Так же если есть какие-то предложения по следующим статьям — очень хочется их услышать.
Полностью рабочий пример на ASP.NET MVC находится здесь.
Базы данных там нету, все храниться в памяти. При желании её достаточно просто прикрутить. Так же из коробки есть готовая реализация Event Store на MongoDB для хранения ивентов.
Чтобы её прикрутить достаточно в Global.asax файле заменить InMemoryTransitionRepository на MongoTransitionRepository.
В качестве read модели у меня статическая коллекция, так что при каждом перезапуске данные уничтожаются.
У меня есть несколько идей на счет статей по данной тематике. Предлагайте еще. Говорите что наиболее интересно.
Вообще многие говорят о CQRS как о паттерне проектирования. На мой взгляд он слишком сильно влияет на общую архитектуру приложения, что бы называться просто “паттерном проектирования”, поэтому я предпочитаю называть его принципом или подходом. Использование CQRS проникает почти во все уголки приложения.
Сразу хочу уточнить что я работал только со связкой CQRS + Event Sourcing, и никогда не пробовал просто CQRS, так как мне кажется что без Event Sourcing он теряет очень много бенефитов. В качестве CQRS фреймворка я буду использовать наш корпоративный Paralect.Domain. Он чем-то лучше других, чем то хуже. В любом случае советую вам ознакомиться и с остальными. Я здесь упомяну только несколько фреймворков для .NET. Наиболее популярные это NCQRS, Lokad CQRS, SimpleCQRS. Так же можете посмотреть на Event Store Джонатана Оливера с поддержкой огромного количества различных баз данных.
Начнем с CQRS
Что же такое CQRS?
CQRS расшифровывается как Command Query Responsibility Segregation (разделение ответственности на команды и запросы). Это паттерн проектирования, о котором я впервые услышал от Грега Янга (Greg Young). В его основе лежит простое понятие, что вы можете использовать разные модели для обновления и чтения информации. Однако это простое понятие ведет к серьёзным последствиям в проектировании информационных систем. (с) Мартин Фаулер
Не сказать что исчерпывающее определение, но сейчас я попробую объяснить что именно Фаулер имел в виду.
К настоящему времени сложилась такая ситуация что практические все работают с моделью данных как с CRUD хранилищем. CQRS предлагает альтернативный подход, но затрагивает не только модель данных. Если вы используете CQRS, то это сильно отражается на архитектуре вашего приложения.
Вот как я изобразил схему работы CQRS
Первое что бросается в глаза это то что у вас уже две модели данных, одна для чтения (Queries), одна для записи (Commands). И обычно это значит что у вас еще и две базы данных. И так как мы используем CQRS + Event Sourcing, то write-база (write-модель) — это Event Store, что-то вроде лога всех действий пользователя (на самом деле не всех, а только тех которые важны с точки зрения бизнес-модели и влияют на построение read-базы). А read-база — это в общем случае денормализировнное хранилище тех данных, которые вам нужны для отображения пользователю. Почему я сказал что read-база денормализированная? Вы конечно можете использовать любую структуру данных в качестве read-модели, но я считаю что при использовании CQRS + Event Sourcing не стоит сильно заморачиваться над нормализвацией read-базы, так как она может быть полностью перестроена в любое время. И это большой плюс, особенно если вы не хотите использовать реляционные базы данных и смотрите в сторону NoSQL.
Write-база вообще представляет собой одну коллекцию ивентов. То есть тут тоже нету смысла использовать реляционную базу.
Event Sourcing
Идея Event Sourcing в том чтобы записывать каждое событие, которое меняет состояние приложения в базу данных. Таким образом получается что мы храним не состояние наших сущностей, а все события которые к ним относятся. Однако мы привыкли к тому чтобы манипулировать именно состоянием, оно храниться у нас в базе и мы всегда можем его посмотреть.
В случае с Event Sourcing мы тоже оперируем с состоянием сущности. Но в отличии от обычной модели мы это состоянием не храним, а воспроизводим каждый раз при обращении.
Если посмотреть на код, который поднимает агрегат из базы, можно и не заметить какую-то разницу с традиционным подходом.
var user = Repository.Get<UserAR>(userId);
На самом же деле репозиторий не берет из базы готовое состояние агрегата UserAR (AR = Aggregate Root), он выбирает из базы все события которые ассоциируются с этим юзером, и потом воспроизводит их по порядку передавая в метод On() агрегата.
Например у класса агрегата UserAR должен быть следующий метод, для того чтобы восстановить в состоянии пользователя его ID
protected void On(User_CreatedEvent created) { _id = created.UserId; }
Из всего состояния агрегата мне нужна только _id юзера, так же я мог бы восстановить состояние пароля, имени и т.д. Однако эти поля могут быть модифицированы и другими событиями, не только User_CreatedEvent соответственно мне нужно будет обработать их все. Так как все события воспроизводятся по порядку, я уверен, что всегда работаю с последним актуальным состоянием агрегата, если я конечно написал обработчики On() для всех событий которые это состояние изменяют.
Давайте рассмотрим на примере создания пользователя как работает CQRS + Event Sourcing.
Создание и отправка команды
Первое что я сделаю — это сформирую и отправлю команду. Для простоты пусть команда создания юзера имеет только самый необходимый набор полей и выглядит следующим образом.
public class User_CreateCommand: Command { public string UserId { get; set; } public string Password { get; set; } public string Email { get; set; } }
Пусть вас не смущает имя класса команды, оно не соответствует общепринятым гайдлайнсам, но позволяет сразу понять к какому агрегату она относится, и какое действие выполняется.
var command = new User_CreateCommand { UserId = “1”, Password = “password”, Email = “test@test.com”, }; command.Metadata.UserId = command.UserId; _commandService.Send(command);
Затем мне нужен обработчик этой команды. Обработчику команды обязательно нужно передать ID нужного агрегата, по этому ID он получит агрегат из репозитория. Репозиторий строит объект агрегата следующим образом: берет из базы все события которые относятся к этому агрегату, создает новый пустой объект агрегата, и по порядку воспроизведет полученные события на объекте агрегата.
Но так как у нас команды создания — поднимать из базы нечего, значит создаем агрегат сами и передаем ему метаданные команды.
public class User_CreateCommandHandler: CommandHandler<User_CreateCommand> { public override void Handle(User_CreateCommand message) { var ar = new UserAR(message.UserId, message.Email, message.Password, message.Metadata); Repository.Save(ar); } }
Посмотрим как выглядит конструктор агрегата.
public UserAR(string userId, string email, string password, ICommandMetadata metadata): this() { _id = userId; SetCommandMetadata(metadata); Apply(new User_CreatedEvent { UserId = userId, Password = password, Email = email }); }
Так же у агрегата обязательно должен быть конструктор без параметров, так как когда репозиторий воспроизводит состояние агрегата, ему надо сначала создать путой экземпляр, а затем передавать события в методы проекции (метод On(User_CreatedEvent created) является одним из методов проекции).
Немного уточню на счет проекции. Проекция — это воспроизведение состояния агрегата, на основе событий из Event Store, которые относятся к этом агрегату. В примере с пользователем — это все события для данного конкретного пользователя. А агрегате все те же события которые сохраняются через метод Apply, можно обработать во время воспроизведения его состояния. В нашем фреймворке для это достаточно написать метод On(/*EventType arg*/), где EventType — тип события которое вы хотите обработать.
Метод Apply агрегата инициирует отправку событий всем обработчикам. На самом деле события будут отправлены только при сохранение агрегата в репозиторий, а Apply просто добавляет их во внутренний список агрегата.
Вот обработчик события(!) создания пользователя, который записывает в read базу собственно самого пользователя.
public void Handle(User_CreatedEvent message) { var doc = new UserDocument { Id = message.UserId, Email = message.Email, Password = message.Password }; _users.Save(doc); }
У события может быть несколько обработчиков. Такая архитектура помогает сохранять целостность данных, если ваши данные сильно денормализированы. Допустим мне надо часто показывать общее количество пользователей. Но у меня их слишком много и операция count по всем очень затратна для моей БД. Тогда я могу написать еще один обработчик события, который будет уже относится к статистике и каждый раз при добавлении пользователя будет увеличивать общий счетчик пользователей на 1. И я буду уверен, что никто не создаст пользователя, не обновив при этом счетчик. Если бы я не использовал CQRS, а была бы у меня обычная ORM, пришлось бы следить в каждом месте где добавляется и удаляется пользовать чтоб обновился и счетчик.
А использование Event Sourcing’а даёт мне дополнительные приемущеста. Даже если я ошибся в каком-то EventHandler’е или не обработал событие везде где мне это надо, я могу легко это исправать просто перегенировав read базу с уже правильной бизнесс логикой.
С созданием понятно. Как происходит изменение агрегата и валидация команды? Рассмотрим пример со сменой пароля.
Я приведу только command handler и метод агрегата ChangePassword(), так как в остальных местах разница в общем не большая.
Command Handler
public class User_ChangePasswordCommandHandler: IMessageHandler<User_ChangePasswordCommand> { // Конструктор опущен public void Handle(User_ChangePasswordCommand message) { // берем из репозитория агрегат var user = _repository.GetById<UserAR>(message.UserId); // выставляем метаданные user.SetCommandMetadata(message.Metadata); // меняем пароль user.ChangePassword(message.OldPassword, message.NewPassword); // сохраняем агрегат _repository.Save(user); } }
Aggregate Root
public class UserAR : BaseAR { //... public void ChangePassword(string oldPassword, string newPassword) { // Если пароль не совпадает со старым, кидаем ошибку if (_password != oldPassword) { throw new AuthenticationException(); } // Если все ОК - принимаем ивент Apply(new User_Password_ChangedEvent { UserId = _id, NewPassword = newPassword, OldPassword = oldPassword }); } // Метод проекции для восстановления состояния пароля protected void On(User_Password_ChangedEvent passwordChanged) { _password = passwordChanged.NewPassword; } // Так же добавляем восстановления состояния пароля на событие создания пользователя protected void On(User_CreatedEvent created) { _id = created.UserId; _password = created.Password; } } }
Хочу заметить что очень не желательно чтобы невалидное событие было передано в метод Apply(). Конечно вы сможете его обработать потом в event handler’е, но лучше вообще его не сохранять, если оно вам не важно, так как это только засорит Event Store.
В случае со сменой пароля вообще нет никакого смысла сохранять это событие, если вы конечно не собираете статистку по неудачным сменам пароля. И даже в этом случае следует хорошенько подумать, ножно ли это событие вам во write модели или есть смысл записать его в какое-нибудь темповое хранилище. Если вы предполагаете что бизнес логика валидации события может измениться то тогда сохраняйте его.
Вот собственно и все о чем я хотел рассказать в этой статье. Конечно она не раскрывает все аспекты и возможности CQRS + Event Sourcing, об этом я планирую рассказать в следующих статьях. Так же остались за кадром проблемы которые возникают при использовании данного подхода. И об этом мы тоже поговорим.
Если у вас есть какие-то вопросы, задавайте их в комментариях. С радостью на них отвечу. Так же если есть какие-то предложения по следующим статьям — очень хочется их услышать.
Sources
Полностью рабочий пример на ASP.NET MVC находится здесь.
Базы данных там нету, все храниться в памяти. При желании её достаточно просто прикрутить. Так же из коробки есть готовая реализация Event Store на MongoDB для хранения ивентов.
Чтобы её прикрутить достаточно в Global.asax файле заменить InMemoryTransitionRepository на MongoTransitionRepository.
В качестве read модели у меня статическая коллекция, так что при каждом перезапуске данные уничтожаются.
What's Next?
У меня есть несколько идей на счет статей по данной тематике. Предлагайте еще. Говорите что наиболее интересно.
- Что такое Snapshot’ы, зачем нужны, детали и варианты реализации.
- Event Store.
- Регенерация базы данных. Возможности. Проблемы, производительность. Распараллеливание. Патчи.
- Дизайн Aggregate Root’ов.
- Применение на реальных проектах. Один проект на аутсорсинге, второй — мой стартап.
- Особенности интеграции сторонних сервисов.
