Это достаточно вольный перевод статьи. Дело в том, что несмотря на конструкции в одну строчку, материал сложен для понимания.
Беря во внимание то, что в комментариях Прелюдия или как полюбить Haskell просили, чтобы код был понятный, я внёс достаточно ремарок, и, надеюсь, код будет понятен и тем, кто далёк от Хаскеля.
Давайте начнём с самого трудного — с самого заголовка: многим непонятны все его слова.
Хаскель — это чистый и ленивый функциональный язык.
Лёб — это немецкий математик, о котором мы поговорим чуть позже.
Ну, и наконец, самое интересное — странные петли.
Странные петли — это запутанные категории, когда двигаясь вверх или вниз в иерархической системе, находишь то же самое, откуда начал движение.
Зачастую такие петли содержат само-референтные ссылки.
Например, подобной странной петлёй обладает рекурсивные акронимы: «PHP — PHP: Hypertext Preprocessor».
Ну, и на сегодняшний день наиболее загадочным словом, содержащим странные петли, является понятие «я».
Странные петли будоражат людей своей красотой. И очень приятно, когда находишь их в самых неожиданных местах. Очень интересные функции со странными петлями можно написать на Хаскеле.
Немецкий математик Лёб мигрировал в 39-м году ХХ-го столетия в Великобританию. Лёб, в частности, развивал математическую логику и миру прежде всего известен Теоремой Лёба. Это теорема развивала труды Гёделя о неполноте математики. Теорема Лёба о взаимосвязи между доказуемостью утверждения и самим утверждением, она гласит, что
во всякой теории, включающей аксиоматику Пеано (аксиоматика о натуральных числах), для любого высказывания
Всю эту сложность высказывания можно записать символически:

Можно ли такую функцию написать на Хаскеле?! Можно! И всего в одну строчку!
Беря во внимание то, что в комментариях Прелюдия или как полюбить Haskell просили, чтобы код был понятный, я внёс достаточно ремарок, и, надеюсь, код будет понятен и тем, кто далёк от Хаскеля.
Давайте начнём с самого трудного — с самого заголовка: многим непонятны все его слова.
Хаскель — это чистый и ленивый функциональный язык.
Лёб — это немецкий математик, о котором мы поговорим чуть позже.
Ну, и наконец, самое интересное — странные петли.
Странные петли — это запутанные категории, когда двигаясь вверх или вниз в иерархической системе, находишь то же самое, откуда начал движение.
Зачастую такие петли содержат само-референтные ссылки.
Например, подобной странной петлёй обладает рекурсивные акронимы: «PHP — PHP: Hypertext Preprocessor».
Ну, и на сегодняшний день наиболее загадочным словом, содержащим странные петли, является понятие «я».
Странные петли будоражат людей своей красотой. И очень приятно, когда находишь их в самых неожиданных местах. Очень интересные функции со странными петлями можно написать на Хаскеле.
Немецкий математик Лёб мигрировал в 39-м году ХХ-го столетия в Великобританию. Лёб, в частности, развивал математическую логику и миру прежде всего известен Теоремой Лёба. Это теорема развивала труды Гёделя о неполноте математики. Теорема Лёба о взаимосвязи между доказуемостью утверждения и самим утверждением, она гласит, что
во всякой теории, включающей аксиоматику Пеано (аксиоматика о натуральных числах), для любого высказывания
P доказуемость высказывания «если доказуемо P, тогда P истинно» возможна только в случае доказуемости самого высказывания P.Всю эту сложность высказывания можно записать символически:
Можно ли такую функцию написать на Хаскеле?! Можно! И всего в одну строчку!





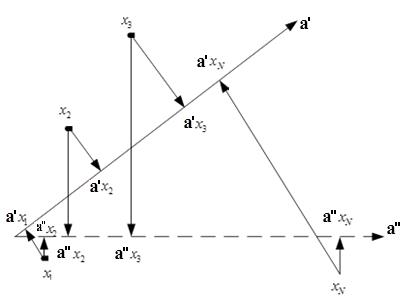
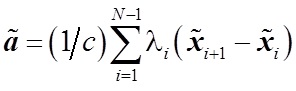 , где
, где 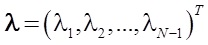 — решение стандартной задачи квадратичного программирования при линейных ограничениях:
— решение стандартной задачи квадратичного программирования при линейных ограничениях: 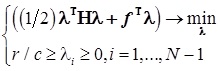 , где
, где 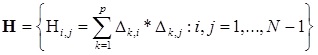 — симметричная матрица
— симметричная матрица  — вектор коэффициента
— вектор коэффициента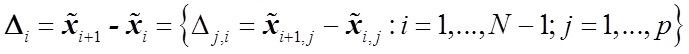 — разница векторов характеристик
— разница векторов характеристик

 Недавно я наткнулся на такую удивительную штуку как число Данбара.
Недавно я наткнулся на такую удивительную штуку как число Данбара.