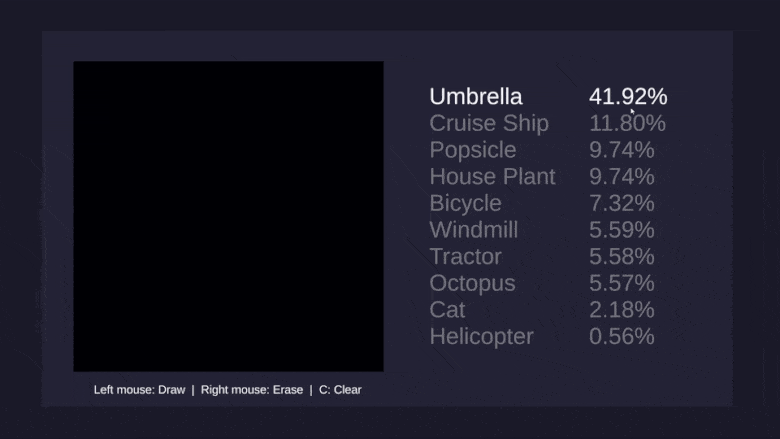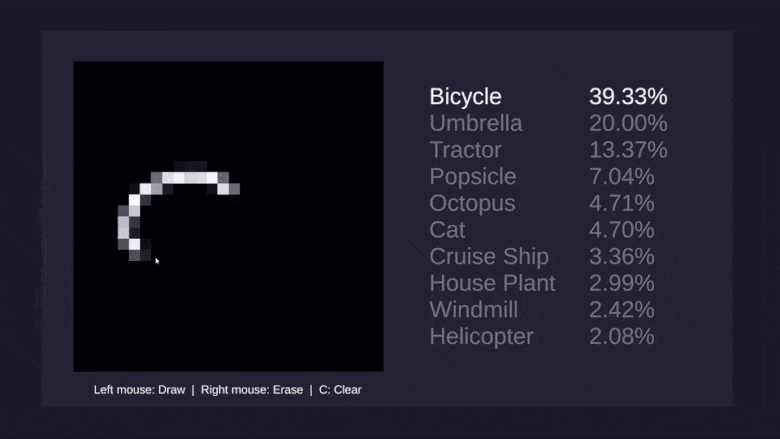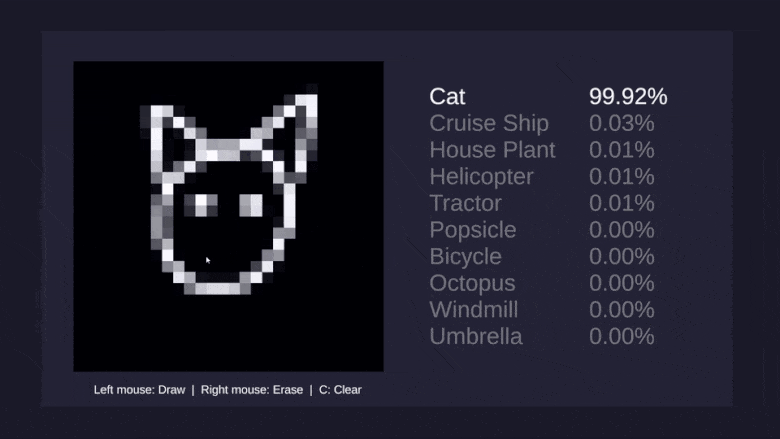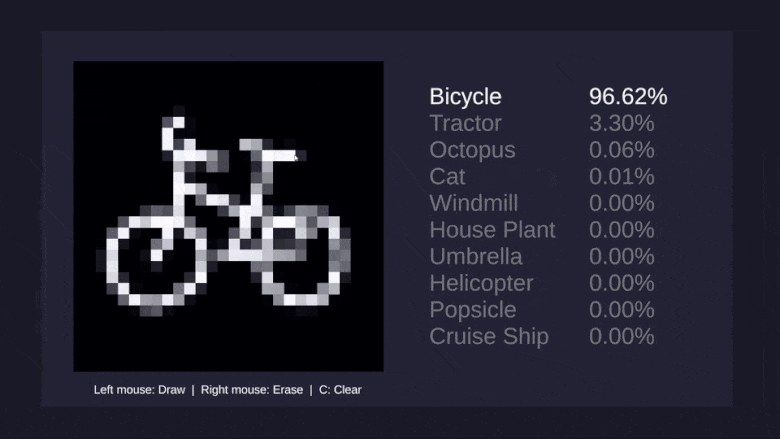
Думаю, большинству читателей доводилось хотя бы мельком видеть фотографию этой девушки, и многие припоминают, что модель зовут Лена. Я впервые столкнулся с этим снимком в лаборатории Антона Савельева в СПИИРАН, нынешнем СПБ ФИЦ РАН, где работал условным «техническим писателем и литературным редактором англ.-рус.», помогая ребятам готовить статьи на конференции, заявки на гранты и перемалывать прочий контент, требовавший внятной подачи по-английски или по-русски. Несколько позже, уже на Хабре, у меня завязалось виртуальное, а впоследствии и реальное знакомство с @Loriowar. Рассказывая о своём становлении в профессии, он, в частности, написал:
«В программинг пришёл просто: на лабе по цифровой обработке сигналов в очередной раз безжалостно издевался над Леной (https://en.wikipedia.org/wiki/Lenna), жал её по-всякому и прочие непотребства совершал. Естественно, не забывая в красках описывал это в отчёте, который никто не просил делать. За это и позвали биллинг пилить на руби, ибо препод был генеральным директором компании».
Это Лена Сёдерберг, шведка (род. 1951), заглавное фото которой появилось на обложке ноябрьского номера "Playboy" за 1972 год. Также на центральном развороте этого журнала она изображена в гораздо более откровенном образе. Всемирную известность получила верхняя часть центрального снимка (512 x 512 пикселей). Считается, что именно эта картинка была первым изображением, переданным с компьютера на компьютер в сети ARPANET. Со временем лицо Лены превратилось в эталонный образец для компьютерной обработки изображений.