
Дообучение 7-миллиардной модели Saiga2 под свои задачи, используя сгенерированный датасет с помощью GPT. В данной статье есть все необходимые ссылки и код для предобработки и запуска обучения модели, а также квантования модели.

Аналитик данных
Дообучение 7-миллиардной модели Saiga2 под свои задачи, используя сгенерированный датасет с помощью GPT. В данной статье есть все необходимые ссылки и код для предобработки и запуска обучения модели, а также квантования модели.

Добрый день, уважаемые читатели и авторы Хабра!
Сегодня я рад представить вам подробное руководство по обучению модели ruGPT-3.5 13B с использованием датасетов модели Saiga-2/GigaSaiga, технологии Peft/LoRA и технологии GGML. Эта статья призвана стать полезным и практичным ресурсом для всех, кто интересуется машинным обучением, искусственным интеллектом и глубоким обучением, а также для тех, кто стремится глубже понять и освоить процесс обучения одной из самых мощных и перспективных русскоязычных моделей.
В данной публикации мы разберем каждый этап обучения модели, начиная от подготовки данных и заканчивая конвертацией в формат GGML. Буду рад, если мой опыт и знания помогут вам в вашем исследовании и экспериментах в этой захватывающей области!

Используя технику Retrieval-Augmented Generation ("Поисковая расширенная генерация"), мы настроим русскоязычного бота, который будет отвечать на вопросы потенциальных работников для выдуманного свечного завода в городе Градск.
Retrieval Augmented generation - генерация ответа с использованием результатов поиска. RAG-архитектура - это подход к созданию приложений, в которых большая языковая модель без дополнительного обучения отвечает на вопросы с использованием информации из внутренней базы знаний или документов компании. Я не описываю архитектуру, так как уже существует множество статей на эту тему (langchain, habr).
В этом году мы начали создавать RAG-систему для техподдержки клиентов в виде чат-бота. Бот парсит документацию/инструкции и отвечает на обращения пользователей в чате или по почте, как специалист первой линии поддержки. Сейчас она ежедневно обрабатывает 1000+ запросов и ей пользуются 10+ компаний. Создать RAG может даже школьник, однако внедрить её в реальный бизнес - совершенно другая история.
Бизнес пользователи будут жаловаться, что система отвечает слишком расплывчато, или слишком коротко, или до конца не понимает суть вопроса. Пользователи сервиса могут задавать очень длинные вопросы (больше 1000 символов), уточняющие вопросы, два-три вопроса в одном сообщении и ещё множество других вариаций.
Да, на простые вопросы ответит любая RAG-система, но если вы не сможете предоставить бизнесу четкие правила и инструменты обработки сложных кейсов, то ваш статистический попугай скоро всех разочарует.
В статье представлена инструкция по настройке бота, которую мы даем нашим клиентам. Эта инструкция будет полезна специалистам поддержки и разработчикам подобных систем. Я убрал из статьи все упоминания продукта, но не стал сильно менять текст, чтобы вы могли использовать статью для создания своих инструкций.

Этот материал посвящён тому, как добавлять собственные данные в предварительно обученные LLM (Large Language Model, большая языковая модель) с применением подхода, основанного на промптах, который называется RAG (Retrieval‑Augmented Generation, генерация ответа с использованием результатов поиска).
Большие языковые модели знают о мире многое, но не всё. Так как обучение таких моделей занимает много времени, данные, использованные в последнем сеансе их обучения, могут оказаться достаточно старыми. И хотя LLM знакомы с общеизвестными фактами, сведения о которых имеются в интернете, они ничего не знают о ваших собственных данных. А это — часто именно те данные, которые нужны в вашем приложении, основанном на технологиях искусственного интеллекта. Поэтому неудивительно то, что уже довольно давно и учёные, и разработчики ИИ‑систем уделяют серьёзное внимание вопросу расширения LLM новыми данными.
До наступления эры LLM модели часто дополняли новыми данными, просто проводя их дообучение. Но теперь, когда используемые модели стали гораздо масштабнее, когда обучать их стали на гораздо больших объёмах данных, дообучение моделей подходит лишь для совсем немногих сценариев их использования. Дообучение особенно хорошо подходит для тех случаев, когда нужно сделать так, чтобы модель взаимодействовала бы с пользователем, используя стиль и тональность высказываний, отличающиеся от изначальных. Один из отличных примеров успешного применения дообучения — это когда компания OpenAI доработала свои старые модели GPT-3.5, превратив их в модели GPT-3.5-turbo (ChatGPT). Первая группа моделей была нацелена на завершение предложений, а вторая — на общение с пользователем в чате. Если модели, завершающей предложения, передавали промпт наподобие «Можешь рассказать мне о палатках для холодной погоды», она могла выдать ответ, расширяющий этот промпт: «и о любом другом походном снаряжении для холодной погоды?». А модель, ориентированная на общение в чате, отреагировала бы на подобный промпт чем‑то вроде такого ответа: «Конечно! Они придуманы так, чтобы выдерживать низкие температуры, сильный ветер и снег благодаря…». В данном случае цель компании OpenAI была не в том, чтобы расширить информацию, доступную модели, а в том, чтобы изменить способ её общения с пользователями. В таких случаях дообучение способно буквально творить чудеса!

Краткое и понятное описание подхода RAG (Retrieval Augmented Generation) при работе с большими языковыми моделями.

В сети в последнее время регулярно мелькают статьи типа - как обучить Stable Diffusion генерировать ваши фотографии/фотографии в определенном стиле/фотографии определенного лора/такие фотографии итп.
Однако к сожалению, даже на хабре, об этой технологии рассказывают супер-поверхностно - как скачать какую-то GUI программу, и куда тыкать кнопочки. Поэтому я решил исправить это недоразумение, и выпустить первую статьи на русском, где полностью рассказывается что по настоящему стоит за этими 4-мя буквами.

Одним прекрасным вечером коллега попросил подумать над алгоритмом поворота серийных номеров на металлических брусках. Но глобально задача предполагала именно распознавание номеров. Казалось бы, современные коробочные решения должны легко решить нашу задачу. О том, что было на самом деле, и пойдет речь в этой статье.

Привет, Habr! Меня зовут Оля Плюта, я продуктовый аналитик маркетплейса Uzum Market. В этой статье я расскажу об иерархических деревьях ltree в PostgreSQL. Статья вводная, поэтому я постаралась сделать её максимально понятной и наглядной.

Александр Ледовский, тимлид команды аналитики и DS в Авито, рассказал про опыт работы с Apache Spark и о том, как правильно задавать параметры Spark-сессии, чтобы получить ресурсы.

Меня зовут Александр Брыль, я дата-саентист в команде NLP СберМегаМаркета и сегодня хочу рассказать, как мы искали быстрое и удобное решение для исправления ошибок в поисковых запросах маркетплейса: зачем нам это понадобилось, как мы сравнивали автокорректоры Яндекс.Спеллер, корректор от DeepPavlov, SymSpell и на чем в итоге решили остановиться.
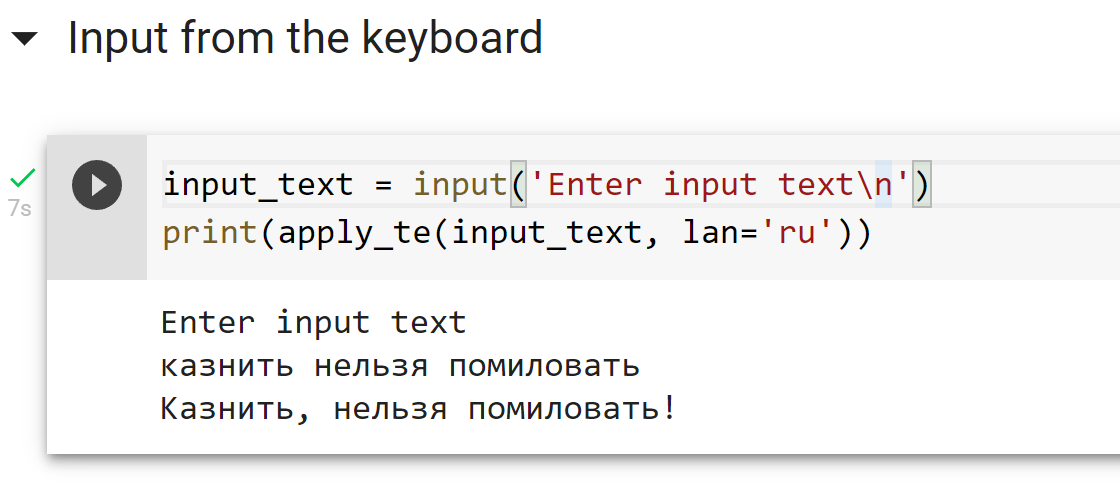

При разработке систем распознавания речи мы сталкиваемся с заблуждениями среди потребителей и разработчиков, в первую очередь связанными с разделением формы и сути. Одним из таких заблуждений является то, что в устной речи якобы "можно услышать" грамматически верные знаки препинания и пробелы между словами, когда по факту реальная устная речь и грамотная письменная речь очень сильно отличаются (устная речь скорее похожа на "поток" слегка разделенный паузами и интонацией, поэтому люди так не любят монотонно бубнящих докладчиков).
Понятно, что можно просто начинать каждое высказывание с большой буквы и ставить точку в конце. Но хотелось бы иметь какое-то относительно простое и универсальное средство расстановки знаков препинания и заглавных букв в предложениях, которые генерирует наша система распознавания речи. Совсем хорошо бы было, если бы такая система в принципе работала с любыми текстами.
По этой причине мы бы хотели поделиться с сообществом системой, которая:
На всякий случай явно повторюсь — цель такой системы — лишь улучшать читабельность текста. Она не добавляет в текст информации, которой в нем изначально не было.

Всем привет, меня зовут Владислав Соболев – ML-инженер в компании “БАРС Груп”. Сегодня я хотел бы рассказать о том, зачем и как мы расставляем знаки препинания в текстах, сравним аналоги, и посмотрим на то, как устроена работа инструмента, который мы написали, чтобы обучать такого рода модели (ссылочка в самом конце). Начнем!
У нас в компании есть ряд ML-проектов, внутри которых используется анализ текста, в том числе и надиктованного голосом. Мы командой долго думали над тем, как можно реализовать данные проекты.
В итоге пришли к выводу, что проще всего для наших целей проводить лингвистический анализ текста искать в нём слова-действия, такие как "сгруппируй", "покажи", определять связи и зависимости между словами, искать ключевые слова, ранжировать их. И на основе всех этих данных – взаимодействовать с сервисами.
Меня зовут Николай, когда в 2009 году я защищал диссертацию по распознаванию речи, скептики мне говорили, что слишком поздно, так как Microsoft и Google уже “всё сделали”. Сейчас в SberDevices я обучаю модели распознавания речи, которые используются в семействе виртуальных ассистентов Салют и других банковских сервисах. Я расскажу, как обучил модель распознавания речи, используя Common Voice и недавно открытый датасет Golos. Ошибка распознавания составила от 3 до 11 % в зависимости от типа тестовой выборки, что очень неплохо для открытой модели.
Не так давно наша команда подготовила и опубликовала общедоступный датасет Golos. Почему встал вопрос об обучении и публикации акустической модели QuartzNet? Во-первых, чтобы узнать, какую точность достигает система распознавания речи при обучении на новом датасете. Во-вторых, обучение само по себе ресурсоёмкое, поэтому сообществу полезно иметь в открытом доступе предобученную модель на русском языке. Полная версия статьи опубликована на сайте arxiv.org и будет представлена на конференции INTERSPEECH2021.

Как-как, с помощью магии нейронок, конечно. А если серьёзно, то в этой статье расскажем, как эволюционировали технологии шумоподавления и улучшения речи, какие есть варианты, чтобы собрать своё решение, и какой сетап получился у нас.

Автоматическое распознавание речи (STT или ASR) прошло долгий путь совершенствования и имеет довольно обширную историю. Расхожим мнением является то, что лишь огромные корпорации способны на создание более-менее работающих "общих" решений, которые будут показывать вменяемые метрики качества вне зависимости от источника данных (разные голоса, акценты, домены). Вот несколько основных причин данного заблуждения:
В данной статье мы развеем некоторые заблуждения и попробуем немного приблизить точку "сингулярности" для распознавания речи. А именно:
В этой статье есть 3 основных блока — критика литературы и доступных инструментов, паттерны для проектирования своих решений и результаты нашей модели.
На сегодня существует большое количество алгоритмов машинного обучения для обработки различного типа данных, таких как табличные данные, изображения, текст, аудио файлы. Как раз о последнем типе пойдёт речь в данной работе, потому как аудио файлы являются одной из распространенных форм хранения данных в организациях, тщательный анализ которых может являться ключевым фактором к развитию не только коммерческих продуктов, но и опенсорсных решений. В то же время именно методы работы со звуком менее всего популярны, особенно в русскоязычном сегменте, но об этом далее.

Есть ряд платных решений по переводу речи в текст (Automatic Speech Recognition). Сравнительно малыми усилиями можно сделать свое решение, — обучить на целевых данных end2end модель (например, из фреймворка NeMo от NVIDIA) или гибридную модель типа kaldi. Сверху понадобится добавить расстановку пунктуации и денормализацию для улучшения читаемости ("где мои семнадцать лет" → "Где мои 17 лет?").
Модель заслуживает внимания так как умеет делать очень много "из коробки". Давайте разберемся подробнее как она устроена и научимся ей пользоваться.
Недавно в открытый доступ была выложена мультиязычная модель whisper от OpenAI. Попробовал ее large вариант на нескольких языках и расшифровал 30 выпусков "Своей игры". Результат понравился, но есть нюансы. Модель транскрибирует тексты вместе с пунктуацией и капитализацией, расставляет временные метки, умеет генерировать субтитры и определять язык. Языков в обучающем датасете порядка ста. Чтобы прикинуть по качеству, нужно посмотреть на их распределение — данных на 100 часов и более было лишь для 30 языков, более 1000 ч. — для 16, ~10 000 часов — у 5 языков, включая русский.

В основе систем распознавания речи стоит скрытая марковская модель, суть модели заключается в том, что при рассмотрении сигнала в промежутке небольшой длительности (от пяти до 10 миллисекунд), возможна его аппроксимация как при стационарном процессе.
Если простыми словами скрытую марковскую модель можно объяснить на примере.
