С момента анонса закрытия Google Reader на хабре появился уже ряд статей о других сервисах, на которые можно уйти.
Во всём этом меня смущает то, что это же не Вконтакт, не твиттер, а хабра, почему я здесь читаю только о сторонних сервисах?
Кто мешает сделать свой RSS Reader с преферансом и мадмуазелями?

Под катом немного моих соображений о том, что можно сделать самому для себя. Приветствуется ваш опыт и соображения в комментариях.
Во всём этом меня смущает то, что это же не Вконтакт, не твиттер, а хабра, почему я здесь читаю только о сторонних сервисах?
Кто мешает сделать свой RSS Reader с преферансом и мадмуазелями?
Под катом немного моих соображений о том, что можно сделать самому для себя. Приветствуется ваш опыт и соображения в комментариях.




 Это перевод
Это перевод 



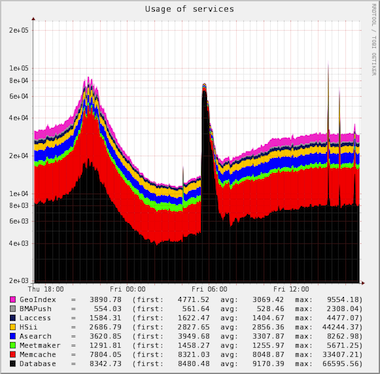 Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…
Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…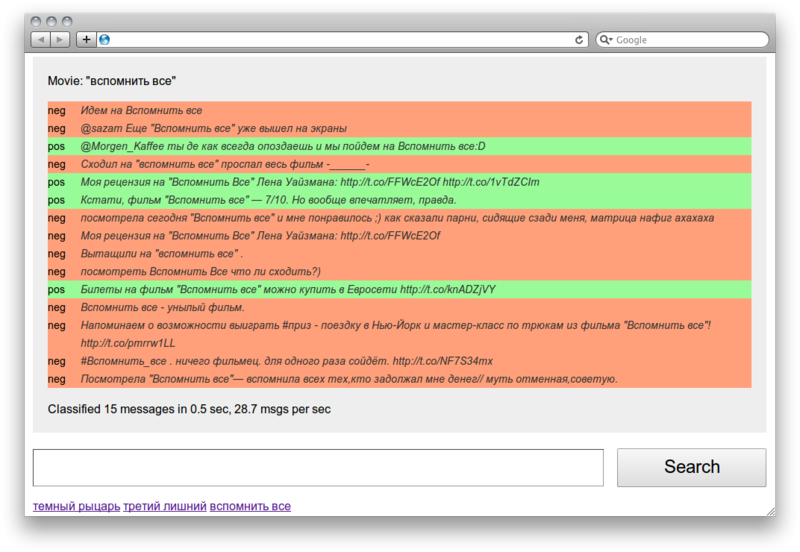


 Это шестая, заключительная часть из серии Hg Init: Учебное пособие по Mercurial от Джоэля Спольски (
Это шестая, заключительная часть из серии Hg Init: Учебное пособие по Mercurial от Джоэля Спольски (